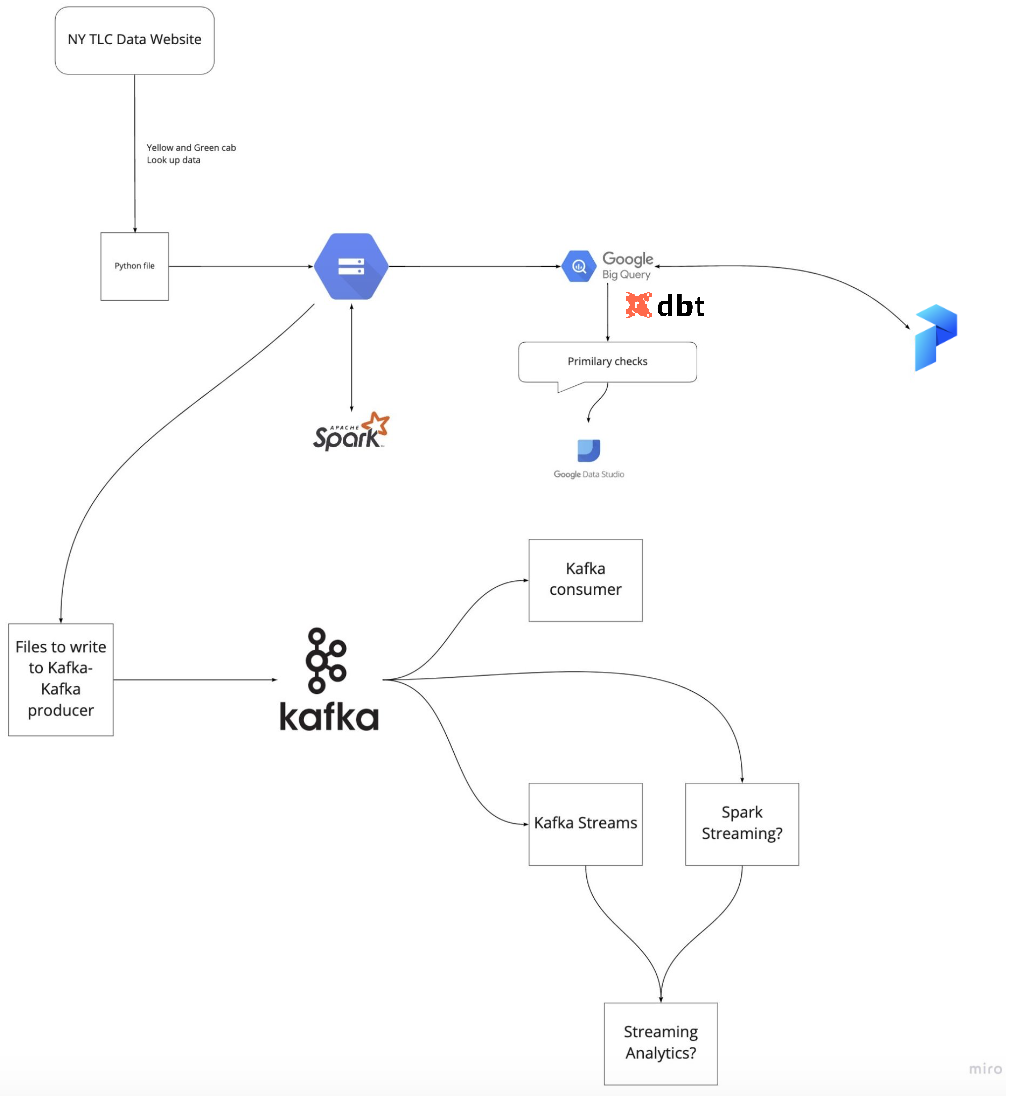
데이터 엔지니어링 줌 캠프 PJT를 진행하면서 관련된 내용을 정리하고자 합니다.
프로젝트의 코드는 github에서 확인할 수 있습니다.
https://github.com/mjs1995/data-engineering-zoomcamp/tree/main/03_data_warehouse
GitHub - mjs1995/data-engineering-zoomcamp: PJT
PJT. Contribute to mjs1995/data-engineering-zoomcamp development by creating an account on GitHub.
github.com
Bigquery
빅쿼리란?

