PR 내용
본 포스팅에서는 Python-mysql-replication 프로젝트에 기여한 경험을 공유하고 있습니다. 문서 업데이트, 버그 수정, 그리고 기능 개발 세 가지 분야에서의 기여 과정과 결과를 소개하고자 합니다.

docs: Update README to add Featured Books
Add Featured Section in README
Update README Featured Section with AWS Blog on RDS, XA Transactions
Remove duplicated Affected columns output in UpdateRowsEvent
Developed UserVarEvent and Added Statement-Based Logging Test
Enhance Testing with MySQL8 & Update GitHub Actions
문서기여
데이터 파이프라인 핵심 가이드 책을 읽었을 때 CDC 부분과 binlog에 대해서 관심이 있었던 부분이 있어서 읽을 당시에는 몰랐지만 이번에 OSSCA를 진행하면서 python-mysql-replication이 사용되었다는 것을 알게 되었습니다. 관련하여 멘토님과 얘기를 하다가 프로젝트 주인장분이 프로젝트의 쓰임새에 대해서 관심이 많아서 알려드리면서 README를 업데이트를 하는 건 어떠냐고 물어보았습니다.

O'REILLY에 소개되었던 프로젝트에 대해서 긍정적으로 반응을 하셔서 첫 프로젝트 PR은 docs: Update README to add Featured Books로 시작을 하게 되었습니다.
docs: Update README to add Featured Books by mjs1995 · Pull Request #413 · julien-duponchelle/python-mysql-replication
Overview This PR aims to augment the README with a "Featured Books" section, highlighting our project's mention in the book “Data Pipelines Pocket Reference”, published by O'Reilly. Our project is...
github.com
프로젝트를 진행하면서 책에서 소개된 내용뿐만 아니라 공신력 있는 기술블로그에 대한 소개 내용도 관심이 있어서 AWS의 사례에 대해서 추가를 하게 되었습니다. 최근에 AWS Summit 2023과 AWS Data Roadshow 2023 세미나를 다녀오면서 기술블로그와 aws-sample 깃허브가 생각이 났었고 저희 프로젝트에 대해 소개를 하고 있는 내용이 있어서 위 내용 모두 PR을 올렸습니다.
Add Featured Section in README by mjs1995 · Pull Request #457 · julien-duponchelle/python-mysql-replication
This PR updates the "Featured" section of the README to include a mention of our project being showcased in 'Near Zero Downtime Migration from MySQL to DynamoDB' by YongSeong Lee from Amazon Web Se...
github.com
Update README Featured Section with AWS Blog on RDS, XA Transactions by mjs1995 · Pull Request #485 · julien-duponchelle/pytho
PR Description: This PR updates the README's "Featured" section by adding a new AWS blog post. The post details the use of Amazon RDS, XA transactions, Amazon Kinesis, and AWS Lambda for data repli...
