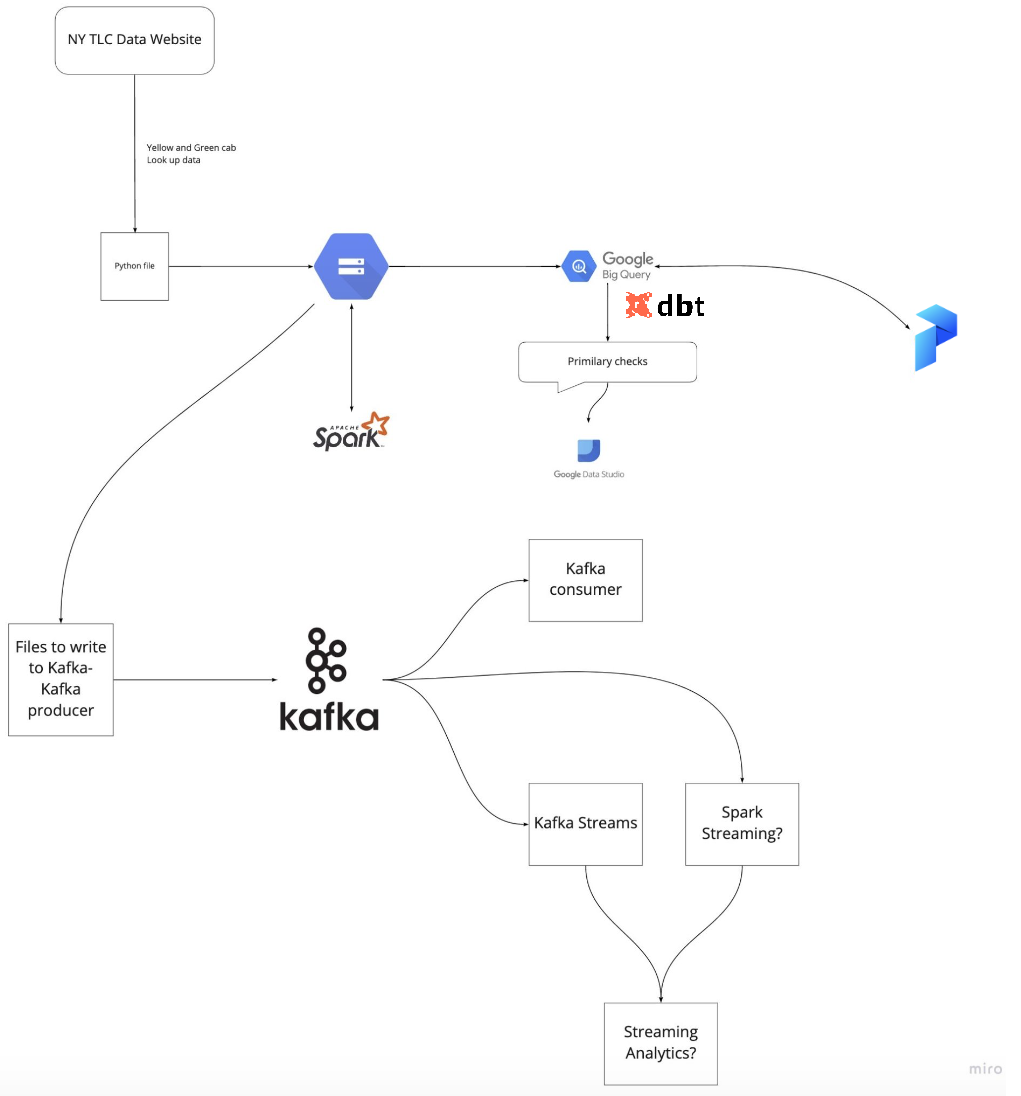
데이터 엔지니어링 줌 캠프 PJT를 진행하면서 관련된 내용을 정리하고자 합니다.
프로젝트의 코드는 github에서 확인할 수 있습니다.
https://github.com/mjs1995/data-engineering-zoomcamp/tree/main/06_stream_processing
GitHub - mjs1995/data-engineering-zoomcamp: PJT
PJT. Contribute to mjs1995/data-engineering-zoomcamp development by creating an account on GitHub.
github.com
docker에서 Spark 및 Kafka 실행

아파치 카프카(Apache Kafka)는 분산 스트리밍 플랫폼이며 데이터 피드의 분산 스트리밍, 파이프 라이닝 및 재생을 위한 실시간 스트리밍 데이터를 처리하기 위한 목적으로 설계된 오픈 소스 분산형 게시-구독 메시징 플랫폼입니다.
- 프로젝트에서 도커 파일로 사용한 서비스입니다.
