
- datasets에서 iris데이터를 불러오고 뉴럴네트워크에서 MLPClassfiier를 불러들어와 fit시켜보았다. - tensorflow에 keras에서 KerasClassifier를 불러들어와서 Sequetial을 이용해 모델을 만들어봤다. - 다중 분리이기 때문에 sparse 카테고리컬 크로스엔트로피를 사용했고 활성화함수는 렐루를 썼다. - KerasClassifier에 에폭을 5로해서 학습을 시키고 교차검증을 해보았다. - 머신러닝은 데이터가 많을수록 성능이 안올라가는데 딥러닝은 모델이 훨씬 더 복잡하기 때문에 더 성능을 올리수 있다.오버피팅이 생길수 있는데 이것을 막으려면 데이터를 늘려야한다. - 러닝커브를 그려보면 데이터가 요동쳐서 학습이 부족하다는 것을 알수있다. - 데이터가 충분하지 않..

독학으로 인강을 듣다가 머신러닝과 관련된 책을 추천받아 책을 읽게 되었다. 저자는 세바스찬 라시카이다. 여기에는 머신러닝을 하는 데 있어서 다양한 툴과 모델을 경험해볼 수 있고 코드까지 따로 구현되어있어 직접 코드 리뷰를 할 수 있다. 특히 머신러닝을 처음 접하거나 아니면 머신러닝을 조금 공부했던 사람들에게는 이 책이 좋은 길잡이가 될 수 있을 거 같다. 이 책은 지도 학습, 강화 학습, 비지도 학습 같은 학습의 종류를 소개하면서 classification 문제나 regression 문제에 대해서 잘 설명해 놓았으며 tensorflow에 관한 설명도 있어서 딥러닝의 전반적인 기초까지 얻을 수 있다. 특히 머신러닝을 하는 데 있어서 고급 분류 알고리즘이 있어서 RF나 파이프라인 구축하는 법과 GridSea..
해당 글은 2018~2019년 학교생활을 병행하면서 독학했던 강의들입니다. 그동안 독학했던 공부를 정리하고자 한다. 온라인 강의 위주로 되어있다. ### edwith [edwith][찰스 세이블런 교수님] 모두를 위한 프로그래밍 : 파이썬 [edwith][찰스 세이블런 교수님] 파이썬 자료구조 [edwith][찰스 세이블런 교수님] 파이썬을 이용한 웹 스크래핑 [edwith][찰스 세이블런 교수님] 파이썬을 이용한 데이터베이스 처리 [edwith][김성훈 교수님] 머신러닝과 딥러닝 BASIC [edwith][최성철 교수님] 머신러닝을 위한 Python 워밍업 [edwith][앤드류 응 교수님]딥러닝 1단계 : 신경망과 딥러닝 [edwith][앤드류 응 교수님]딥러닝 2단계 : 심층 신경망 성능 향상시키기..

순서와 상관없이 결승선을 통과하는 1등마, 2두마,3두마를 머신러닝을 활용해서 예측해보려고 한다. 모델을 randomforest모델과 LogisticRegression모델을 사용하였다. 각 1등말,2두마,3두마별로 RF모델을 적용하고 각 1등말,2두마,3두마별로 LR모델을 적용했다. 각 데이터의 결과를 보면 과적합이 된것을 볼 수 있다. 가중치를 주어서 과적합을 해결하려고한다. 각각의 모델에 class_weight = 'balanced' 를 적용시켜 가중치를 주었다. https://scikit-learn.org/stable/modules/generated/sklearn.utils.class_weight.compute_class_weight.html sklearn.utils.class_weight.comp..
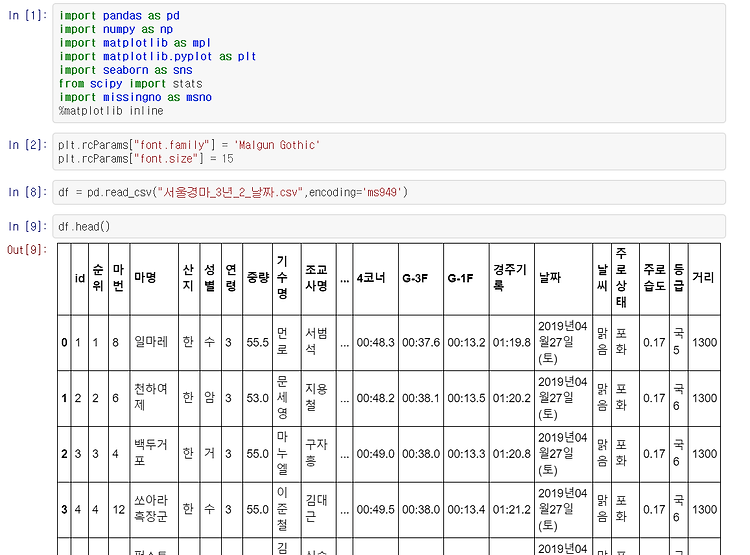
- 크롤링해온 데이터를 통해서 데이터탐색을 해보려고 한다. 크롤링을 통해서 내가 원하는 부분만을 가져와서 전처리할게 별로 없었다. -모든 변수들에 대해서 countplot을 그려서 분포를 확인했었고 -heatmap을 통해서 변수들의 연관성에 대해서 생각을 해보았다. -spss 카이제곱 검정을 통해서 변수들의 연관성 여부에 대해서 검정을 실시해보았고 기존 연구에서 유의미하다고 생각되는 변수들도 순위에 영향을 줄거라고 생각을 해보고 데이터 분석을 실시하였다. EDA를 통해 연관성있는 변수들에 대해서 따로 지정을 해주고 초단위를 정제해주었다. 그 다음 더미변수들을 생성하여 데이터에 merge merge하였고 전처리 된 데이터를 새롭게 csv형태로 만들어주었다.