하둡과 Yarn 및 클러스터에 관해 구글링을 하던 중 유용한 wikidocs가 있어서 리뷰를 진행하였습니다. 해당 wikidocs의 주소는 아래와 같습니다. https://wikidocs.net/book/2203 빅데이터 - 하둡, 하이브로 시작하기 이 책은 하둡을 처음 시작하는 사람들을 대상으로 작성하였습니다. **하둡**은 빅데이터 기술의 시작점입니다. 하둡이 맵리듀스와 HDFS 기술을 소개하면서 빅데이터를 ... wikidocs.net 빅데이터에 수집, 정제, 적재, 분석, 시각화의 여러 단계에 관해서 관련 프레임워크나 오픈소스를 잘 설명하고 있으며 하둡과 Yarn에 대해 많은 정보를 얻어서 유익하였습니다. 빅데이터 에코시스템에 관해서 관련 기술과 특징들에 대해 전반적인 구조를 알 수 있으며 하둡과..

AWS에서 애플리케이션 EC2, EMR, Athena 등 AWS 관련해서 데이터 엔지니어 업무를 수행하고 있는데 운영을 하는 데 있어서 구축 과정과 실제로 경험을 해보고자 책을 읽게 되었습니다. 클라우드에 대해 더 자세하게 알 수 있으며 특히 AWS의 다양한 서비스를 실습을 통해 할 수 있다는 점이 좋았고 요금 관련해서 자세하게 설명이 되어있어서 부담을 가질 필요가 없었습니다. AWS CCP 준비를 할때 백서와 함께 읽었는데 많은 도움이 되었던 거 같습니다. 각 용어의 정의와 개념에 대해 이해하기 편했고 클라우드나 인프라적인 측면에서 스킬업이 많이 되었습니다. AWS에서 서버를 구축해서 다양한 서비스의 기초를 익히는데 도움이 되었던거 같습니다. 책을 읽으면서 이 책을 읽게 된 이유가 너무 와닿았던 에필로..

최근에 클라우드가 부상하면서 도커와 쿠버네티스에 대한 수요가 증가하여 호기심이 생겼고 데이터엔지니어 업무르 하는데 있어서 인프라 기초 지식이 필요로 하여 책을 읽게 되었습니다. - 시스템과 인프라의 기초 지식, 클라우드와 온프레미스의 차이점이 무엇인지 특징들은 무엇인지, 컨테이너 기술과 운용 관리하는 법에 대해, 도커를 직접 실습을 하면서 산출물을 확인할 수 있는게 매력적이였습니다. - Docker 환경에서 동일 호스트상에 Docker를 설치하고, 그 위에서 몇 개의 컨테이너를 가동시켜 서버를 작동, 이미지의 작성이나 컨테이너의 시작 등은 호스트 머신에 설치된 Docker가 수행하고, 여러 개의 Docker를 일원 관리할 때는 Docker Compose를 사용하여 애플리케이션의 실행 환경을 구축하면서 도..

스파크를 공부하면서 스파크 완벽 가이드를 본격적으로 읽기 전에 실무에서 도움이 되는 책을 고민하다가 스파크를 다루는 기술을 사서 읽었다. - 아파치 스파크에서부터 스파크의 기초, 스파크 애플리케이션, 스파크 API, 스파크 SQL, 스파크 스트리밍, 스파크 ML,DL,GraphX, 스파크옵스, 스파크 클러스터, YARN 클러스터, 메소스 클러스터 등 스파크에 관한 전반적인 개념과 원리에 대해 배울 수 있어서 좋았고 각 장마다 실습코드가 있어서 많은 도움이 되었던거 같았다 - 실무에서 쓰던 YARN 클러스터나, 스파크 SQL, 배치에 대해서 전체적인 틀을 잡아줘서 좋았고 앞으로의 공부 방향에 대해 다듬을 수 있어서 좋았다. - 이 책은 다양한 스파크 기능에 대한 유용한 지식을 전달하고 있으며 코드 설명을 ..

데이터 엔지니어링 공부를 하면서 빅데이터에 대해 전반적인 구조를 익힐 수 있는 기술서로 추천하고 싶은 책이다. - 데이터 분석가가 데이터에서 가치 있는 정보를 추출한다면 데이터 엔지니어는 시스템의 구축 및 운용, 자동화 등을 담당한다. 이 책에서 다루는 것은 데이터 활용 방법이 아니라 데이터 처리를 어떻게 시스템화하는가에 대한 문제로 데이터 처리과정에서 사용되는 소프트웨어와 데이터베이스, 프로그래밍 언어와 시각화 도구 등의 특징을 정리하여 데이터를 효율 높게 취급하기 위한 기초를 먼저 설명하고 워크플로우 관리와 스트림 처리 등의 데이터 처리 기술을 자세히 알려주고 있다. - 데이터 엔지니어 업무를 수행하면서 빅데이터의 기초 지식에 대해 많이 구글링을 하고 있습니다. 데이터 수집 시 데이터 전송 방식에 대..