- Apache Spark Master: Spark 클러스터에서 작업을 조정하고 클러스터 내에서 작업자 노드에 작업을 분배하는 역할을 합니다.
- Apache Spark Worker: Spark 클러스터에서 실제로 데이터 처리 작업을 수행하는 노드입니다. 마스터 노드로부터 작업을 할당받아 데이터 처리를 수행하게 됩니다.
- Apache Kafka Broker: 분산 스트리밍 플랫폼인 Apache Kafka에서 메시지 브로커 역할을 수행합니다. Producer와 Consumer가 메시지를 주고 받을 수 있도록 중개 역할을 합니다.
- Confluent Schema Registry: 데이터 스키마 버전 관리를 위한 서비스로, Kafka 메시지를 전송할 때 메시지의 구조와 형식을 검증하여 데이터 무결성을 유지합니다. 스키마 레지스트리는 스키마 생성, 조회, 관리에 대한 HTTP API를 제공하고 있습니다
- Apache Kafka ZooKeeper: Apache Kafka 클러스터의 메타 데이터 정보를 저장하고 관리하는 역할을 합니다.
- Confluent Control Center: Confluent Platform의 모니터링 및 관리 도구로, Kafka와 관련된 모든 작업을 한 곳에서 수행할 수 있도록 도와줍니다. 토픽 생성, 파티션 및 레플리카 관리, 스키마 관리, 모니터링 및 경고 등을 수행할 수 있습니다.
- docker-compose.yml 파일의 서비스들입니다.
- jupyterlab: JupyterLab 서비스를 실행합니다.
- spark-master: Apache Spark 클러스터의 마스터 노드를 실행합니다.
- spark-worker-1, spark-worker-2: Apache Spark 클러스터의 워커 노드를 실행합니다.
- broker: Apache Kafka 브로커를 실행합니다.
- schema-registry: Confluent Schema Registry 서비스를 실행합니다.
- zookeeper: Apache Kafka의 ZooKeeper를 실행합니다.
- control-center: Confluent Control Center 서비스를 실행합니다.
도커 데스크탑을 실행한 뒤에 Spark 컨테이너(spark master, spark worker, jupyterlab)를 빌드하는 데 필요한 도커 이미지를 다운로드합니다.
./build.sh
Kafka와 Spark가 연결되도록 네트워크와 볼륨을 만들어줍니다.
docker network create kafka-spark-network
docker volume create --name=hadoop-distributed-file-system
docker network ls

Kafka 및 Spark 컨테이너를 시작합니다.
docker compose up -d
도커에서 현재 실행 중인 컨테이너는 다음과 같습니다.
docker ps -a
컨테이너로 생성된 서비스들과 각각의 포트 번호, 그리고 해당 서비스의 간략한 설명입니다.
| Application | URL | Description |
| JupyterLab | localhost:8888 | Cluster interface with built-in Jupyter notebooks |
| Spark Master | localhost:8080 | Spark Master node |
| Spark Worker I | localhost:8083 | Spark Worker node with 1 core and 512m of memory (default) |
| Spark Worker II | localhost:8084 | Spark Worker node with 1 core and 512m of memory (default) |
| Confluent kafka | localhost:9021 | Web interface, to monitor, operate, and manage Kafka clusters |



현재 실행 중인 모든 컨테이너를 중지하는 명령어 입니다. 컨테이너를 사용하지 않을 때 실행시켜 줍니다.
docker stop $(docker ps -a -q)
kafka-python
새로운 환경을 설정해줍니다.
virtualenv kafka-env
source kafka-env/bin/activaterequirements.txt 파일을 생성해 줍니다.
kafka-python==1.4.6
confluent_kafka
requests
avro
faust
fastavro
pyspark필요한 라이브러리들을 설치해 줍니다.
pip install -r requirements.txt
소스 코드는 다음과 같습니다.
settings.py : 환경 구성에 대한 설정 파일입니다.
import pyspark.sql.types as T
INPUT_DATA_PATH = '../../resources/rides.csv'
BOOTSTRAP_SERVERS = 'localhost:9092'
TOPIC_WINDOWED_VENDOR_ID_COUNT = 'vendor_counts_windowed'
PRODUCE_TOPIC_RIDES_CSV = CONSUME_TOPIC_RIDES_CSV = 'rides_csv'
RIDE_SCHEMA = T.StructType(
[T.StructField("vendor_id", T.IntegerType()),
T.StructField('tpep_pickup_datetime', T.TimestampType()),
T.StructField('tpep_dropoff_datetime', T.TimestampType()),
T.StructField("passenger_count", T.IntegerType()),
T.StructField("trip_distance", T.FloatType()),
T.StructField("payment_type", T.IntegerType()),
T.StructField("total_amount", T.FloatType()),
])producer.py : 원본 데이터 파일 (rides.csv)에 연결하여 데이터를 가져와 메시지를 토픽에 전달합니다.
