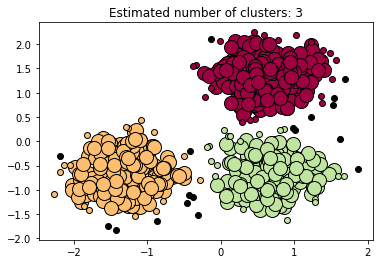
Clustering 비지도 군집분석 중 MeanShift와 DBSCAN에 대해 정리하고자 합니다. MeanShift는 특이한 형태를 지니는 data를 클러스터링 하기에는 한계가 존재하여 이러한 경우 DBSCAN을 사용하는 것으로 알고 있습니다. 해당 코드는 Sklearn 공홈을 참고하였으며 알고리즘의 공식 같은 경우에는 V-Measure: A conditional entropy-based external cluster evaluation measure 논문을 참고하였습니다. Mean-Shift 클러스터링 - KDE를 이용하여 개별 데이터 포인트들이 데이터 분포가 높은 곳으로 이동하면서 군집화를 수행하는 모델 - 사전에 군집화 개수를 지정하지 않으며 데이터 분포도에 기반해 자동으로 군집화 개수를 정하게 됨..
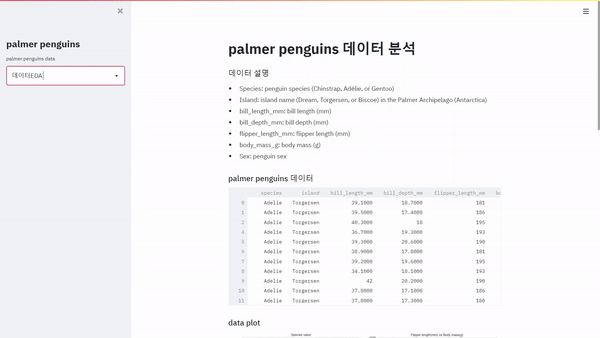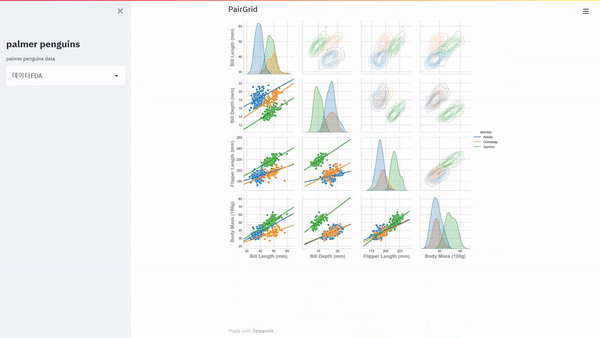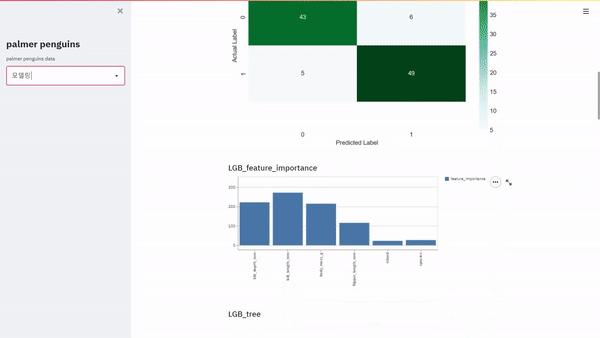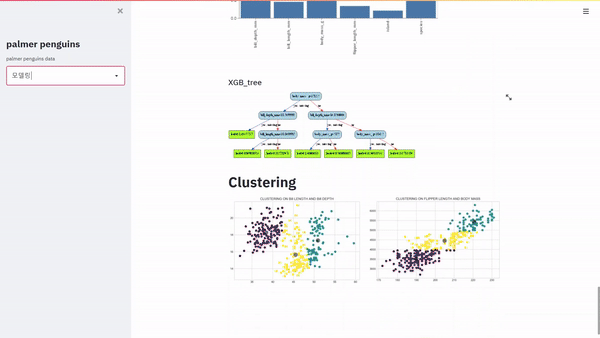
웹에서 대시보드를 개발하려고 합니다. 거창하게 개발이라고 말을 하였지만 엄연히 보면 구현에 가까울 거 같습니다. Python을 활용하여 대시보드를 만드는데 있어서 다양한 방법이 있겠지만 크게 Dash와 Streamlit에 관해 설명하려고 합니다. Dash의 경우 저번 포스팅에 설명을 하였고 실제로 웹에서 배포도 하여 이번에는 Streamlit를 이용하여 웹에서 배포를 해보았습니다. 대시보드 고도화를 위해서는 공홈에서 공부를 하면 좋을 거 같습니다. https://docs.streamlit.io/en/stable/getting_started.html Get started — Streamlit 0.84.2 documentation The easiest way to learn how to use Streaml..