github.com
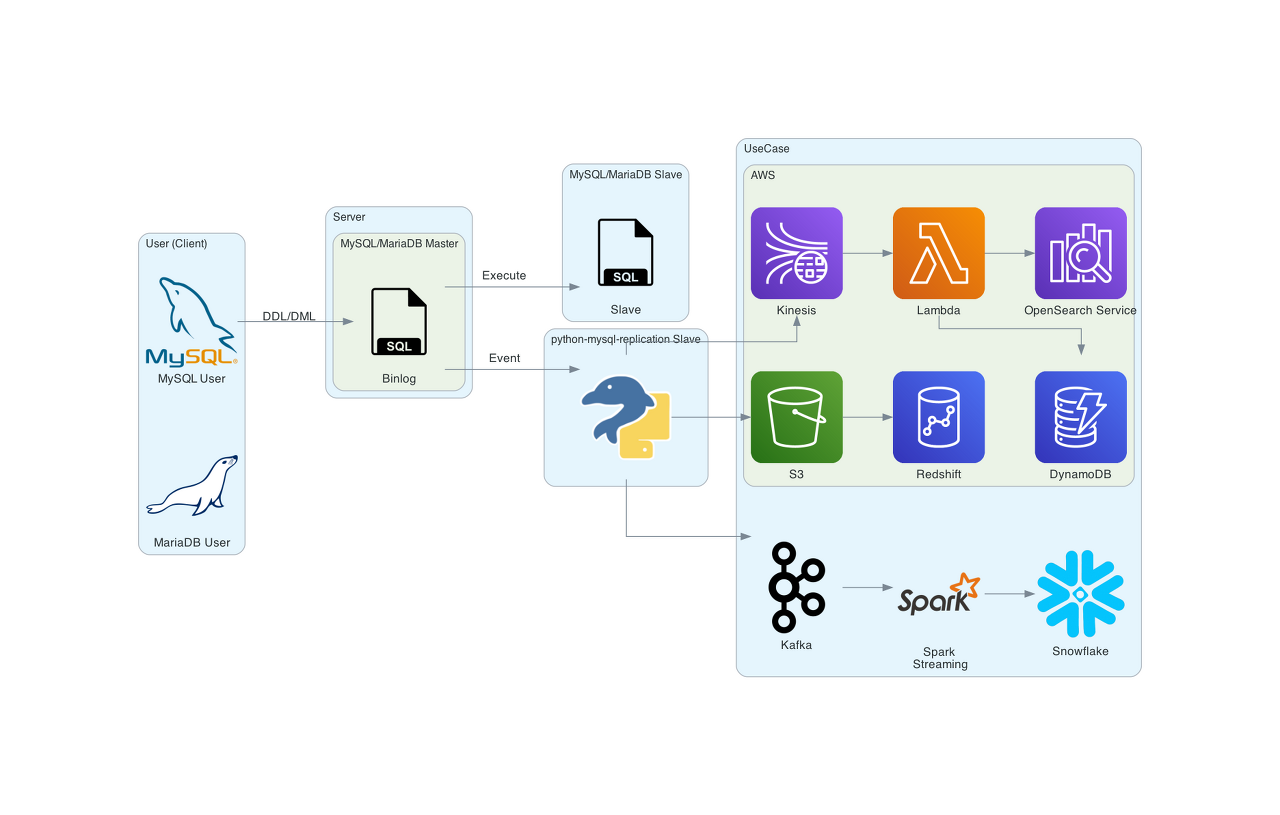
이를 바탕으로 python-mysql-replicatino은 여러 기업에서 사용하고 있지만 snowflake 기술 블로그나 AWS에 소개된 내용으로 아키텍처를 그려보았습니다.
버그 수정
python-mysql-replication에서 이벤트 구현에 대한 기능개발을 하고 있을 때 UpdateRowsEvent에 대해서 Affected columns이 중복되어서 나타나고 있었습니다. 커밋이력을 확인한 뒤에 소스코드를 분석하였습니다.
BinLogEvent
|
└── RowsEvent
|
└── UpdateRowsEventRowsEvent는 BinLogEvent를 상속받아 행 기반 이벤트를 처리하고 UpdateRowsEvent는 RowsEvent를 상속받아 업데이트 이벤트를 처리하는데 _dump 메소드에서 "Affected columns" 상속되는 게 중복으로 출력이 되고 있어서 PR을 올렸습니다.
Remove duplicated Affected columns output in UpdateRowsEvent by mjs1995 · Pull Request #478 · julien-duponchelle/python-mysql-
Overview This Pull Request aims to remove the duplicate "Affected columns" output in the UpdateRowsEvent class. Description The _dump() method in both RowsEvent and UpdateRowsEvent classes includes...
github.com
기능개발
UserVarEvent 신규 이벤트 구현
UserVarEvent 클래스는 사용자 변수 이벤트의 세부 사항을 추출하기 위해 버퍼를 파싱하고 그 타입에 따라 값을 읽는 메서드를 제공합니다
이벤트와 관련해서 버퍼 레이아웃과 클래스 속성을 공식 문서에서 확인할 수 있습니다.
