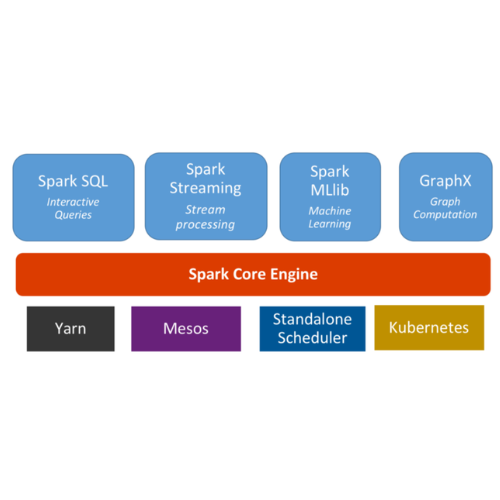
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_cluster_manager.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Spark 클러스터 스파크는 마스터/슬레이브 구조를 사용하며, 중앙 조정자인 드라이버와 여러 분산 작업 노드인 익스큐터로 구성됩니다..
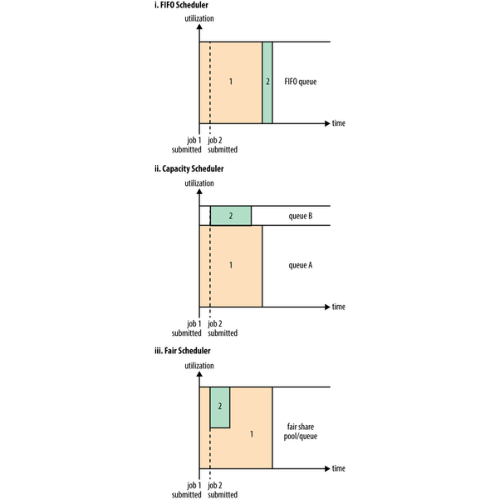
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_yarn.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com YARN YARN을 사용하면 그래프 처리, 대화형 처리, 스트림 처리, 일괄 처리와 같은 다양한 데이터 처리 방법을 통해 HDFS에 저장된 데이터를 실..
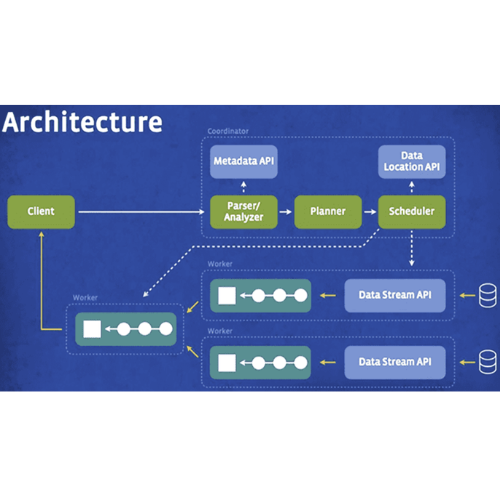
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/trino_base.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Trino 2012년 Martin Traverso , David Phillips, Dain Sundstrom 및 Eric Hwang은 Facebook ..
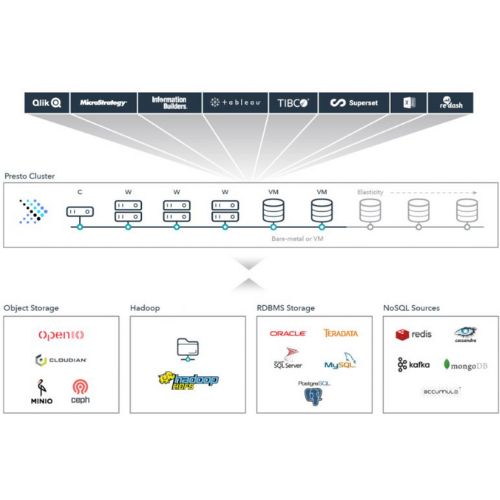
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/presto_base.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Presto Presto는 기가바이트에서 페타바이트에 이르는 다양한 데이터 소스에 대해 빠른 분석 쿼리를 실행하기 위한 오픈 소스 분산 SQL 엔진입..
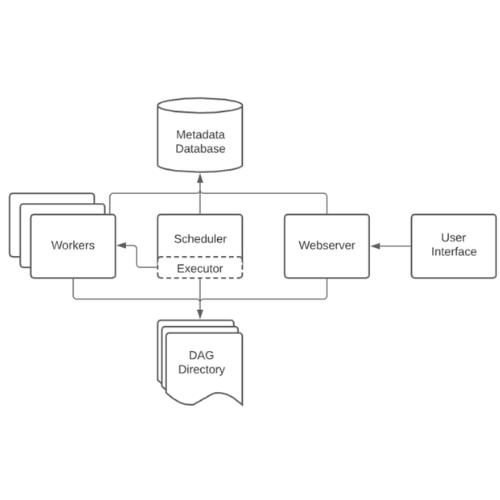
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/airflow_architecture.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com 아키텍처 Airflow는 크게 다음과 같은 컴포넌트들로 구성되어 있습니다. DAG Directory 파이썬으로 작성된 DAG 파일을 저장하는 공간입니다..