캐글 자전거 수요 예측 데이터 분석을 하였습니다. 코드는 캐글 노트북을 참조하였습니다. datetime - 시간별 날짜 season - 1 = 봄, 2 = 여름, 3 = 가을, 4 = 겨울 holiday - 하루가 휴일로 간주되는지 여부 workingday - 주말과 휴일이 아닌 일하는 날 weather - 1: 맑음, 구름 조금, 흐림 2: 안개 + 흐림, 안개 + 구름, 안개 + 구름이 거의 없음 + 흐림 3: 가벼운 눈, 가벼운 비 + 천둥+ 구름, 가벼운 비 + 구름 4: 폭우 + 우박 + 천둥 + 안개, 눈 + 안개 temp - 섭씨 온도 atemp - 섭씨 온도의 느낌 humidity - 상대 습도 windspeed - 풍속 casual - 미등록 사용자 대여수 registered - 등록된 ..

캐글 타이타닉 데이터 분석을 해보았습다. 캐글 노트북에서 필요한 부분들을 참고하였으며 순서는 아래의 목차와 같습니다. III. 모델링 보팅을 통해서 제출결과 accuracy 0.77990이 나왔다. 이번 타이타닉 데이터의 경우 타이타닉 원본 데이터 존재로 인해서 많은 사람들이 정확도가 1이 나올 수 있었고 이번 타이타닉 데이터 분석을 통해서 데이터분석에 관해 잘못 알고있었던 점과 부족했던 부분에 대해서 더 자세히 알게 되는 계기가 되었으며 기초적인 데이터일지라도 피처에 대해 많은 생각을 하게 되었던 캐글이였다. 특히나 모델링 부분에서 많은 점을 배울 수 있어서 좋은 경험이 되었다. 코드는 아래 캐글 커널에서 볼 수 있습니다. https://www.kaggle.com/munmun2004/titanic-fo..

캐글 타이타닉 데이터 분석을 해보았습다. 캐글 노트북에서 필요한 부분들을 참고하였으며 순서는 아래의 목차와 같습니다. I. 데이터 불러오기 및 확인 II. EDA & FE 코드는 아래 캐글 커널에서 볼 수 있습니다. https://www.kaggle.com/munmun2004/titanic-for-begginers [titanic][한글커널]타이타닉 데이터분석 for Begginers Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic: Machine Learning from Disaster www.kaggle.com 본 글은 아래의 사이트를 참고하였습니다. 참고] Titanic Survival: Sea..
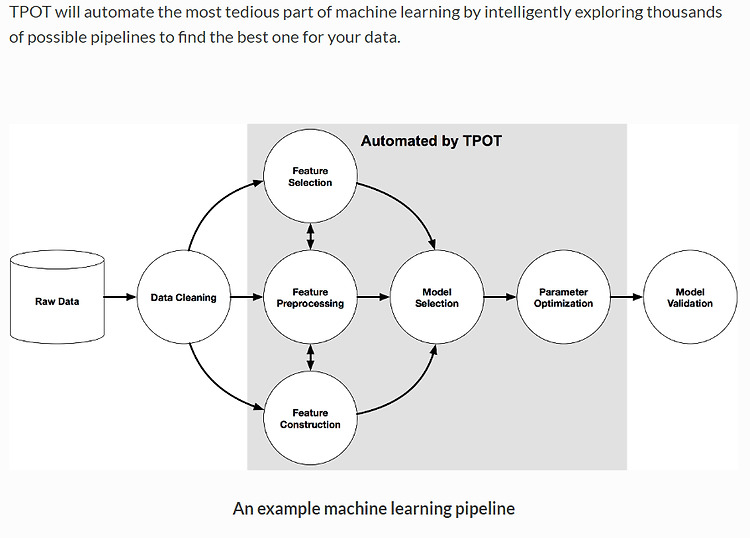
TPOT 같은 경우 Automated Machine Learning tool로써 머신러닝을 최적화 시켜준다. https://epistasislab.github.io/tpot/ Home - TPOT Consider TPOT your Data Science Assistant. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. TPOT will automate the most tedious part of machine learning by intelligently exploring thousan epistasislab.github.io 이렇게 tpot..