- UserVarEvent 버퍼 레이아웃
+-------------------------------------------------------------------+
| name_len | name | is_null | type | charset_number | val_len | val |
+-------------------------------------------------------------------+- UserVarEvent 클래스의 속성
- name_len: 사용자 변수 이름의 길이
- name: 사용자 변수의 이름
- is_null: 변수 값이 null인지 여부를 나타냅니다.
- type: 사용자 변수의 타입
- charset: 사용자 변수의 문자 집합 번호
- value_len: 사용자 변수의 값의 길이
- value: 사용자 변수의 값
생성자에서의 버퍼 파싱
- UserVarEvent 클래스의 init 메서드는 이 버퍼 레이아웃을 파싱하는 역할을 합니다. 레이아웃에서 설명한 순서대로 값을 읽고 클래스의 해당 속성에 할당합니다.
- 타입 처리 및 값 추출
- 여기서 사용자 변수의 타입별로 버퍼를 파싱하는 값이 달라집니다.
| Value | Type | Example |
| 0x00 | STRING_RESULT | set @a:="foo" |
| 0x01 | REAL_RESULT | set @a:=@@timestamp |
| 0x02 | INT_RESULT | set @a:=4 |
| 0x03 | ROW_RESULT | (not in use) |
| 0x04 | DECIMAL_RESULT |
set @a:=1.2345 |
- type_to_codes_and_method 딕셔너리는 타입 코드와 해당 데이터 추출 메서드 (_read_string, _read_real, _read_int, _read_decimal, _read_default)를 매핑하는 데 사용됩니다. 타입 코드에 따라 특정 메서드가 호출되어 버퍼에서 값을 파싱합니다.
- 타입별로 매핑하는 방법에 대해 말씀드리겠습니다.
struct.unpack("<B", ...)- struct 모듈의 unpack 함수는 주어진 형식에 따라 바이트 데이터를 언팩(해석)합니다.
- "<B"는 리틀 엔디안 형식의 부호 없는 1바이트 정수(unsigned char)를 나타냅니다. <는 리틀 엔디안을 나타냅니다. (리틀 엔디안은 바이트 순서가 오른쪽에서 왼쪽으로 간다는 것을 의미합니다.)
- B는 부호 없는 1바이트 정수(unsigned char)를 나타냅니다.
- 엔디언에서 빅 엔디언은 사람이 숫자를 쓰는 방법과 같이 큰 단위의 바이트가 앞에 오는 방법이고, 리틀 엔디언은 반대로 작은 단위의 바이트가 앞에 오는 방법입니다.
버퍼 레이아웃을 파싱할 때 int type과 decimal type에 대해서 이슈가 있었습니다.
int
- MySQL에서 BIGINT UNSIGNED와 BIGINT의 범위는 다음과 같습니다.
- BIGINT UNSIGNED: 0 to 18,446,744,073,709,551,615
- BIGINT: -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807
- 현재 mysql에서 UNSIGNED일때 18446744073709551615이 -1로 반환되는 이슈가 있었습니다. 관련해서는 mysql 리포트와 mysql 공식 문서 문서를 참고하시면 될 거 같습니다.
mysql> SELECT CAST(1-2 AS UNSIGNED)
-> 18446744073709551615
mysql> SELECT CAST(CAST(1-2 AS UNSIGNED) AS SIGNED);
-> -1
mysql> select cast(-1 as unsigned);
+----------------------+
| cast(-1 as unsigned) |
+----------------------+
| 18446744073709551615 |
+----------------------+
1 row in set (0.00 sec)- -1로 나오는 이슈를 어떻게 처리할지 고민하며 바이트 덤프를 기반으로 데이터를 파싱해 봤습니다.
00 26 11 EE 64 0E 01 00 00 00 2F 00 00 00 15 0A .&..d...../.....
00 00 00 00|01 00 00 00|61|00|02|FF 00 00 00|08 ........a.......
00 00 00|FF FF FF FF FF FF FF FF|01|16 25 04 29 .............%.)- name_len: 01 00 00 00 → 리틀 엔디안 형식으로 1입니다.
- name: 61 → ASCII로 'a'입니다.
