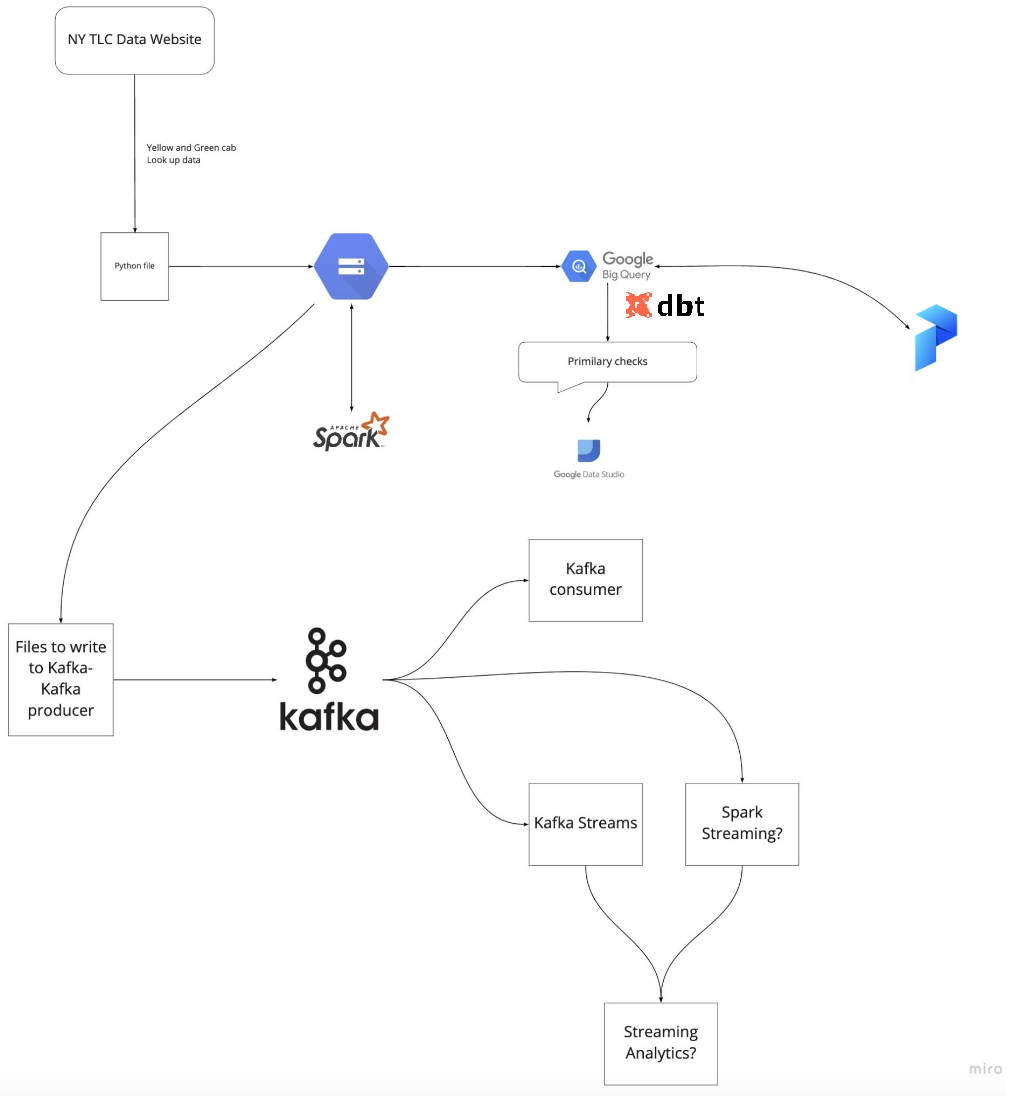
데이터 엔지니어링 줌 캠프 PJT를 진행하면서 관련된 내용을 정리하고자 합니다.