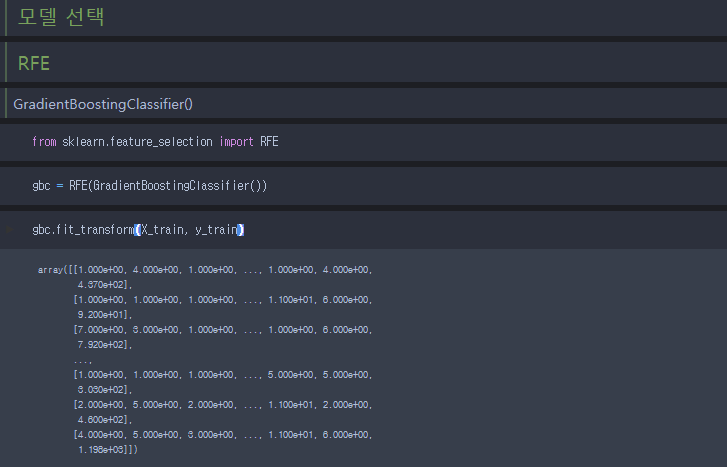
- RFE를 통해서 영향력을 끼치는 변수들만 새롭게 종합해서 변수를 만들고 모델을 돌려봄 - 이런식으로 LGBMClassifier,XGBXGBClassifier에 적용해서 f1_score 값을 구한다. -github 주소 : https://github.com/mjs1995/Contest_Fire mjs1995/Contest_Fire 공모전 _ [김해시] 화재발생 예측모델 개발. Contribute to mjs1995/Contest_Fire development by creating an account on GitHub. github.com
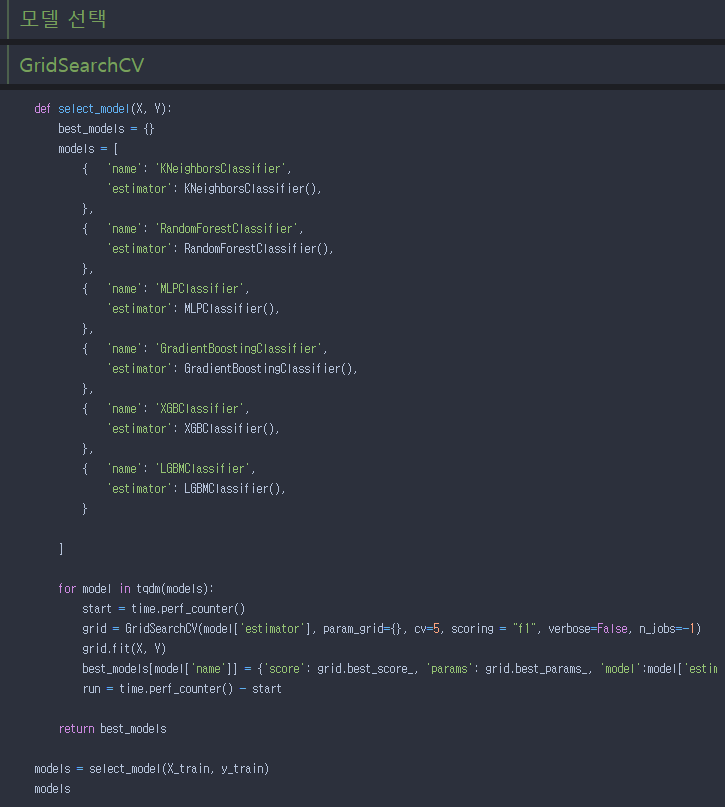
#GridSearchCV - f1 score값이 높은 3개의 모델 선택 -모델2를 선택 - 변수 중요도 그래프 #pipeline -github 주소 : https://github.com/mjs1995/Contest_Fire mjs1995/Contest_Fire 공모전 _ [김해시] 화재발생 예측모델 개발. Contribute to mjs1995/Contest_Fire development by creating an account on GitHub. github.com