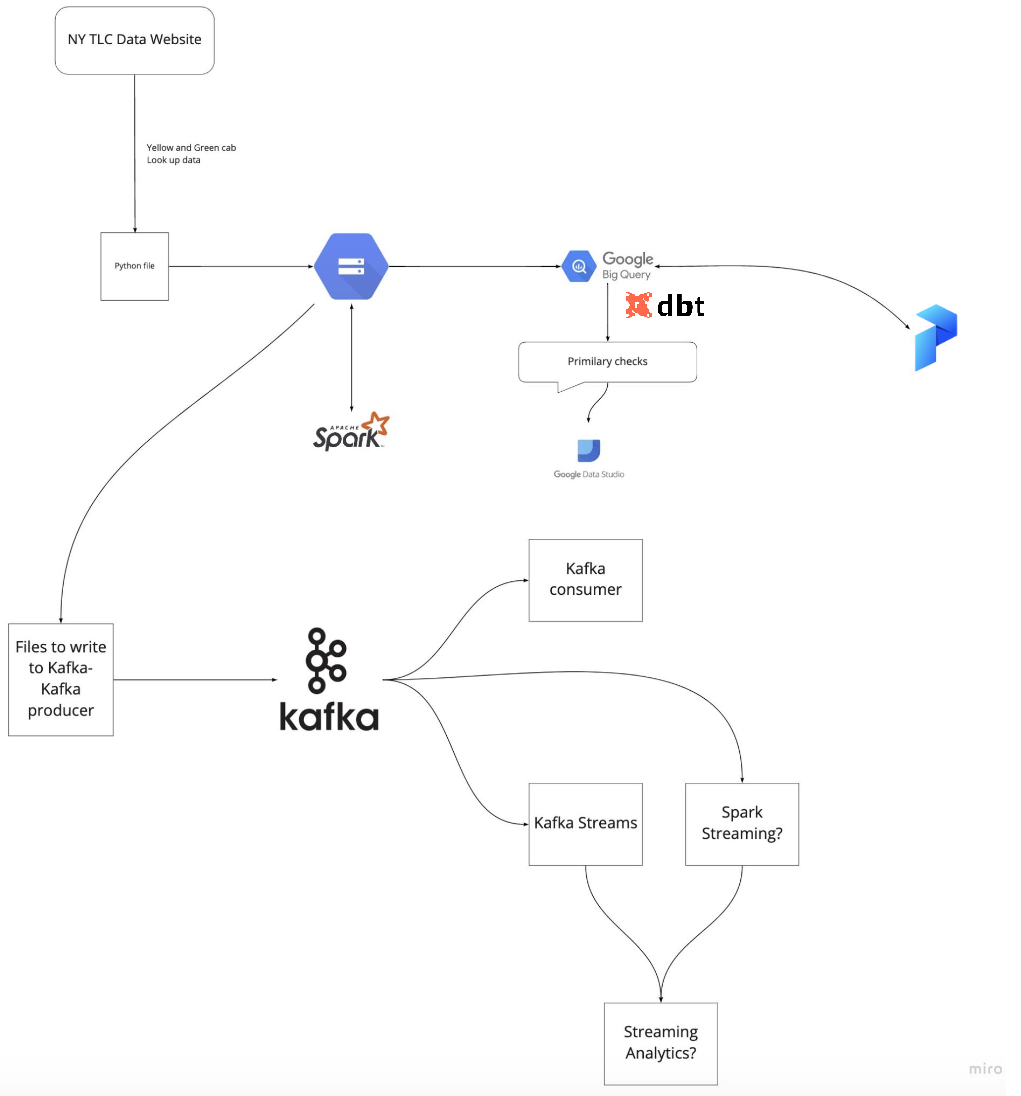
데이터 엔지니어링 줌 캠프 PJT를 진행하면서 관련된 내용을 정리하고자 합니다.
프로젝트의 코드는 github에서 확인할 수 있습니다.
GitHub - mjs1995/data-engineering-zoomcamp
Contribute to mjs1995/data-engineering-zoomcamp development by creating an account on GitHub.
github.com
Prefect
Cloud Storage 에서 BigQuery 데이터 베이스 로 Parquet 데이터를 수집하기 위해 Prefect을 쓰려고 합니다.
Prefect에 관한 내용은 다음 링크를 참고해주세요.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/prefect_base.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
zoomcamp 가상환경을 생성한 뒤에 필요한 라이브러리를 설치해줍니다.
conda create -n zoomcamp python=3.9
conda activate zoomcamp
pip install -r requirements.txtrequirements.txt 파일의 경우 다음과 같습니다.
pandas==1.5.2
prefect==2.7.7
prefect-sqlalchemy==0.2.2
prefect-gcp[cloud_storage]==0.2.3
protobuf==4.21.11
pyarrow==10.0.1
pandas-gbq==0.19.0Prefect GUI 환경으로 접속합니다.
prefect orion start
GCS Pipeline 연결
버킷을 신규로 생성합니다. 버킷의 이름은 prefect-de-zoom으로 설정해줍니다.