import csv
from time import sleep
from typing import Dict
from kafka import KafkaProducer
from settings import BOOTSTRAP_SERVERS, INPUT_DATA_PATH, PRODUCE_TOPIC_RIDES_CSV
def delivery_report(err, msg):
if err is not None:
print("Delivery failed for record {}: {}".format(msg.key(), err))
return
print('Record {} successfully produced to {} [{}] at offset {}'.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
class RideCSVProducer:
def __init__(self, props: Dict):
self.producer = KafkaProducer(**props)
# self.producer = Producer(producer_props)
@staticmethod
def read_records(resource_path: str):
records, ride_keys = [], []
i = 0
with open(resource_path, 'r') as f:
reader = csv.reader(f)
header = next(reader) # skip the header
for row in reader:
# vendor_id, passenger_count, trip_distance, payment_type, total_amount
records.append(f'{row[0]}, {row[1]}, {row[2]}, {row[3]}, {row[4]}, {row[9]}, {row[16]}')
ride_keys.append(str(row[0]))
i += 1
if i == 5:
break
return zip(ride_keys, records)
def publish(self, topic: str, records: [str, str]):
for key_value in records:
key, value = key_value
try:
self.producer.send(topic=topic, key=key, value=value)
print(f"Producing record for <key: {key}, value:{value}>")
except KeyboardInterrupt:
break
except Exception as e:
print(f"Exception while producing record - {value}: {e}")
self.producer.flush()
sleep(1)
if __name__ == "__main__":
config = {
'bootstrap_servers': [BOOTSTRAP_SERVERS],
'key_serializer': lambda x: x.encode('utf-8'),
'value_serializer': lambda x: x.encode('utf-8')
}
producer = RideCSVProducer(props=config)
ride_records = producer.read_records(resource_path=INPUT_DATA_PATH)
print(ride_records)
producer.publish(topic=PRODUCE_TOPIC_RIDES_CSV, records=ride_records)consumer.py : 토픽에서 메시지를 받아옵니다.
import argparse
from typing import Dict, List
from kafka import KafkaConsumer
from settings import BOOTSTRAP_SERVERS, CONSUME_TOPIC_RIDES_CSV
class RideCSVConsumer:
def __init__(self, props: Dict):
self.consumer = KafkaConsumer(**props)
def consume_from_kafka(self, topics: List[str]):
self.consumer.subscribe(topics=topics)
print('Consuming from Kafka started')
print('Available topics to consume: ', self.consumer.subscription())
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = self.consumer.poll(1.0)
if msg is None or msg == {}:
continue
for msg_key, msg_values in msg.items():
for msg_val in msg_values:
print(f'Key:{msg_val.key}-type({type(msg_val.key)}), '
f'Value:{msg_val.value}-type({type(msg_val.value)})')
except KeyboardInterrupt:
break
self.consumer.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Kafka Consumer')
parser.add_argument('--topic', type=str, default=CONSUME_TOPIC_RIDES_CSV)
args = parser.parse_args()
topic = args.topic
config = {
'bootstrap_servers': [BOOTSTRAP_SERVERS],
'auto_offset_reset': 'earliest',
'enable_auto_commit': True,
'key_deserializer': lambda key: int(key.decode('utf-8')),
'value_deserializer': lambda value: value.decode('utf-8'),
'group_id': 'consumer.group.id.csv-example.1',
}
csv_consumer = RideCSVConsumer(props=config)
csv_consumer.consume_from_kafka(topics=[topic])producer python 스크립트 파일을 실행합니다.
python producer.py
consumer python 스크립트 파일을 실행합니다.
python consumer.py
Confluent Control Center에서 위에서 실행한 producer와 consumer에 대한 Topic을 확인합니다.

PySpark Streaming
streaming.py는 스파크를 사용하여 Kafka로부터 스트리밍 데이터를 읽어들이고, 파싱하고, 집계한 후 콘솔에 출력하거나 다시 Kafka로 출력하는 코드입니다.
streaming.py의 소스 코드는 다음과 같습니다.
