실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/trino_base.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
Trino
- 2012년 Martin Traverso , David Phillips, Dain Sundstrom 및 Eric Hwang은 Facebook 및Facebook이 분석하려고 했던 수백 페타바이트를 더 잘 처리하기 위해 Apache Hive를 대체할 Presto를 개발하였습니다.
- Presto의 원래 제작자는 Presto 오픈 소스를 유지하기로 결정하고 Presto 오픈 소스 커뮤니티 구축을 풀타임으로 추구했습니다. 새로운 이름인 PrestoSQL로 이 작업을 수행하였고 Facebook은 Presto®에 상표를 신청했습니다. 이로 인해 결국 Presto를 개발한 원래 그룹이 브랜드를 변경해야 하는 소송 및 기타 문제가 발생하여 PrestoSQL은 Trino로 리브랜딩했습니다.
- Trino는 SQL 엔진, 여러 유형의 데이터 소스에 대한 임시 및 배치 ETL 쿼리를 위한 오픈 소스 분산 SQL 쿼리 엔진입니다.
- Trino는 기가바이트에서 페타바이트에 이르는 다양한 데이터 소스에 대해 빠른 분석 쿼리를 실행하기 위한 오픈 소스 분산 SQL 엔진입니다.
- Trino는 하나 이상의 이기종 데이터 소스에 분산된 대규모 데이터 세트를 쿼리하도록 설계된 분산 SQL 쿼리 엔진입니다.
- Trino는 대화형 분석을 위해 처음부터 설계 및 제작되었습니다. 매우 큰 조직의 규모로 확장하면서 상용 데이터 웨어하우스의 속도에 접근합니다.
- JSON, 배열 및 맵과 같은 표준 및 반구조화된 데이터 유형의 전체 호스트를 관리할 수 있습니다.
동작
- Trino는 대규모 병렬 처리(MPP) 데이터베이스와 유사한 아키텍처를 활용하는 분산 시스템
- 다른 많은 빅 데이터 엔진과 마찬가지로 수행해야 할 모든 작업을 처리하기 위해 여러 작업자 노드를 관리하는 코디네이터 노드의 형태가 있습니다. Trino는 여러 대의 서버에 병렬로 데이터를 처리하는 분산 쿼리 엔진으로, 단일 코디네이터와 여러 개의 워커로 구성됩니다
- 분석가 또는 일반 사용자는 코디네이터에게 푸시되는 SQL을 실행합니다. 그런 다음 코디네이터는 분산 쿼리를 구문 분석, 계획 및 예약합니다.
- 표준 ANSI SQL 을 지원하고 사용자가 JSON 및 MAP 변환 및 구문 분석과 같은 보다 복잡한 변환을 실행할 수 있습니다.
- 쿼리 상태
- BLOCKED : 쿼리가 차단되고 리소스(버퍼 공간, 메모리, 분할 등)를 기다리고 있습니다.(상태 BLOCKED는 정상이지만 지속적이라면 조사가 필요합니다.)
- 메모리 부족 또는 분할, 디스크 또는 네트워크 I/O 병목 현상, 데이터 왜곡(모든 데이터가 소수의 작업자에게 전달됨), 병렬 처리 부족(몇 명의 작업자만 사용 가능) 또는 지정된 단계를 따르는 쿼리의 계산 비용이 많이 드는 단계 등 많은 잠재적 원인이 있습니다
트리노를 사용하는 이유
- 독립적인 데이터 소스 연결
- 데이터를 쿼리할 수 있는 방법과 관련하여 많은 옵션이 있습니다.(Athena, Hive 및 Apache Drill과 같은 도구가 있음)
- Trino의 가장 큰 장점은 바로 SQL 엔진이라는 것입니다. 즉, MySQL, HDFS 및 SQL Server와 같은 다양한 데이터 소스 위에 불가지론적으로 위치
- 클라우드 중심
- 스토리지와 컴퓨팅을 별도로 실행하는 Presto의 기본 설계는 클라우드 환경에서 운영하는 데 매우 편리합니다.
- Presto 클러스터는 데이터를 저장하지 않기 때문에 데이터 손실 없이 로드에 따라 자동 확장될 수 있습니다.
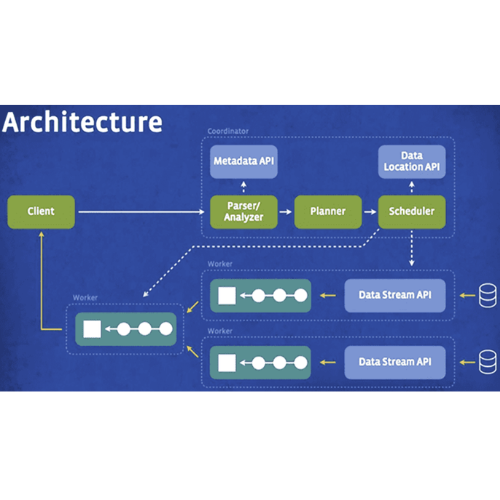
아키텍처