- 빅쿼리는 머신 러닝이 내장되어 있으며 확장성이 우수한 완전 관리형 데이터 웨어 하우스입니다.
- 확장성이 뛰어난 구글의 기업용 서버리스 기반의 데이터 웨어하우스로 관리할 인프라가 없기 때문에 데이터 분석에 집중할 수 있으며, 인프라 및 데이터를 관리할 관리자도 필요하지 않습니다.
- 스토리지와 컴퓨팅이 분리되어 있기 때문에 데이터 웨어하우스의 용량을 원하는 대로 계획할 수 있는 탄력적인 확장성을 가집니다.. 자동 확장과 고성능 스트리밍 수집 방식을 지원해서 실시간 분석의 어려움도 간편하게 해결할 수 있습니다.
- BigQuery 구조
- project : 가장 큰 개념으로, 프로젝트에는 결제 및 승인된 사용자에 대한 정보가 저장되며 각 프로젝트에는 이름과 고유 ID가 있습니다.. 하나의 프로젝트에는 여러 개의 데이터세트(Dataset)가 들어갈 수 있습니다.
- Dataset : RDB의 데이터베이스와 같은 개념으로, Dataset는 특정 프로젝트에 포함되며, 테이블과 뷰에 대한 액세스를 구성하고 제어하는 데 사용합니다.. 하나의 Dataset에는 여러 개의 Table을 가질 수 있습니다.
- Table : RDB의 Table과 같은 개념으로, 행으로 구성된 개별 레코드가 포함됩니다. 각 레코드는 칼럼으로 구성되며, 모든 테이블은 칼럼명, 데이터 유형, 기타 정보를 설명하는 스키마로 정의됩니다.
- 기본 테이블 : 기본 BigQuery Repository에서 지원되는 테이블
- 외부 테이블 : BigQuery 외부 Repository에서 지원되는 테이블
- 뷰 : SQL 쿼리로 정의된 가상 테이블
- Job : 쿼리, 데이터 로딩, 생성, 삭제 등 작업에 대한 단위
external table
빅쿼리에서 외부 테이블을 생성해 줍니다.

CREATE OR REPLACE EXTERNAL TABLE `dtc-de-382512.dezoomcamp.external_yellow_tripdata`
OPTIONS (
format = 'CSV',
uris = ['gs://prefect-de-zoom1/data/yellow/yellow_tripdata_2021-01.parquet']
);파티셔닝

- 테이블을 조각으로 분할하면 검색해야 하는 데이터가 전체 테이블을 읽어야 하는 경우보다 훨씬 작기 때문에 쿼리 속도가 크게 향상됩니다.
- 세 가지 유형의 파티셔닝
- 정수 범위로 분할
- 시간 단위로 컬럼 분할
- 수집 시간으로 파티션 나누기
pickup_datetime을 기준으로 파티션 해줍니다.
CREATE OR REPLACE TABLE dtc-de-382512.dezoomcamp.yellow_tripdata_partitoned
PARTITION BY
DATE(tpep_pickup_datetime) AS
SELECT * FROM dtc-de-382512.dezoomcamp.rides;
클러스터링

- 하나 이상의 열(최대 4개)을 기준으로 테이블의 데이터를 재정렬합니다.
- 열의 순서는 열의 우선순위 결정과 관련이 있습니다.
- 조건문 또는 집계 함수를 사용하는 쿼리의 성능 향상
파티션과 동시에 클러스터를 생성할 수 있습니다.

VendorID 기준으로 클러스터링 해줍니다.
CREATE OR REPLACE TABLE dtc-de-382512.dezoomcamp.yellow_tripdata_partitoned_clustered
PARTITION BY DATE(tpep_pickup_datetime)
CLUSTER BY VendorID AS
SELECT * FROM dtc-de-382512.dezoomcamp.external_yellow_tripdata;클러스터링 된 테이블을 확인해줍니다.

Bigquery ML

- BigQuery ML을 이용하여 SQL 쿼리를 통해 ML 모델을 학습시키는 것이 가능하며, 클라우드 ML 엔진(Cloud ML Engine) 및 텐서플로(Tensorflow)와도 통합이 가능합니다.
- BigQuery에서 Python이나 자바와 같은 프로그래밍 언어 없이 표준 SQL 쿼리만으로 머신 러닝 모델을 만들고 실행할 수 있습니다.
- 장점
- Python이나 자바와 같은 프로그래밍 언어를 사용하지 않고 SQL을 사용해 모델을 만들고 실행할 수 있습니다.
- 데이터 웨어하우스 내에서 모델을 만들고 실행하기 때문에 데이터를 내보내지 않아도 됩니다. 이로 인해서 속도 면에서 큰 장점을 가질 수 있습니다.
ML을 위한 데이터셋을 만들어 줍니다.
-- CREATE A ML TABLE WITH APPROPRIATE TYPE
CREATE OR REPLACE TABLE `taxi-rides-ny.nytaxi.yellow_tripdata_ml` (
`passenger_count` INTEGER,
`trip_distance` FLOAT64,
`PULocationID` STRING,
`DOLocationID` STRING,
`payment_type` STRING,
`fare_amount` FLOAT64,
`tolls_amount` FLOAT64,
`tip_amount` FLOAT64
) AS (
SELECT passenger_count, trip_distance, cast(PULocationID AS STRING), CAST(DOLocationID AS STRING),
CAST(payment_type AS STRING), fare_amount, tolls_amount, tip_amount
FROM `taxi-rides-ny.nytaxi.yellow_tripdata_partitoned` WHERE fare_amount != 0
);tip_amount을 예측하는 목적으로 선형 회귀 모델을 만들어줍니다.
CREATE OR REPLACE MODEL `taxi-rides-ny.nytaxi.tip_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['tip_amount'],
DATA_SPLIT_METHOD='AUTO_SPLIT') AS
SELECT
*
FROM
`taxi-rides-ny.nytaxi.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL;- MODELE_TYPE='linear_reg'에서는 선형 회귀 모델을 만듭니다.
- INPUT_LABEL_COLS=['tip_amount']에서는 모델을 학습하고 사용하는 데 사용할 열 배열입니다.
- DATA_SPLIT_METHOD='AUTO_SPLIT'에서는 데이터 세트를 훈련용과 테스트용(훈련/테스트)의 두 부분으로 자동 분할하도록 지정합니다.