프로젝트의 코드는 github에서 확인할 수 있습니다.
https://github.com/mjs1995/data-engineering-zoomcamp/tree/main/05_batch_processing
GitHub - mjs1995/data-engineering-zoomcamp: PJT
PJT. Contribute to mjs1995/data-engineering-zoomcamp development by creating an account on GitHub.
github.com
Dataproc
Cloud Dataproc이란?

- 클라우드 네이트브 아파치 하둡 및 아파치 스파크 서비스
- 완전 관리형 클라우드 서비스이기에 더 간단하고 효율적으로 하둡 및 스파크 클러스터를 생성할 수 있습니다. 환경 구축을 위해서 몇 시간에서 며칠씩 걸리던 작업이 몇 분에서 몇 초만에 끝나게 됩니다.
- 클러스터 배포, 로깅, 모니터링과 같은 관리는 GCP에서 자동으로 지원해 주기 때문에 직접 인프라 관리를 할 필요 없이 사용자는 작업과 데이터에 집중할 수 있으며, 언제든 클러스터를 만들고 다양한 가상 머신 유형, 디스크 크기, 노드 수, 네트워킹 옵션 등 여러 리소스를 최적화하고 확장할 수 있습니다.
- 다수의 마스터 노드를 사용해 클러스터를 실행하고 실패해도 다시 시작되도록 설정을 할 수 있기 때문에 높은 가용성을 보장합니다. 사용하기 쉬운 Web UI, Cloud SDK, RESTful API 등 다양한 방식으로 클러스터를 관리할 수 있습니다.
- 클러스터 모드
- 단일 노드(마스터 1, 작업자 0) : 마스터 노드 하나만 설정함
- 표준 (마스터 1, 작업자 N) : 마스터 노드 1개와 작업자 노드 N개를 설정함
- 고가용성 (마스터 3, 작업자 N) : 마스터 노드 3개와 작업자 노드 N개를 설정함
- Dataproc은 대규모 데이터 처리 작업을 쉽고 빠르게 수행할 수 있는 Google Cloud 서비스로 대량의 데이터를 병렬로 처리할 수 있는 도구입니다.
- Dataproc을 사용하면 클라우드 컴퓨팅 클러스터를 만들고 일괄 처리, 분석, 머신러닝과 같은 데이터 처리 작업을 실행할 수 있습니다.
gcp 상에서 Dataproc을 검색한 뒤에 API를 활성화합니다.

Compute Engine의 신규 클러스터를 생성해 줍니다.

Compute Engine 클러스터를 만들어 줍니다.

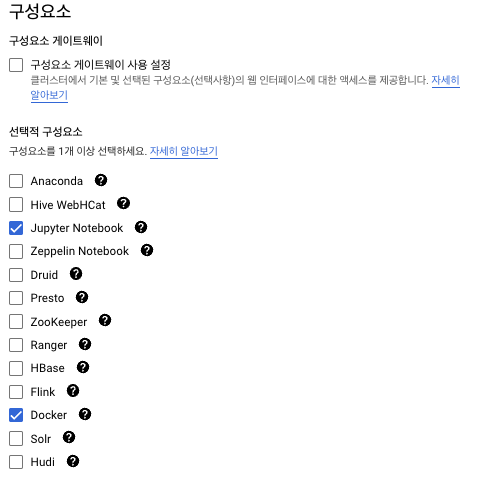
단일 노드를 선택하고 jupyter notebook과 Docker를 구성요소로 포함해 준 뒤 클러스터를 생성해 줍니다.

Spark Job 실행
Dataproc에서 spark 코드를 제출하려고 합니다. 전체 코드는 다음과 같습니다.