prefect 내부에서 Block를 눌러 다양한 커넥터를 확인합니다.

Google Cloud Platform 용 Prefect 커넥터를 등록합니다.
prefect GUI 환경에서 GCS 등록해줍니다.
prefect block register -m prefect_gcp
먼저 구글 IAM에서 서비스계정을 신규로 만듭니다.
BigQuery 관리자와 저장소 관리자의 역할을 부여해줍니다.


생성된 서비스 계정에 신규로 키를 등록해주고 prefect에도 등록해줍니다.


prefect에서 Blocks를 만들고 코드를 실행시키는데 ValueError: Unable to find block document named zoom-gcs for block type gcs-bucket 에러가 발생했습니다.
pip install prefect --upgrade
prefect orion database reset
prefect block register -m prefect_gcp
prefect block register -m prefect_sqlachemy
그 후에 로컬 터미널이 아닌 vscode ssh 터미널을 이용해서 prefect orion start를 실행하고 다시 Blocks를 등록해줍니다. 여기서 서비스계정의 키도 신규로 추가했습니다.



GCS 버킷에 데이터가 잘 적재된것을 확인할 수 있습니다.

위와 같은 에러가 발생한다면 먼저 Blocks에 Type이 잘 할당 되었는지 확인이 필요할 거같습니다.
prefect blocks ls
전체 소스코드는 다음과 같습니다.
from pathlib import Path
import pandas as pd
from prefect import flow, task
from prefect_gcp.cloud_storage import GcsBucket
@task(retries=3)
#retries parametes tells how many times our task will restart in case of crash
def fetch(dataset_url: str) -> pd.DataFrame:
"""Read data from web inmto pandas dataframe"""
df = pd.read_csv(dataset_url)
return df
@task(log_prints=True)
#log_prints will write logs to our console and UI
def clean(df) -> pd.DataFrame:
"""Fix some dtype issues"""
df["tpep_pickup_datetime"] = pd.to_datetime(df["tpep_pickup_datetime"])
df["tpep_dropoff_datetime"] = pd.to_datetime(df["tpep_dropoff_datetime"])
print(df.head(2))
print(df.dtypes)
print('Length of DF:', len(df))
return df
@task(log_prints=True)
def export_data_local(df, color, dataset_file):
path = Path(f"data/{color}/{dataset_file}.parquet")
df.to_parquet(path, compression="gzip")
return path
@task()
def write_local(df: pd.DataFrame, color: str, dataset_file: str) -> Path:
"""write df as a parquet file"""
path = Path(f"data/{color}/{dataset_file}.parquet")
if not path.parent.is_dir():
path.parent.mkdir(parents=True)
df.to_parquet(path, compression="gzip")
return path
@task()
def write_gcs(path: Path) -> None:
"""Upload local parquet file to GCS"""
gcs_block = GcsBucket.load("zoom-gcs")
gcs_block.upload_from_path(from_path=path, to_path=path)
return
@flow()
def etl_web_to_gcs()->None:
"""Main ETL function"""
color = "yellow"
year = 2021
month = 1
dataset_file = f"{color}_tripdata_{year}-{month:02}"
dataset_url = f"https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{color}/{dataset_file}.csv.gz"
df = fetch(dataset_url)
df_clean = clean(df)
path = write_local(df_clean, color, dataset_file)
write_gcs(path)
if __name__ == '__main__':
etl_web_to_gcs()Cloud Storage에서 BigQuery로 Parquet 수집
데이터를 GCP로 수집하려면 Parquet 파일의 스키마를 사용하여 BigQuery에서 테이블을 생성해야 합니다
GCP > BigQuery > 추가 > Google Cloud Storage를 클릭합니다.