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_optimization.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com 최적화 Spark 에는 최적화 기능들(optimizer) 을 갖추고 있습니다. 1.x 버전에서는 Rule-Based Optimizer만 ..
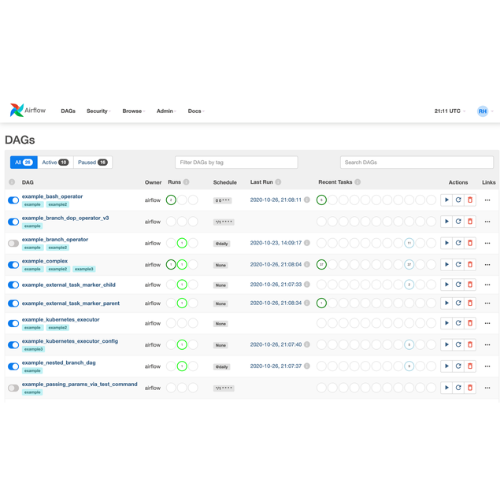
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/airflow_base.md GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기 데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub. github.com Airflow Airflow는 파이썬으로 배치, 스케줄링, 모니터링 등을 한 번에 해결하는 워크플로 관리 플랫폼입니다. 일상적인 tasks 는 airflow를 통해서..
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다. 개인적인 기록을 위해 작성하였습니다. RDD 사용 자제 Spark 작업의 경우 RDD보다 Dataset/DataFrame을 Dataset으로 사용하는 것이 좋습니다. DataFrame에는 Spark 워크로드의 성능을 개선하기 위한 여러 최적화 모듈이 포함되어 있습니다. PySpark 사용에서 Dataset의 RDD를 통한 DataFrame은 PySpark 애플리케이션에서 지원되지 않습니다. RDD를 사용하면 스파크가 최적화 기술을 적용하는 방법을 모르기 때문에 성능 문제가 직접 발생하고 RDD는 클러스터에 분산(재파티션 및 셔플링)할 때 데이터를 직렬화 및 역직렬화합니다.. 직렬화 및 역직렬화는 Spark 애플리케이션 또는 모든 분산 시스템에서..

2021년 1년차 데이터사이언티스트 회고록 SI에서 일을 하다보니 그룹사의 다양한 곳으로 파견을 다니면서 일을 한 한 해였습니다. 2021년 회고록을 돌아보며 일상의 루틴과 계획했던 부분에 대해 현재까지 잘 지켜진 부분도 있고 페이퍼 리뷰나 기술블로그 관련해서는 아쉬운 점들도 있는 거 같습니다. 선, 후배, 팀 동료를 만나 사회생활을 많이 배웠으며 2022년에 데이터 엔지니어로 성장을 한 경험을 정리하고 합니다. 데이터 엔지니어로의 실무 이커머스 영역에서 2개의 애플리케이션 데이터 파이프라인을 관리하고 있으며 추천을 위한 데이터 전처리를 하였습니다. 운이 좋겠도 대기업 벤처 프로젝트 현장에 투입되어 AWS 환경 속에서 다양한 툴을 사용해서 경험을 하게 되었습니다. 주요 업무는 데이터 ELT와 BI를 위한..

Data Warehouse, Data Lake, Data Fabric의 비교를 공부하다가 이 책을 읽게 되었습니다. 데이터 민주화란 데이터에 쉽게 접근할 수 있도록 기반을 만들어 데이터를 잘 아는 사람부터 잘 모르는 사람까지 누구나 데이터를 쉽게 사용해 인사이트를 도출할 수 있도록 하는 것을 의미하고 셀프서비스 데이터란 데이터 엔지니어나 데이터 과학자가 관여하지 않더라도 마케터, 사업 담당자, 서비스 운영 담당자 등 조직 내 모든 사람이 스스로 데이터에 접근해 인사이트를 추출할 수 있도록 만들어진 데이터 기반을 의미합니다. - 이 책은 원시 데이터에서 인사이트로의 여정 지도인 발견, 준비, 구축, 운영화에 이르기까지의 내용을 담고 있으며 인사이트 시간 스코어가드를 사용하여 18개의 지표의 내용을 담고 있..