#!/usr/bin/env python
# coding: utf-8
import argparse
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
parser = argparse.ArgumentParser()
parser.add_argument('--input_green', required=True)
parser.add_argument('--input_yellow', required=True)
parser.add_argument('--output', required=True)
args = parser.parse_args()
input_green = args.input_green
input_yellow = args.input_yellow
output = args.output
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
df_green = spark.read.csv(input_green, header=True, inferSchema=True)
df_green = df_green \
.withColumnRenamed('lpep_pickup_datetime', 'pickup_datetime') \
.withColumnRenamed('lpep_dropoff_datetime', 'dropoff_datetime')
df_yellow = spark.read.csv(input_yellow, header=True, inferSchema=True)
df_yellow = df_yellow \
.withColumnRenamed('tpep_pickup_datetime', 'pickup_datetime') \
.withColumnRenamed('tpep_dropoff_datetime', 'dropoff_datetime')
common_colums = [
'VendorID',
'pickup_datetime',
'dropoff_datetime',
'store_and_fwd_flag',
'RatecodeID',
'PULocationID',
'DOLocationID',
'passenger_count',
'trip_distance',
'fare_amount',
'extra',
'mta_tax',
'tip_amount',
'tolls_amount',
'improvement_surcharge',
'total_amount',
'payment_type',
'congestion_surcharge'
]
df_green_sel = df_green \
.select(common_colums) \
.withColumn('service_type', F.lit('green'))
df_yellow_sel = df_yellow \
.select(common_colums) \
.withColumn('service_type', F.lit('yellow'))
df_trips_data = df_green_sel.unionAll(df_yellow_sel)
df_trips_data.registerTempTable('trips_data')
df_result = spark.sql("""
SELECT
-- Reveneue grouping
PULocationID AS revenue_zone,
date_trunc('month', pickup_datetime) AS revenue_month,
service_type,
-- Revenue calculation
SUM(fare_amount) AS revenue_monthly_fare,
SUM(extra) AS revenue_monthly_extra,
SUM(mta_tax) AS revenue_monthly_mta_tax,
SUM(tip_amount) AS revenue_monthly_tip_amount,
SUM(tolls_amount) AS revenue_monthly_tolls_amount,
SUM(improvement_surcharge) AS revenue_monthly_improvement_surcharge,
SUM(total_amount) AS revenue_monthly_total_amount,
SUM(congestion_surcharge) AS revenue_monthly_congestion_surcharge,
-- Additional calculations
AVG(passenger_count) AS avg_montly_passenger_count,
AVG(trip_distance) AS avg_montly_trip_distance
FROM
trips_data
GROUP BY
1, 2, 3
""")
df_result.coalesce(1) \
.write.parquet(output, mode='overwrite')Dataproc 클러스터를 선택한 뒤에 작업을 제출해 줍니다.
작업 유형인 Pyspark, 기본 Python 파일에는 gcs에 있는. py 코드를 지정해 줍니다.
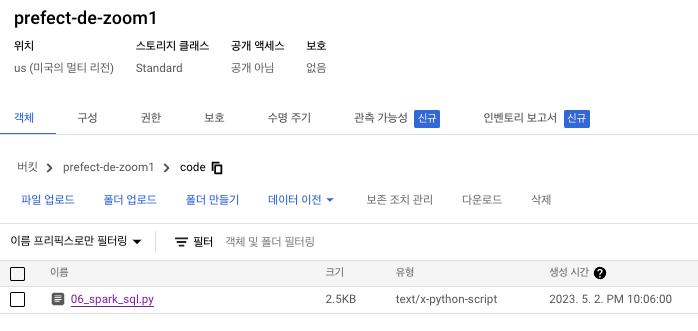
코드를 짤 때 만들어줬던 argument 부분도 넣어줍니다.
--input_green=gs://prefect-de-zoom1/data/green/*/
--input_yellow=gs://prefect-de-zoom1/data/yellow/*/
--output=gs://prefect-de-zoom1/report-2020
해당 작업을 제출하면 모니터링과 로그를 확인할 수 있습니다.