GCS URI 패턴을 사용하세요 옆에 찾아보기를 눌러 GCS 상의 parquet 파일을 선택해줍니다.

아래와 같은 설정으로 빅쿼리 파일을 추가해줍니다.

테이블을 만들 수 없음: Cannot read and write in different locations: source: asia, destination: asia-northeast3 라는 error가 발생하는데 gcs의 리전이 asia이고 bigquery의 리전이 달라서 생기는 에러입니다. 즉, GCS 버킷에서 BigQuery로 데이터를 로드할 수 있도록 모든 리소스가 동일한 리전을 공유해야 합니다.
- GCP의 데이터 세트 만들기를 한 뒤에 GCS 버킷의 리전이 맞춰주면 되지만 저의 경우에는 GCS의 멀티 리전이 asia이고 빅쿼리에서 asia는 연동이 안되어서 데이터 이전을 해서 해결을 하려고 합니다.


- 신규로 US 리전의 GCS 버킷을 만들고 기존의 asia 리전에서 데이터를 전송합니다.

다시 GCP에서 테이블을 추가해줍니다. prefect blocks에서도 GCP 버킷의 주소를 변경해 줍니다.


- 위에서 만든 dataset을 지우고 prefect을 이용해서 etl 합니다.

prefect을 실행시킬 때 Prefect Flow: ERROR | Flow run 'xxxxxx' - Finished in state Failed('Flow run encountered an exception. google.api_core.exceptions.Forbidden: 403 GET: Access Denied: Table xxxxx: Permission bigquery.tables.get denied on table xxxxxx (or it may not exist).\n') 에러가 발생 했는데 python 스크립트 안에서 해당 프로젝트 id와 GcpCredentials의 싱크를 맞추니 해결이 되었습니다.



실행해보면 데이터가 잘 인입된것을 볼 수 있습니다.


전체 소스 코드는 다음과 같습니다.
from pathlib import Path
import pandas as pd
from prefect import flow, task
from prefect_gcp.cloud_storage import GcsBucket
from prefect_gcp import GcpCredentials
@task(retries=3)
def extract_from_gcs(color: str, year: int, month: int) -> Path:
"""Download trip data from GCS"""
gcs_path = f"data/{color}/{color}_tripdata_{year}-{month:02}.parquet"
gcs_block = GcsBucket.load("zoom-gcs")
gcs_block.get_directory(from_path=gcs_path, local_path=f"../data/")
return Path(f"../data/{gcs_path}")
@task()
def transform(path: Path) -> pd.DataFrame:
"""Data cleaning example"""
df = pd.read_parquet(path)
print(f"pre: missing passenger count: {df['passenger_count'].isna().sum()}")
df["passenger_count"].fillna(0, inplace=True)
print(f"post: missing passenger count: {df['passenger_count'].isna().sum()}")
return df
@task()
def write_bq(df: pd.DataFrame) -> None:
"""Write DataFrame to BiqQuery"""
gcp_credentials_block = GcpCredentials.load("zoom-gcp-creds")
df.to_gbq(
destination_table="dezoomcamp.rides",
project_id="dtc-de-382512",
credentials=gcp_credentials_block.get_credentials_from_service_account(),
chunksize=500_000,
if_exists="append",
)
@flow()
def etl_gcs_to_bq():
"""Main ETL flow to load data into Big Query"""
color = "yellow"
year = 2021
month = 1
path = extract_from_gcs(color, year, month)
df = transform(path)
write_bq(df)
if __name__ == "__main__":
etl_gcs_to_bq()Parametrizing Flow & Deployments with ETL into GCS flow
ETL을 자동화하기 위해 방금 구축한 파이프라인을 매개변수화합니다.
deployments 폴더를 만들고 그 안에 year, month, color를 매개변수화 한 뒤에 코드를 재실행 합니다.