모델의 세부정보를 확인해 줍니다.

모델 정보에 대해 그래프로도 확인할 수 있습니다.

모델의 score에 대해서도 자세히 확인할 수 있습니다.

변수를 확인합니다.
SELECT * FROM ML.FEATURE_INFO(MODEL `taxi-rides-ny.nytaxi.tip_model`);
모델을 평가합니다.
SELECT
*
FROM
ML.EVALUATE(MODEL `dtc-de-382512.dezoomcamp.tip_model`,
(
SELECT
*
FROM
`dtc-de-382512.dezoomcamp.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
));모델을 예측합니다.
SELECT
*
FROM
ML.PREDICT(MODEL `dtc-de-382512.dezoomcamp.tip_model`,
(
SELECT
*
FROM
`dtc-de-382512.dezoomcamp.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
));모델을 예측하고 설명합니다.
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `dtc-de-382512.dezoomcamp.tip_model`,
(
SELECT
*
FROM
`dtc-de-382512.dezoomcamp.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL
), STRUCT(3 as top_k_features));파라미터를 튜닝도 가능합니다.
CREATE OR REPLACE MODEL `dtc-de-382512.dezoomcamp.tip_hyperparam_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['tip_amount'],
DATA_SPLIT_METHOD='AUTO_SPLIT',
num_trials=5,
max_parallel_trials=2,
l1_reg=hparam_range(0, 20),
l2_reg=hparam_candidates([0, 0.1, 1, 10])) AS
SELECT
*
FROM
`dtc-de-382512.dezoomcamp.yellow_tripdata_ml`
WHERE
tip_amount IS NOT NULL;
파라미터 튜닝된 테이블의 세부정보를 확인합니다.

파라미터 튜닝에 대해 자세한 정보를 확인할 수 있습니다.

학습된 모델에 대한 평가 정보를 확인할 수 있습니다.

BigQuery Machine Learning Deployment
gs에 gcp의 모델을 만들어줍니다.
gcloud --version
gcloud auth login
bq --project_id dtc-de-382512 extract -m dezoomcamp.tip_model gs://taxi_ml_model_js/tip_model

다음 코드를 실행하여 모델을 배포해 줍니다.
mkdir /tmp/model
gsutil cp -r gs://taxi_ml_model_js/tip_model /tmp/model
mkdir -p serving_dir/tip_model/1
cp -r /tmp/model/tip_model/* serving_dir/tip_model/1
docker pull tensorflow/serving
docker run -p 8501:8501 --mount type=bind,source=pwd/serving_dir/tip_model,target=/models/tip_model -e MODEL_NAME=tip_model -t tensorflow/serving &
curl -d '{"instances": [{"passenger_count":1, "trip_distance":12.2, "PULocationID":"193", "DOLocationID":"264","payment_type":"2","fare_amount":20.4,"tolls_amount":0.0}]}' -X POST http://localhost:8501/v1/models/tip_model:predict
http://localhost:8501/v1/models/tip_modelReference
데이터 엔지니어링 줌 캠프 깃허브 주소
youtube
DataTalks.Club
data engineering zoomcamp slack
'PJT' 카테고리의 다른 글
| [de zoomcamp] 05_배치 처리 (0) | 2023.05.07 |
|---|---|
| [de zoomcamp] 04_분석 엔지니어링 (0) | 2023.05.07 |
| [de zoomcamp] 02_워크플로 오케스트레이션 (0) | 2023.05.01 |
| [de zoomcamp] 01_소개 및 사전 준비 사항 (0) | 2023.04.30 |
| [de zoomcamp] Data Engineering Zoomcamp 소개 (0) | 2023.04.30 |
