실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_base.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
스파크 워크로드

- 스파크는 하둡 맵리듀스보다 최대 100배 더 빠르다고 합니다. 왜냐하면 스파크는 하드 드라이브로 읽고 쓰는 대신에 인 메모리(In-Memory)로 동작하고, 맵리듀스는 클러스터로부터 데이터를 읽고 연산을 수행하며 클러스터에 다시 결과를 작성하여 시간이 소요되는 반면에 스파크는 이 과정을 한 곳에서 수행하기 때문입니다.(2016년 100 테라바이트 정렬에 512개의 노드로 98.8초 만에 완료)
- MapReduce는 데이터의 중간과정을 HDFS에 저장하기 때문에 오버헤드가 발생합니다.Spark은 이러한 문제점을 In-Memory 처리로 해결하는데 메모리 특성상 중간에 오류가 나면 데이터가 모두 사라지게 되는데, 처음부터 다시 연산해야 하는 단점이 생깁니다.
- 대량의 데이터를 고속으로 병렬 분산 처리하는 엔진입니다.
- 스토리지 I/O와 네트워크 I/O를 최소화하며, 연속적인 데이터 변환 처리나 반복 처리에 적합하게 설계되어 있습니다. 또한 스트리밍 처리와 같은 지연 시간이 작은 작업에도 사용할 수 있습니다.
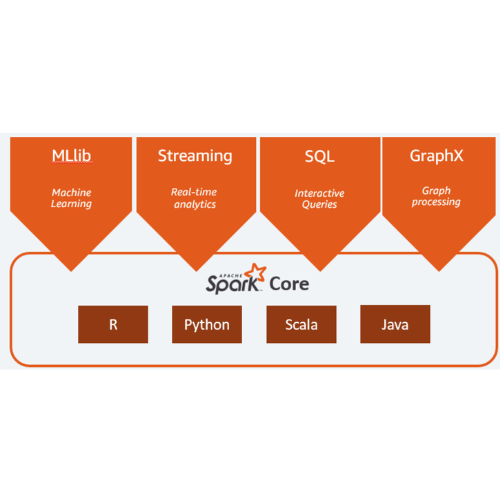
- SQL과 구조화된 데이터를 제공하는 스파크 SQL, 머신러닝을 지원하는 MLlib, 스트림 처리 기능을 제공하는 스파크 스트리밍과 새롭게 선보인 구조적 스트리밍 그리고 그래프 분석 엔진인 GraphX 라이브러리를 제공하고 있습니다.
- 내결함성과 트레이드오프
- Spark는 디스크 I/O를 최소화하므로 처리 속도가 빠르지만, 디스크에 데이터가 저장되지 않기 때문에 장애 발생 시 복구에 특별한 작업이 필요합니다. 이는 내결함성과 처리 속도 사이의 트레이드오프 관계를 나타냅니다.
- 디스크에 데이터를 저장하면 장애 발생 시 복구가 용이하지만, 스파크와 같은 메모리 기반 시스템에서는 복구 작업이 복잡할 수 있습니다. 스파크는 장애 발생 시 이전 작업을 재실행하여 복구를 시도하는데, 이 점은 맵리듀스와 스파크의 성능 차이를 결정짓는 중요한 요소입니다.
- 스파크의 언어 API
- 스칼라 : 스파크는 스칼라로 개발되어 있으므로 스칼라가 스파크의 기본 언어
- 자바 : 스파크가 스칼라로 개발되어 있지만, 스파크 창시자들은 자바를 이용해 스파크 코드를 작성할 수 있도록 심혈을 기울임
- 파이썬 : 스칼라가 지원하는 거의 모든 구조를 지원함
- SQL : ANSI SQL:2003 표준 중 일부를 지원함
- 스파크 코어에 포함된 SparkR, R 커뮤니티 기반 패키지인 sparklyr
스파크 API
RDD - 저수준 API

- RDD(Resilent Distributed Dataset) : 스파크 API의 핵심 요소, RDD는 분산 데이터 컬렉션(즉, 데이터셋)을 추상화한 객체로 데이터셋에 적용할 수 있는 연산 및 변환 메서드를 함께 제공합니다.
- RDD API는 Dataset과 유사하지만 RDD는 구조화된 데이터 엔진을 사용해 데이터를 저장하거나 다루지 않습니다. RDD와 Dataset 사이의 전환은 매우 쉬우므로 두 API를 모두 사용해 각 API의 장점을 동시에 활용합니다.
- Spark의 프로그래밍 모델은 RDD를 가공하여 새로운 RDD를 생성하고 이를 반복하여 원하는 결과를 얻는 형태입니다.