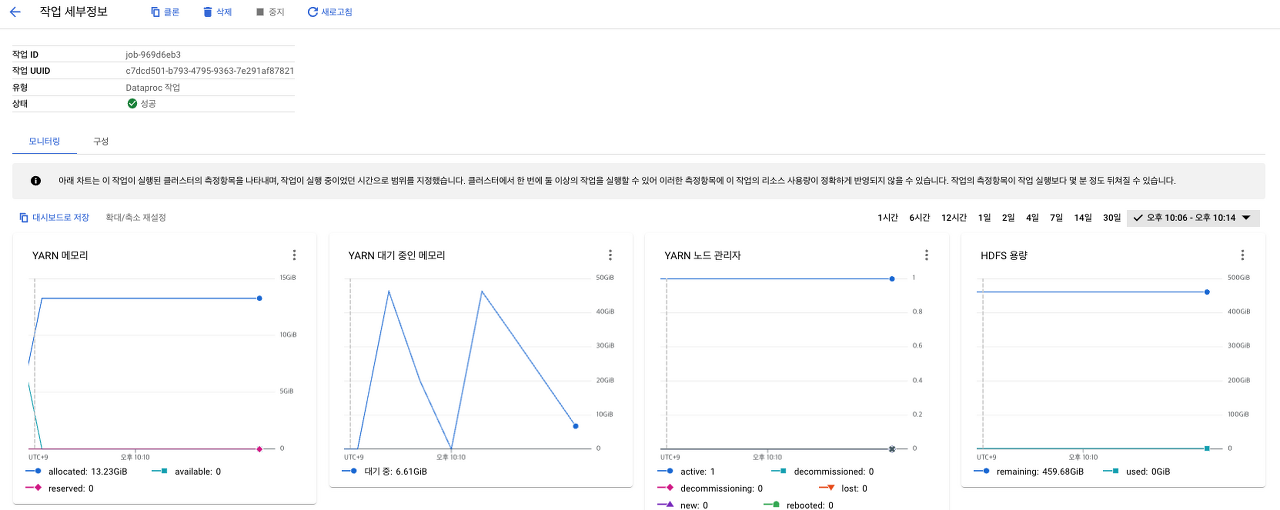
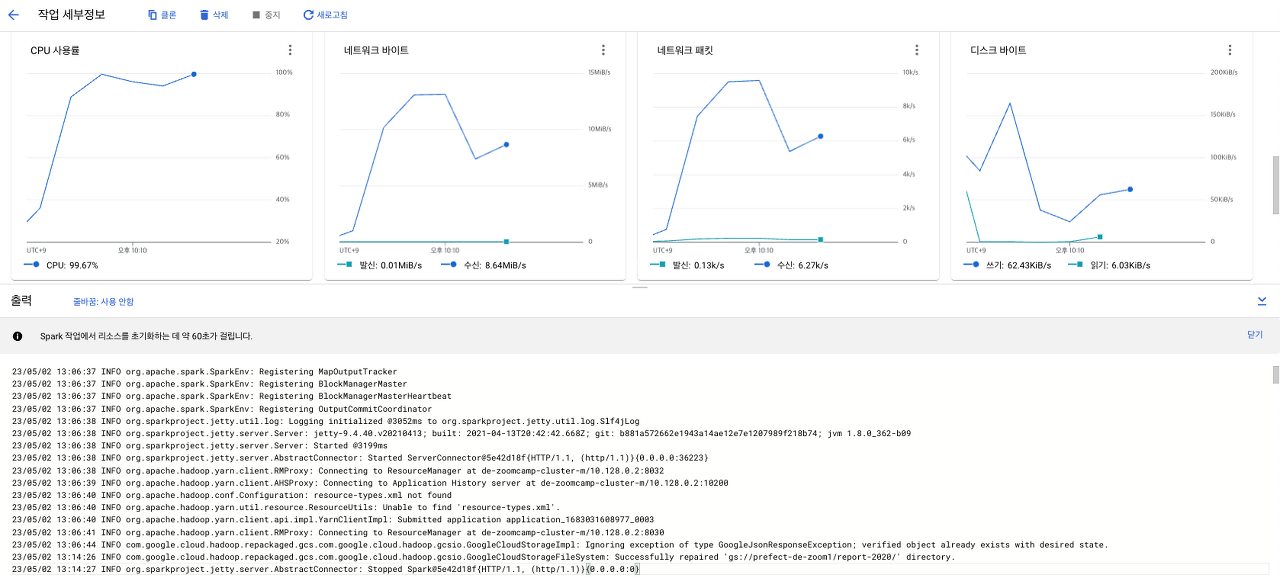
해당 Job의 결과로 parquet 파일이 잘 생성된 것을 확인할 수 있습니다.

