TPOT 같은 경우 Automated Machine Learning tool로써 머신러닝을 최적화 시켜준다.
https://epistasislab.github.io/tpot/
Home - TPOT
Consider TPOT your Data Science Assistant. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. TPOT will automate the most tedious part of machine learning by intelligently exploring thousan
epistasislab.github.io


이렇게 tpot같은 경우 자동적으로 최고의 pipeline을 제시해준다.
단점으로는 학습시키는데 시간이 오래걸리는것이다. cpu기반으로 30시간은 걸렸던거같다.


- 이렇게 모든 CLassifier에 대해서 tpot이 자동적으로 돌려가며 scoring='f1'을 지정해줬기때문에 f1_score값이 높은것이 무슨 파이프라인인지 알수있다.
- tpot.export를 사용할경우 best Pipeline인 것만을 보여준다.
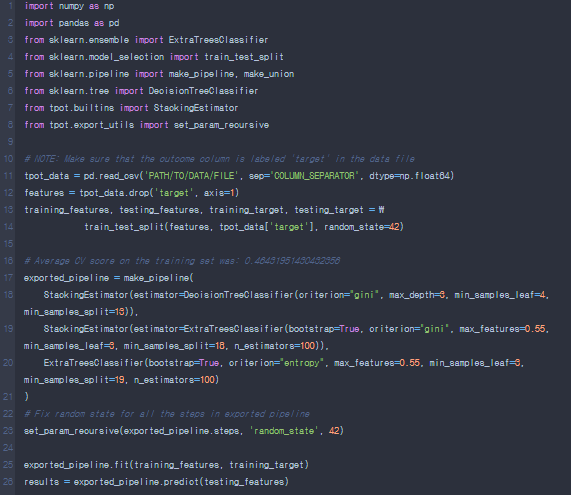
-추출된 tpot을 모델에 적용을 따로 시켜야한다.


-생각보다 f1_score가 높게 안나왔지만 파마리터를 지정해준다면 더 좋은 성능을 얻을수도 있을거 같고 automl을 처음 접해봤는데 신기했었고 시간이 오래걸리는건 크나큰 단점이라고 생각해야겠다.

- 이번 공모전을 통해서 데이터 전처리의 중요성에 대해서 많이 깨달았으며 EDA와 FE통해서 조금더 유의한 파생변수를 만들어야 겠다는 생각을 많이 했었다. 나름 2달간 공모전 준비를 하면서 많이 배웠고 많이 깨달았던거 같았다.
f1_score : 0.51478 31등으로 이번 공모전은 마무리하였다.
'Data Analysis' 카테고리의 다른 글
| [시계열] 홀트의 선형지수평활법, Holt-winter의 계절지수평활법 (0) | 2020.04.22 |
|---|---|
| [시계열] 단순이동평균과 단순지수평활법 (0) | 2020.04.22 |
| [김해시] 화재발생 예측모델 개발 _모델링_RFE (0) | 2019.12.16 |
| [김해시] 화재발생 예측모델 개발 _모델링_GridSearchCV, pipeline (0) | 2019.12.15 |
| [김해시] 화재발생 예측모델 개발 _데이터 전처리 및 데이터 탐색 (0) | 2019.12.15 |