- is_null: 00 → False입니다.
- type: 02 → INT_RESULT입니다.
- charset: FF 00 00 00 → 생략됩니다.
- val_len: 08 00 00 00 → 값의 길이는 8바이트입니다.
- val: FF FF FF FF FF FF FF FF → 18446744073709551615입니다.
- flag: 01 → UNSIGNED_F입니다.
바이트 덤프를 기반으로 데이터를 파싱을 했을 때 flag가 01일 때 UNSIGNED로 이를 기반으로 int 타입을 파싱하였습니다. 따라서 flags를 활용하기 위해 임시버퍼를 사용하였고 flag가 1일 때와 아닐 때를 리틀 엔디안을 활용해 unsinged와 singed를 구분해서 언패킹하였습니다.
deciaml
- 내부 패킷 객체를 사용하여 데이터를 읽으려고 했지만 위에 int 타입의 경우 flags를 활용해야 하므로, 임시 버퍼를 사용해서 바이트를 받아서 decimal로 파싱을 하는 메소드를 개발해야 했습니다. deciaml은 음수일때와 양수일때를 구분해서 파싱을 했고 음수일때 기존 코드에서 -4444.2343243245 의 경우 XOR 연산사 byte 범위 벖어나서 0-255 범위로 제한 하였습니다.
charset에 대해서도 mysql5.7, mysql8, mariadb에서 매번 바뀌는 이슈가 있었습니다.
- 이는 환경설정에서 charset과 collation에 영향을 받는 것을 확인했습니다.
- MySQL은 다양한 문자셋을 지원하며, 그중 여러 유니코드 문자셋을 포함하고 있습니다. 콜레이션은 특정 문자셋의 문자들을 어떻게 비교하고 정렬할지를 결정하는 규칙의 집합입니다.
- 사용 가능한 문자셋을 확인하려면 INFORMATION_SCHEMA CHARACTER_SETS 테이블 또는 SHOW CHARACTER SET 문장을 사용할 수 있으며 사용 가능한 콜레이션을 확인하려면 INFORMATION_SCHEMA COLLATIONS 테이블 또는 SHOW COLLATION 문장을 사용할 수 있습니다. 관련해서는 공식 문서를 확인해 주시면 될 거 같습니다.
- Database를 생성할 때 문자셋과 콜레이션을 지정하면 같은 값을 반환하는 것을 확인했습니다.
mysql> CREATE DATABASE test CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci;
Query OK, 1 row affected (0.02 sec)
mysql> SHOW VARIABLES LIKE 'character_set%';
+--------------------------+-------------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/percona-server/charsets/ |
+--------------------------+-------------------------------------+
8 rows in set (0.03 sec)
| mysql-bin.000003 | 5082 | User var | 1 | 5135 | @`test_user_var`=_latin1 0x666F6F COLLATE latin1_swedish_ci |
mysql> SET NAMES 'utf8mb3';
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW VARIABLES LIKE 'character_set%';
+--------------------------+-------------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/percona-server/charsets/ |
+--------------------------+-------------------------------------+
8 rows in set (0.03 sec)squash merge를 통해서 압축해서 커밋을 한 뒤에 PR을 올렸습니다.
Developed UserVarEvent and Added Statement-Based Logging Test by mjs1995 · Pull Request #466 · julien-duponchelle/python-mysql
Overview This Pull Request introduces the UserVarEvent class, aimed at providing robust handling for MySQL/MariaDB binary log events related to user variables. To validate the effectiveness of this...
github.com
'PJT' 카테고리의 다른 글
| [OSSCA 2023] python-mysql-replication 프로젝트에 기여하기 - 02 : github action pytest (0) | 2023.10.04 |
|---|---|
| [OSSCA 2023] python-mysql-replication (0) | 2023.09.25 |
| [de zoomcamp] 06_스트리밍 (0) | 2023.05.21 |
| [de zoomcamp] 05_배치 처리 (0) | 2023.05.07 |
| [de zoomcamp] 04_분석 엔지니어링 (0) | 2023.05.07 |