gcloud SDK로 Spark 작업 실행
IAM에서 서비스 계정에서 Dataproc 관리자 역할을 부여해 줍니다.

Dataproc 클러스터에서 완료한 작업 세부내역에서 동등한 REST를 클릭해 주고 argument를 확인해 줍니다.
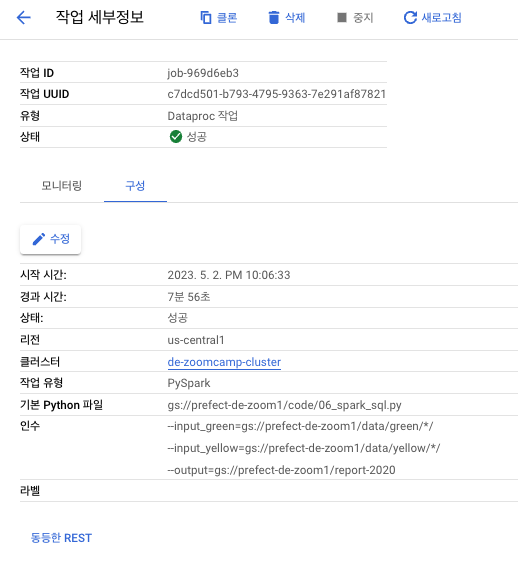

작업 제출 해당 가이드 문서를 참고하시면 됩니다.
gcloud 명령어를 이용하여 spark job을 submit 해줍니다.
gcloud dataproc jobs submit pyspark \
--cluster=de-zoomcamp-cluster \
--region=us \
gs://prefect-de-zoom1/code/06_spark_sql.py \
-- \
--input_green=gs://prefect-de-zoom1/data/green/*/ \
--input_yellow=gs://prefect-de-zoom1/data/yellow/*/ \
--output=gs://prefect-de-zoom1/report-2020gcloud dataproc을 이용해서 Big Query 연동
기존의 코드에서 spark.write부분을 bigquery로 변경해 줍니다.
df_result.write.format('bigquery') \
.option('table', output) \
.save()BigQuery 커넥터를 Spark와 함께 사용 해당 가이드 문서를 참고하시면 됩니다.
gcloud 명령어를 이용하여 spark job을 submit 해 준 뒤에 빅쿼리에서 테이블로 확인할 수 있습니다.
gcloud dataproc jobs submit pyspark \
--cluster=de-zoomcamp-cluster \
--region=us \
--jars=gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
gs://prefect-de-zoom1/code/06_spark_sql_big_query.py \
-- \
--input_green=gs://prefect-de-zoom1/data/green/*/ \
--input_yellow=gs://prefect-de-zoom1/data/yellow/*/ \
--output=gs://prefect-de-zoom1/report-2020Reference
데이터 엔지니어링 줌 캠프 깃허브 주소
youtube
DataTalks.Club
data engineering zoomcamp slack
'PJT' 카테고리의 다른 글
| [OSSCA 2023] python-mysql-replication (0) | 2023.09.25 |
|---|---|
| [de zoomcamp] 06_스트리밍 (0) | 2023.05.21 |
| [de zoomcamp] 04_분석 엔지니어링 (0) | 2023.05.07 |
| [de zoomcamp] 03_데이터 웨어하우스 (0) | 2023.05.07 |
| [de zoomcamp] 02_워크플로 오케스트레이션 (0) | 2023.05.01 |
