
- Groceries 데이터는 현지 식료품 점에서 1달동안의 실제 판매 시점 거래 데이터를 의미
- 9835 행과 169 열로 이루어져 있다.


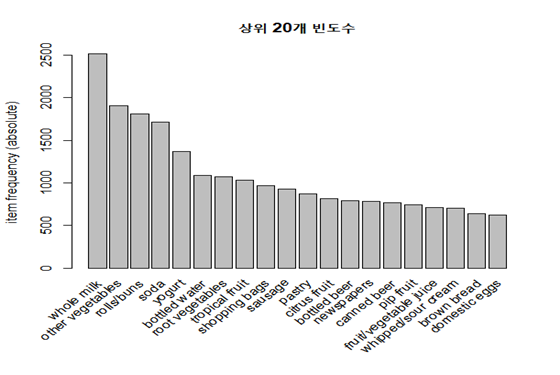
EDA결과 whole milk와 other vegetables가 제일 빈번한 것을 볼 수 있다.

-other vegetables 와 whole milk의 지지도가 0.07이상으로 제일 크다.
-신뢰도를 0.01로 하여 조건을 만족하는 아이탬의 개수가 245개이다.
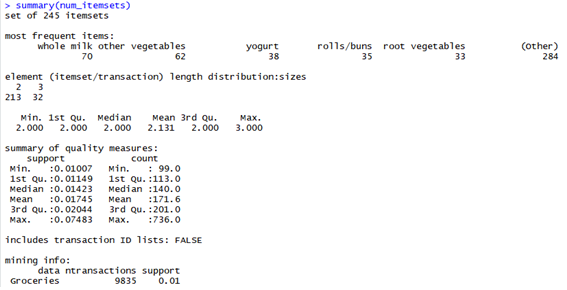
> rule <-apriori(Groceries,parameter=list(support=0.01,confidence= 0.4, minlen=2))
> rule
set of 62 rules
> inspect(rule)
> rule <- sort(rule, by='lift')

lift로 정렬해서 citrus fruit와 root vegetables를 사는 사람은 other vegetables를 산다 는 것을 알 수 있다.
다른 것을 사면 whole milk와 other vegetables를 주로 연관되서 같이 살 확률이 높다
위에 그래프에서 whole milk와 other vegetables를 제외하고 어떤 것을 사면 rolls/buns을 사는지 알아보도록 하자
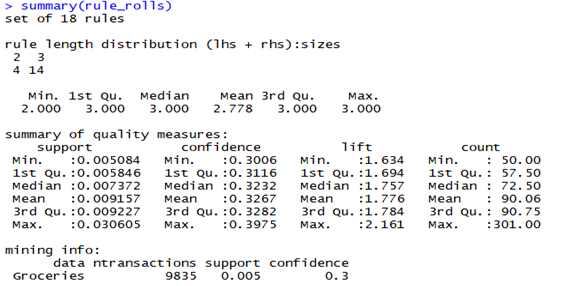
> rule_rolls <- apriori(Groceries, parameter=list(support=0.005,confidence=0.3, minlen=2),appearance=list(rhs="rolls/buns",default='lhs'))
> rule_rolls
set of 18 rules
> inspect(rule_rolls)
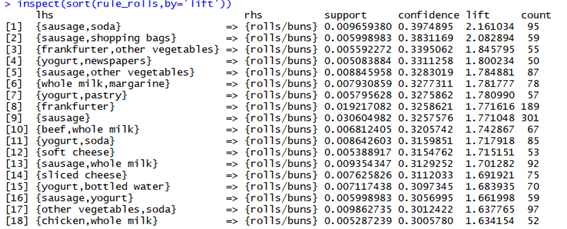
-18개의 아이탬 개수가 나왔으며 lift를 기준으로 정렬하였을 때 sausage와 soda를 살 때 rolls/buns 도 같이 사는 것을 볼 수 있다.
> plot(rule_rolls, method = "graph", control = list(type="items"))

> plot(rule_rolls, method="paracoord", control=list(reorder=TRUE))
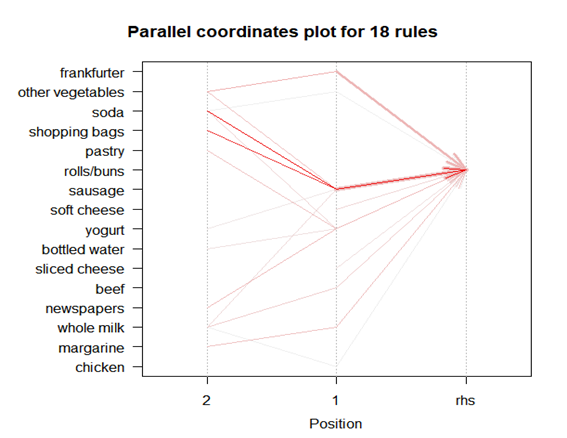
이상으로 Groceries 데이터에 대해서 R을 이용해서 연관성 분석을 해보았다.
'Data Analysis' 카테고리의 다른 글
| [R][시계열] sunspot.year 데이터 분석 (0) | 2019.12.01 |
|---|---|
| [R][시계열] 시계열 데이터 분석 (0) | 2019.12.01 |
| [경마 데이터 분석] 경마 데이터 모델링 및 분석 (0) | 2019.11.27 |
| [경마 데이터 분석] 경마 데이터 EDA 및 전처리 (0) | 2019.11.27 |
| [python][경마 데이터 분석]경마 말혈통정보 크롤링 Xpath (0) | 2019.11.25 |