- 아키텍처
- 클러스터: Trino 클러스터는 코디네이터와 여러 개의 워커로 구성됩니다. 코디네이터는 쿼리 실행을 관리하고, 워커는 카탈로그에 구성된 데이터 소스에 액세스하고 각 쿼리를 병렬로 처리합니다.
- 코디네이터: 코디네이터는 SQL 문을 파싱하고 쿼리를 계획하며 Trino 워커 노드를 관리합니다. 쿼리의 논리적 및 물리적인 계획을 생성하며 Trino 워커 클러스터에서 실행되는 일련의 단계와 작업으로 구성됩니다.
- 워커: Trino 워커는 작업을 실행하고 데이터를 처리하며, 커넥터를 통해 데이터 저장소에서 데이터를 가져오고 다른 워커와 중간 데이터를 교환합니다. 코디네이터는 워커로부터 결과를 수집하여 최종 결과를 클라이언트에 반환합니다.
- 외부 저장소에서 데이터를 읽고 SQL 연산을 사용하여 데이터를 처리하며, 다른 Trino 워커와 데이터를 교환하고 데이터를 집계하여 최종 쿼리 결과를 생성하는 역할을 담당합니다.
- 컴퓨팅 파워를 제공하며, Trino 클러스터를 위해 데이터를 로드하는 역할을 담당합니다. 대부분의 경우, 각 워커에 더 많고 강력한 CPU를 장착하면 쿼리를 빠르게 실행할 수 있습니다.
- Trino는 중간 연산 결과를 디스크 대신 메모리에 저장합니다. 일상적인 운영과 유지보수에서는 모든 워커의 메모리를 분산 메모리 자원 풀로 간주할 수 있습니다. 쿼리의 메모리 사용량이 총 메모리 풀을 초과하면 쿼리가 실패하거나 무기한으로 차단될 수 있습니다.
- 커넥터: 커넥터는 Trino를 데이터 소스에 맞게 적용하는 역할을 합니다. Hive 데이터 웨어하우스, 데이터 레이크, 관계형 데이터베이스 등과 같은 데이터 소스에 Trino가 표준 API를 사용하여 상호 작용할 수 있도록 합니다. Trino에는 여러 내장 커넥터가 포함되어 있습니다.
- 카탈로그: Trino는 각 데이터 소스를 카탈로그로 구성하여 데이터에 액세스합니다. SQL 조인을 사용하여 하나의 쿼리 내에서 여러 카탈로그를 쿼리할 수 있습니다. 카탈로그는 Trino 구성 디렉토리에 저장된 속성 파일을 사용하여 구성됩니다.
- 여러 작업자 노드와 동기화되어 작동하는 하나의 코디네이터 노드가 있습니다.
- 사용자는 사용자 지정 쿼리 및 실행 엔진을 사용하여 작업자 노드에서 분산 쿼리 계획을 구문 분석, 계획 및 예약하는 코디네이터에 SQL 쿼리를 제출할 수 있습니다.
- Presto는 복잡한 쿼리, 집계, 조인, 왼쪽/오른쪽 외부 조인, 하위 쿼리, window 함수, 개별 카운트 및 대략적인 백분위수를 포함하여 표준 ANSI SQL 의미 체계를 지원하도록 설계되었습니다.
- 쿼리가 컴파일된 후 Presto는 작업자 노드에서 요청을 여러 단계로 처리합니다.
- 불필요한 I/O 오버헤드를 피하기 위해 모든 처리는 메모리 내에서 이루어지며 단계 간에 네트워크를 통해 파이프라인됩니다.
Presto 쿼리 엔진 사용

- Presto를 사용하여 모든 크기의 데이터에 대해 빠른 분석 쿼리를 실행합니다. 이는 Presto가 대기 시간에 최적화되어 있기 때문에 가능합니다.
Hive와 비교

- hive : 오픈 소스 Hadoop 플랫폼에서 대규모 데이터 시스템을 쿼리하도록 설계되었습니다. Hive 2019.1은 SQL과 유사한 쿼리를 MapReduce 작업으로 변환하여 대량의 데이터를 쉽게 실행하고 처리합니다. Hive는 쿼리 처리량에 최적화되어 있으며 풀 모델로 설명됩니다.
- presto : HDFS 등의 데이터에 대한 빠른 대화형 쿼리를 위해 설계되었습니다. Presto는 대기 시간에 최적화되어 있으며 종종 풀 모델로 설명됩니다.
Reference
'Data Engeneering > presto' 카테고리의 다른 글
| Trino 최적화 (3) | 2023.07.01 |
|---|---|
| Presto Query Processing (0) | 2023.02.04 |
| presto tuning (0) | 2023.02.04 |
| Presto (0) | 2023.01.24 |