2021년 1년 차 주니어 데이터 사이언티스트로 성장하기까지 있었던 일들을 정리하는 글입니다. 제 자신을 돌아보는 글이자 새롭게 시작하는 주니어들에게 도움을 주고자 적는 글입니다. 현재는 데이터 엔지니어링을 공부하면서 역량을 키우고 준비하고 있습니다. 1. 첫취업까지 교육 수료 취업을 하기 전까지 응용통계가 기본 base에 python 및 데이터 분석과 ML, DL을 독한은 2018년부터 했습니다. 단순히 데이터 경진대회를 참가하기 위해서 데이터 크롤링을 시작하면서 python에 흥미를 느껴 하나씩 공부했던 거 같습니다. 전공과목은 적성에 잘 맞았고 통계가 재밌어서 막 학기까지는 다른 준비 없이 그저 강의만 보고 운동만 했던 거 같습니다. 막 학기가 끝나고 취업에 대한 고민과 함께 유예를 시작하면서 진로..
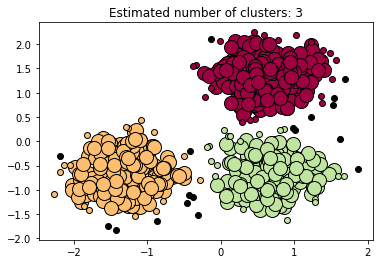
Clustering 비지도 군집분석 중 MeanShift와 DBSCAN에 대해 정리하고자 합니다. MeanShift는 특이한 형태를 지니는 data를 클러스터링 하기에는 한계가 존재하여 이러한 경우 DBSCAN을 사용하는 것으로 알고 있습니다. 해당 코드는 Sklearn 공홈을 참고하였으며 알고리즘의 공식 같은 경우에는 V-Measure: A conditional entropy-based external cluster evaluation measure 논문을 참고하였습니다. Mean-Shift 클러스터링 - KDE를 이용하여 개별 데이터 포인트들이 데이터 분포가 높은 곳으로 이동하면서 군집화를 수행하는 모델 - 사전에 군집화 개수를 지정하지 않으며 데이터 분포도에 기반해 자동으로 군집화 개수를 정하게 됨..
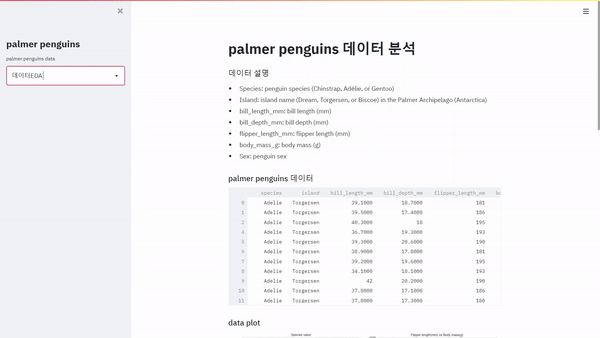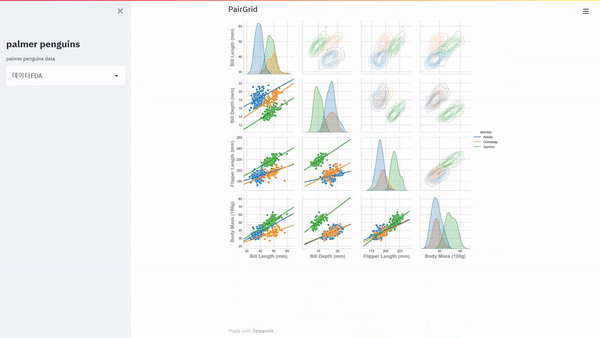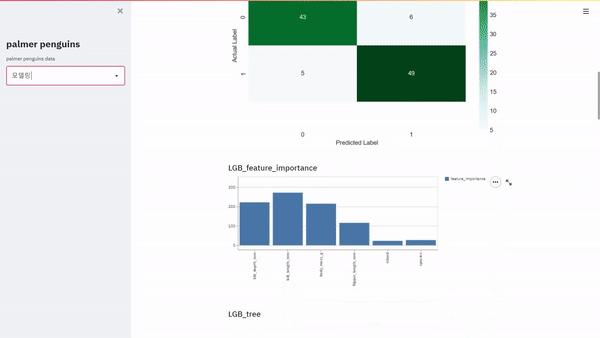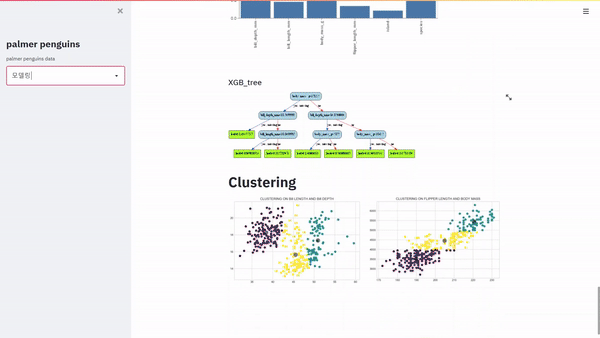
웹에서 대시보드를 개발하려고 합니다. 거창하게 개발이라고 말을 하였지만 엄연히 보면 구현에 가까울 거 같습니다. Python을 활용하여 대시보드를 만드는데 있어서 다양한 방법이 있겠지만 크게 Dash와 Streamlit에 관해 설명하려고 합니다. Dash의 경우 저번 포스팅에 설명을 하였고 실제로 웹에서 배포도 하여 이번에는 Streamlit를 이용하여 웹에서 배포를 해보았습니다. 대시보드 고도화를 위해서는 공홈에서 공부를 하면 좋을 거 같습니다. https://docs.streamlit.io/en/stable/getting_started.html Get started — Streamlit 0.84.2 documentation The easiest way to learn how to use Streaml..