from pathlib import Path
import pandas as pd
from prefect import flow, task
from prefect_gcp.cloud_storage import GcsBucket
from random import randint
from prefect.tasks import task_input_hash
from datetime import timedelta
@task(retries=3, cache_key_fn=task_input_hash, cache_expiration=timedelta(days=1))
def fetch(dataset_url: str) -> pd.DataFrame:
"""Read taxi data from web into pandas DataFrame"""
# if randint(0, 1) > 0:
# raise Exception
df = pd.read_csv(dataset_url)
return df
@task(log_prints=True)
def clean(df: pd.DataFrame) -> pd.DataFrame:
"""Fix dtype issues"""
df["tpep_pickup_datetime"] = pd.to_datetime(df["tpep_pickup_datetime"])
df["tpep_dropoff_datetime"] = pd.to_datetime(df["tpep_dropoff_datetime"])
print(df.head(2))
print(f"columns: {df.dtypes}")
print(f"rows: {len(df)}")
return df
@task()
def write_local(df: pd.DataFrame, color: str, dataset_file: str) -> Path:
"""Write DataFrame out locally as parquet file"""
path = Path(f"data/{color}/{dataset_file}.parquet")
if not path.parent.is_dir():
path.parent.mkdir(parents=True)
df.to_parquet(path, compression="gzip")
return path
@task()
def write_gcs(path: Path) -> None:
"""Upload local parquet file to GCS"""
gcs_block = GcsBucket.load("zoom-gcs")
gcs_block.upload_from_path(from_path=path, to_path=path)
return
@flow()
def etl_web_to_gcs(year: int, month: int, color: str) -> None:
"""The main ETL function"""
dataset_file = f"{color}_tripdata_{year}-{month:02}"
dataset_url = f"https://github.com/DataTalksClub/nyc-tlc-data/releases/download/{color}/{dataset_file}.csv.gz"
df = fetch(dataset_url)
df_clean = clean(df)
path = write_local(df_clean, color, dataset_file)
write_gcs(path)
@flow()
def etl_parent_flow(months: list[int] = [1, 2], year: int = 2021, color: str = "yellow"):
for month in months:
etl_web_to_gcs(year, month, color)
if __name__ == "__main__":
color = "yellow"
months = [1, 2, 3]
year = 2021
etl_parent_flow(months, year, color)

deployment는 스트림을 캡슐화하고 API를 통해 일정을 예약하거나 시작할 수 있는 서버 측 아티팩트입니다. flow는 여러 배포에 속할 수 있으며 프로그래밍하는 데 필요한 모든 것이 포함된 메타데이터가 있는 컨테이너라고 말할 수 있습니다 . 명령줄이나 Python으로 만들 수 있습니다.
Prefect 워크플로에 대한 배포 생성은 Prefect API를 통해 워크플로를 관리하고 Prefect 에이전트에서 원격으로 실행할 수 있도록 워크플로 코드, 설정 및 인프라 구성을 패키징하는 것을 의미합니다.
prefect deployment build parameterized_flows.py:etl_parent_flow -n "Parameterized ETL"
배포 하려고 했을 때 Script at './parameterized_flows.py' encountered an exception: FileNotFoundError(2, 'No such file or directory') 다음과 같은 에러가 발생했습니다. 이를 해결하기 위해서 기존 경로를 worflow_orchestration으로 옮겼서 배포했습니다.

- 배포 결과로 yaml 파일이 생성되었습니다.

###
### A complete description of a Prefect Deployment for flow 'etl-parent-flow'
###
name: Parameterized ETL
description: null
version: 5a09a6eee86fd216605c8f0e27ca82c6
# The work queue that will handle this deployment's runs
work_queue_name: default
work_pool_name: null
tags: []
parameters: {}
schedule: null
is_schedule_active: null
infra_overrides: {}
infrastructure:
type: process
env: {}
labels: {}
name: null
command: null
stream_output: true
working_dir: null
block_type_slug: process
_block_type_slug: process
###
### DO NOT EDIT BELOW THIS LINE
###
flow_name: etl-parent-flow
manifest_path: null
storage: null
path: /home/mjs/data-engineering-zoomcamp/week_2_workflow_orchestration
entrypoint: parameterized_flow.py:etl_parent_flow
parameter_openapi_schema:
title: Parameters
type: object
properties:
months:
title: months
default:
- 1
- 2
position: 0
type: array
items:
type: integer
year:
title: year
default: 2021
position: 1
type: integer
color:
title: color
default: yellow
position: 2
type: string
required: null
definitions: null
timestamp: '2023-04-13T14:50:29.732842+00:00'생성된 yaml을 실행시켜줍니다.
prefect deployment apply etl_parent_flow-deployment.yamlPrefect GUI로 이동하고 배포 섹션에서 방금 생성한 항목에 액세스합니다

대기열에 저장되는데 실행 시키기 위해서 prefect agent start --pool default-agent-pool --work-queue default 명령어를 입력합니다.


prefect Agent를 시작하면 Deployment 실행이 시작되는 것이 보입니다.


