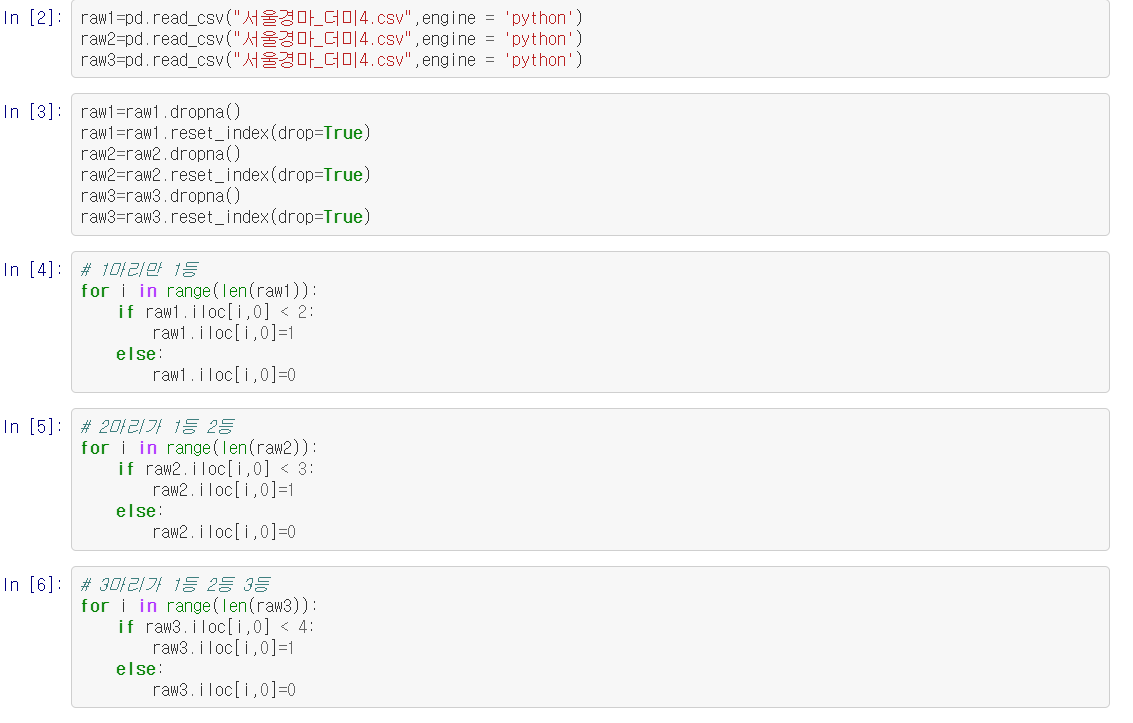
순서와 상관없이 결승선을 통과하는 1등마, 2두마,3두마를 머신러닝을 활용해서 예측해보려고 한다.
모델을 randomforest모델과 LogisticRegression모델을 사용하였다.

각 1등말,2두마,3두마별로 RF모델을 적용하고

각 1등말,2두마,3두마별로 LR모델을 적용했다.

각 데이터의 결과를 보면 과적합이 된것을 볼 수 있다. 가중치를 주어서 과적합을 해결하려고한다.

각각의 모델에 class_weight = 'balanced' 를 적용시켜 가중치를 주었다.
sklearn.utils.class_weight.compute_class_weight — scikit-learn 0.21.3 documentation
Parameters: class_weight : dict, ‘balanced’ or None If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class w
scikit-learn.org
해당 코드에 대한 설명은 sklearn 공식 사이트에서 확인할수있다.

그결과 과적합이 되지않고 f1-score도 75%값을 얻었다.

전체 실험 결과 가중치를 두고 학습한 결과과 유의미하다고 판단하였고

ROC커브 결과 로지스틱 모델보다 랜덤포레스트모델이 더 성능이 좋다고 판단하였다.
경마 데이터 분석 프로젝트를 하면서 데이터를 직접 수집하고 분석하는 과정이 재밌었고 많은 공부가 되었던거 같다.
지금와서 보면 많이 손볼곳도 많지만 아직도 머신러닝에 대해서 더 공부하고 사이킷에 대해서 더 공부를 해야될거같다.
'Data Analysis' 카테고리의 다른 글
| [R][시계열] 시계열 데이터 분석 (0) | 2019.12.01 |
|---|---|
| [R] Groceries 데이터 연관규칙분석 (0) | 2019.11.27 |
| [경마 데이터 분석] 경마 데이터 EDA 및 전처리 (0) | 2019.11.27 |
| [python][경마 데이터 분석]경마 말혈통정보 크롤링 Xpath (0) | 2019.11.25 |
| [python][경마 데이터 분석]경마 렛츠런파크 크롤링 Xpath (0) | 2019.11.25 |
