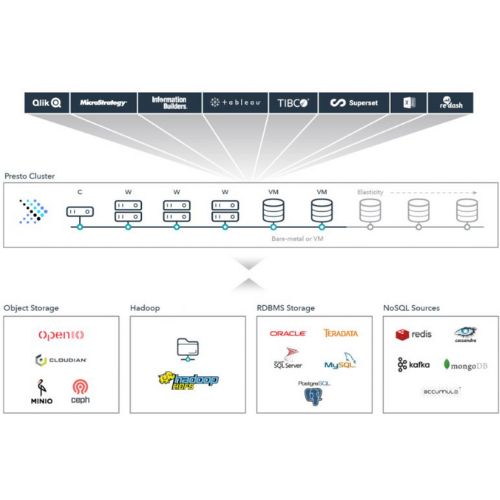
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/presto_base.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Presto Presto는 기가바이트에서 페타바이트에 이르는 다양한 데이터 소스에 대해 빠른 분석 쿼리를 실행하기 위한 오픈 소스 분산 SQL 엔진입..
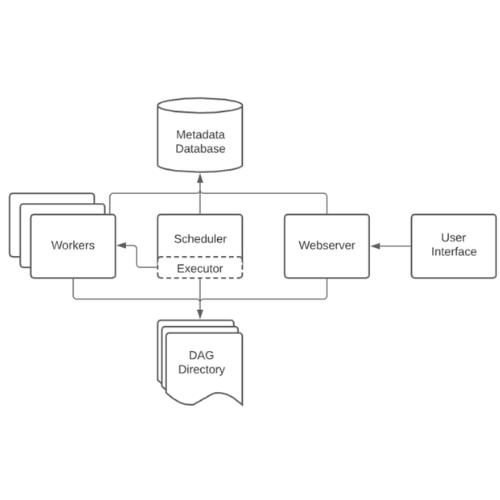
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/airflow_architecture.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com 아키텍처 Airflow는 크게 다음과 같은 컴포넌트들로 구성되어 있습니다. DAG Directory 파이썬으로 작성된 DAG 파일을 저장하는 공간입니다..
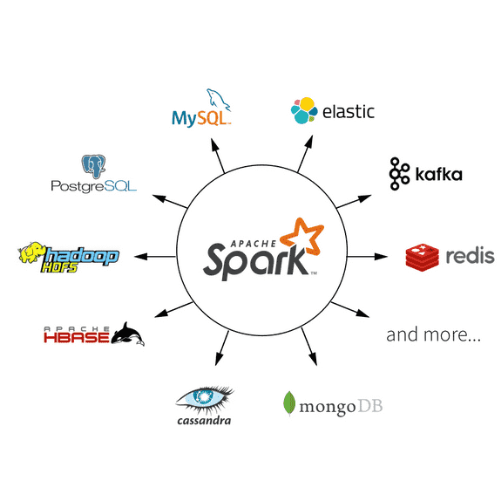
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_optimization.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com 최적화 Spark 에는 최적화 기능들(optimizer) 을 갖추고 있습니다. 1.x 버전에서는 Rule-Based Optimizer만 ..
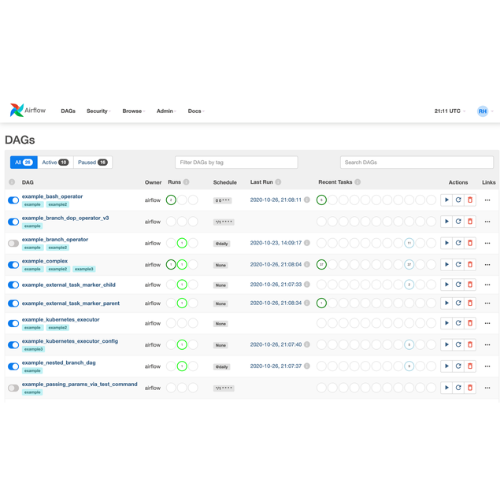
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/airflow_base.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Airflow Airflow는 파이썬으로 배치, 스케줄링, 모니터링 등을 한 번에 해결하는 워크플로 관리 플랫폼입니다. 일상적인 tasks 는 airflow를 통해서..
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. RDD 사용 자제 Spark 작업의 경우 RDD보다 Dataset/DataFrame을 Dataset으로 사용하는 것이 좋습니다. DataFrame에는 Spark 워크로드의 성능을 개선하기 위한 여러 최적화 모듈이 포함되어 있습니다. PySpark 사용에서 Dataset의 RDD를 통한 DataFrame은 PySpark 애플리케이션에서 지원되지 않습니다. RDD를 사용하면 스파크가 최적화 기술을 적용하는 방법을 모르기 때문에 성능 문제가 직접 발생하고 RDD는 클러스터에 분산(재파티션 및 셔플링)할 때 데이터를 직렬화 및 역직렬화합니다.. 직렬화 및 역직렬화는 Spark 애플리케이션 또는 모든 분산 시스템에서..