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import findspark
findspark.init()
from settings import RIDE_SCHEMA, CONSUME_TOPIC_RIDES_CSV, TOPIC_WINDOWED_VENDOR_ID_COUNT
def read_from_kafka(consume_topic: str):
# Spark Streaming DataFrame, connect to Kafka topic served at host in bootrap.servers option
df_stream = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092,broker:29092") \
.option("subscribe", consume_topic) \
.option("startingOffsets", "earliest") \
.option("checkpointLocation", "checkpoint") \
.load()
return df_stream
def parse_ride_from_kafka_message(df, schema):
""" take a Spark Streaming df and parse value col based on <schema>, return streaming df cols in schema """
assert df.isStreaming is True, "DataFrame doesn't receive streaming data"
df = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# split attributes to nested array in one Column
col = F.split(df['value'], ', ')
# expand col to multiple top-level columns
for idx, field in enumerate(schema):
df = df.withColumn(field.name, col.getItem(idx).cast(field.dataType))
return df.select([field.name for field in schema])
def sink_console(df, output_mode: str = 'complete', processing_time: str = '5 seconds'):
write_query = df.writeStream \
.outputMode(output_mode) \
.trigger(processingTime=processing_time) \
.format("console") \
.option("truncate", False) \
.start()
return write_query # pyspark.sql.streaming.StreamingQuery
def sink_memory(df, query_name, query_template):
query_df = df \
.writeStream \
.queryName(query_name) \
.format("memory") \
.start()
query_str = query_template.format(table_name=query_name)
query_results = spark.sql(query_str)
return query_results, query_df
def sink_kafka(df, topic):
write_query = df.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092,broker:29092") \
.outputMode('complete') \
.option("topic", topic) \
.option("checkpointLocation", "checkpoint") \
.start()
return write_query
def prepare_df_to_kafka_sink(df, value_columns, key_column=None):
columns = df.columns
df = df.withColumn("value", F.concat_ws(', ', *value_columns))
if key_column:
df = df.withColumnRenamed(key_column, "key")
df = df.withColumn("key", df.key.cast('string'))
return df.select(['key', 'value'])
def op_groupby(df, column_names):
df_aggregation = df.groupBy(column_names).count()
return df_aggregation
def op_windowed_groupby(df, window_duration, slide_duration):
df_windowed_aggregation = df.groupBy(
F.window(timeColumn=df.tpep_pickup_datetime, windowDuration=window_duration, slideDuration=slide_duration),
df.vendor_id
).count()
return df_windowed_aggregation
if __name__ == "__main__":
spark = SparkSession.builder.appName('streaming-examples').getOrCreate()
spark.sparkContext.setLogLevel('WARN')
# read_streaming data
df_consume_stream = read_from_kafka(consume_topic=CONSUME_TOPIC_RIDES_CSV)
print(df_consume_stream.printSchema())
# parse streaming data
df_rides = parse_ride_from_kafka_message(df_consume_stream, RIDE_SCHEMA)
print(df_rides.printSchema())
sink_console(df_rides, output_mode='append')
df_trip_count_by_vendor_id = op_groupby(df_rides, ['vendor_id'])
df_trip_count_by_pickup_date_vendor_id = op_windowed_groupby(df_rides, window_duration="10 minutes",
slide_duration='5 minutes')
# write the output out to the console for debugging / testing
sink_console(df_trip_count_by_vendor_id)
# write the output to the kafka topic
df_trip_count_messages = prepare_df_to_kafka_sink(df=df_trip_count_by_pickup_date_vendor_id,
value_columns=['count'], key_column='vendor_id')
kafka_sink_query = sink_kafka(df=df_trip_count_messages, topic=TOPIC_WINDOWED_VENDOR_ID_COUNT)
spark.streams.awaitAnyTermination()spark-submit을 실행합니다.
./spark-submit.sh streaming.py직접 설정값을 조정할 수 도 있습니다.
spark-submit --master spark://localhost:7077 --num-executors 2 --executor-memory 3G --executor-cores 1 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.1,org.apache.spark:spark-avro_2.12:3.3.1,org.apache.spark:spark-streaming-kafka-0-10_2.12:3.3.1 streaming.py

해당 spark-submit 관련 에러는 블로그 포스팅에서 확인하실 수 있습니다.
Reference
데이터 엔지니어링 줌 캠프 깃허브 주소
youtube
DataTalks.Club
data engineering zoomcamp slack
'PJT' 카테고리의 다른 글
| [OSSCA 2023] python-mysql-replication 프로젝트에 기여하기 - 01 : 문서 업데이트, 버그 수정 및 기능 개발 (1) | 2023.10.02 |
|---|---|
| [OSSCA 2023] python-mysql-replication (0) | 2023.09.25 |
| [de zoomcamp] 05_배치 처리 (0) | 2023.05.07 |
| [de zoomcamp] 04_분석 엔지니어링 (0) | 2023.05.07 |
| [de zoomcamp] 03_데이터 웨어하우스 (0) | 2023.05.07 |