Schedules & Docker Storage with Infrastructure
워크플로우의 스케줄링 시간을 설정할 수 있습니다.

CLI 환경에서 설정도 가능합니다.
prefect deployment build parameterized_flow.py:etl_parent_flow -n etl2 --cron "0 0 * * *" -aDocker Container
docker-requirementes.txt 파일을 생성해 줍니다.
pandas==1.5.2
prefect-gcp[cloud_storage]==0.2.3
protobuf==4.21.11
pyarrow==10.0.1
pandas-gbq==0.18.1Dockerfile을 설정해 줍니다.
FROM prefecthq/prefect:2.7.7-python3.9
COPY docker-requirements.txt .
RUN pip install -r docker-requirements.txt --trusted-host pypi.python.org --no-cache-dir
COPY flows /opt/prefect/flows
RUN mkdir -p /opt/prefect/data/yellow도커 이미지를 빌드한 뒤에 이미지를 Docker Hub에 게시하기 위해 푸시를 수행합니다.
docker image build -t discdiver/prefect:zoom .
docker image push discdiver/prefect:zoom푸시를 수행할 때 denied: requested access to the resource is denied 에러가 발생했습니다. 도커 이미지를 빌드할때 잘못되어서 다시 시작했습니다.
docker login
docker build -t mjs1995/prefect_cloud:v1 .
docker image push mjs1995/prefect_cloud:v1
도커 컨테이너 blocks 등록을 하려고 했는데 blocks에서 조회가 되지 않습니다.
Prefect blocks에 도커를 등록해줍니다.

pip install prefect-docker
prefect block register -m prefect_docker
등록 결과 조회가 잘 되고 있습니다.

Block Name을 zoom으로 Image는 위에서 빌드했던 이미지를 ImagePullPolicy는 always를 지정합니다.

python flows/03_deployments/docker_deploy.py : 아래의 docker_deploy.py를 만들고 실행시킵니다.
from prefect.deployments import Deployment
from parameterized_flow import etl_parent_flow
from prefect.infrastructure.docker import DockerContainer
docker_block = DockerContainer.load("zoom")
docker_dep = Deployment.build_from_flow(
flow=etl_parent_flow,
name="docker-flow",
infrastructure=docker_block,
)
if __name__ == "__main__":
docker_dep.apply()GUI 환경에서 배포가 잘 생성 되었는지 확인합니다.

프로필에 연결 확인한 뒤에 임시 로컬 API를 시작 시 에이전트가 발생시키는 API로 바꾸기 위해서 prefect config set이 되는는 API의 URL 및 명령과 함께 사용할 API를 구성합니다. 그 후에 prefect agent를 실행합니다.
prefect profiles ls
prefect config set PREFECT_API_URL="http://127.0.0.1:4200/api"
prefect agent start --work-queue "default"
prefect deployment run etl-parent-flow/docker-flow -p "months=[1,2]"
prefect에서 배포할 때 문제가 발생했습니다. prefect.exceptions.ScriptError: Script at 'flows/03_deployments/parameterized_flow.py' encountered an exception: FileNotFoundError(2, 'No such file or directory')

에러를 해결 하기 위해서 아래와같이 도커파일을 수정하고 새롭게 이미지를 빌드하고 푸시했습니다.

docker build -t mjs1995/prefect_cloud:v1 .
docker image push mjs1995/prefect_cloud:v1
prefect deployment run etl-parent-flow/docker-flow -p "months=[1,2]"

Reference
데이터 엔지니어링 줌 캠프 깃허브 주소
youtube
DataTalks.Club
data engineering zoomcamp slack
'PJT' 카테고리의 다른 글
| [de zoomcamp] 05_배치 처리 (0) | 2023.05.07 |
|---|---|
| [de zoomcamp] 04_분석 엔지니어링 (0) | 2023.05.07 |
| [de zoomcamp] 03_데이터 웨어하우스 (0) | 2023.05.07 |
| [de zoomcamp] 01_소개 및 사전 준비 사항 (0) | 2023.04.30 |
| [de zoomcamp] Data Engineering Zoomcamp 소개 (0) | 2023.04.30 |