Data Warehouse, Data Lake, Data Fabric의 비교를 공부하다가 이 책을 읽게 되었습니다. 데이터 민주화란 데이터에 쉽게 접근할 수 있도록 기반을 만들어 데이터를 잘 아는 사람부터 잘 모르는 사람까지 누구나 데이터를 쉽게 사용해 인사이트를 도출할 수 있도록 하는 것을 의미하고 셀프서비스 데이터란 데이터 엔지니어나 데이터 과학자가 관여하지 않더라도 마케터, 사업 담당자, 서비스 운영 담당자 등 조직 내 모든 사람이 스스로 데이터에 접근해 인사이트를 추출할 수 있도록 만들어진 데이터 기반을 의미합니다. - 이 책은 원시 데이터에서 인사이트로의 여정 지도인 발견, 준비, 구축, 운영화에 이르기까지의 내용을 담고 있으며 인사이트 시간 스코어가드를 사용하여 18개의 지표의 내용을 담고 있..

Kimball의 다차원 모델링에 대해 공부하던 중 DW에 관심을 가지게 되었고 DW와 Data Lake, Data Fabric의 차이에 대해서 공부를 하게 되었습니다. 공부를 하면서 데이터 레이크에 대해 조금 더 자세하게 알아보고자 이 책을 선택하게 되었습니다. - 이 책은 데이터 레이크의 아키텍처와 장점, 데이터 레이크를 도입할 때의 어려움과 그런 어려움을 극복하는 방법에 대해 설명하고 있습니다. - 이 책은 데이터 레이크를 데이터 웅더이(분석적인 샌드박스)나 데이터 연못(큰 데이터 웨어하우스)을 바탕으로 확장할 때 활용할 수 있는 여러 접근법뿐만 아니라 아예 바닥부터 구축하는 방법까지 다룸. 사내, 클라우드 기반, 가상 등 다양한 데이터 레이크 아키텍처의 장단점을 살펴보고 있습니다. 미가공, 처리되지..

Hive와 Presto 쿼리 엔진을 이용하여 데이터 플랫폼에서 ELT를 담당하고 있습니다. 하둡 완벽 가이드에서 하이브에 대해 간략하게 봤지만 운영하면서 궁금했던 점이나 하이브의 쿼리 처리를 하는 데 있어서 디테일하게 보고자 이 책을 선택하게 되었습니다. 책의 목차를 봤을 때 배울 점이 많을 거 같다는 생각과 함께 선배가 하이브 책 중에서 이 책을 추천해서 절판 상태였지만 중고서적으로 겨우 구해서 읽었습니다. 하이브뿐만 아니라 하둡의 생태계까지 재밌게 읽으면서 봤습니다. - 이 책은 데이터 모델링부터 쿼리, 색인, 튜닝, 함수, 스토리지 핸들러, HCatalog 등의 고급 기능까지 총망라하여 제공하고 있습니다. - 이 책의 목적은 개발자, 데이터베이스 관리자, 아키텍트는 물론이고 비즈니스 분석가처럼 기술..