- RDD는 대량의 데이터를 요소로 가지는 분산 컬렉션으로, 파티션 단위로 데이터가 분산되어 처리됩니다.
- RDD 는 메모리 내 컴퓨팅 작업 스토리지를 활용하여 외부 스토리지 시스템의 사용을 줄이는 것을 목표로 합니다. 이 접근 방식은 작업 간의 데이터 교환 속도를 10~100배 향상시킵니다.
- 두 가지 유형의 작업
- 변환 : RDD를 입력으로 사용하고 하나 이상의 RDD를 출력으로 생성합니다.
- filter: 요소를 필터링
- map: 각 요소에 동일한 처리를 적용
- flatmap: 각 요소에 동일한 처리를 적용하고 여러 개의 요소를 생성
- zip: 파티션 수가 같고, 파티션에 있는 요소의 수도 같은 두 개의 RDD를 조합해 key-value pair를 만듬
- 셔플 (Shuffle): 셔플은 특정 변환 처리에서 같은 키를 가지는 요소가 같은 파티션에 위치하도록 하는 과정입니다. 이를 통해 RDD의 요소들이 적절한 파티션으로 분배되며, 이 과정은 파티셔너에 의해 수행됩니다.
- reduceByKey: 같은 키를 가지는 요소를 aggregation
- join: 두 개의 RDD에서 같은 키를 가지는 요소끼리 join
- 액션 : RDD를 입력으로 받아 수행된 작업을 출력으로 생성합니다.
- saveAsTextFile: RDD의 내용을 파일로 출력
- count: RDD의 요소 수를 셈
- 변환 : RDD를 입력으로 사용하고 하나 이상의 RDD를 출력으로 생성합니다.
- 저장
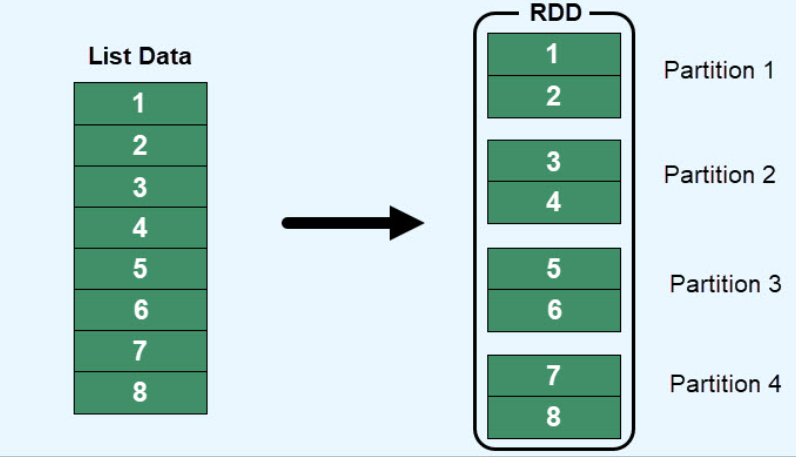
- RDD는 데이터를 읽기 전용 모드로 저장하므로 변경할 수 없습니다. 기존 RDD에서 작업을 수행하면 기존 데이터를 조작하지 않고 새 객체가 생성됩니다.
- RDD는 여러 파티션에 걸쳐 데이터 스토리지를 추가로 분산합니다. 파티셔닝은 노드에 장애가 발생한 경우 데이터 복구를 허용하고 데이터를 항상 사용할 수 있도록 합니다.
- Spark의 RDD는 지속성 최적화 기술(persistence optimization technique)을 사용하여 계산 결과를 저장합니다
- cache()
- persist()
- 스파크의 RDD는 기본적으로 매번 새로운 연산을 실행합니다. 그러나 특정 RDD를 여러 액션에서 재사용하고자 할 때는 RDD.persist()를 사용하여 계산 결과를 유지하게 할 수 있습니다. 이를 통해 메모리나 디스크 등에 데이터를 보존할 수 있습니다.
- 장점
- 불변성(immutable) : 읽기 전용(read-only)
- 복원성(resilient) : 장애 내성
- 분산(distributed) : 노드 한 개 이상에 저장된 데이터셋
- 사용시기
- 고수준 API에서 제공하지 않는 기능이 필요한 경우(클러스터의 물리적 데이터의 배치를 아주 세말하게 제어해야 하는 상황)
- RDD를 사용해 개발된 기존 코드를 유지해야 하는 경우
- 사용자가 정의한 공유 변수를 다뤄야 하는 경우
DataFrame
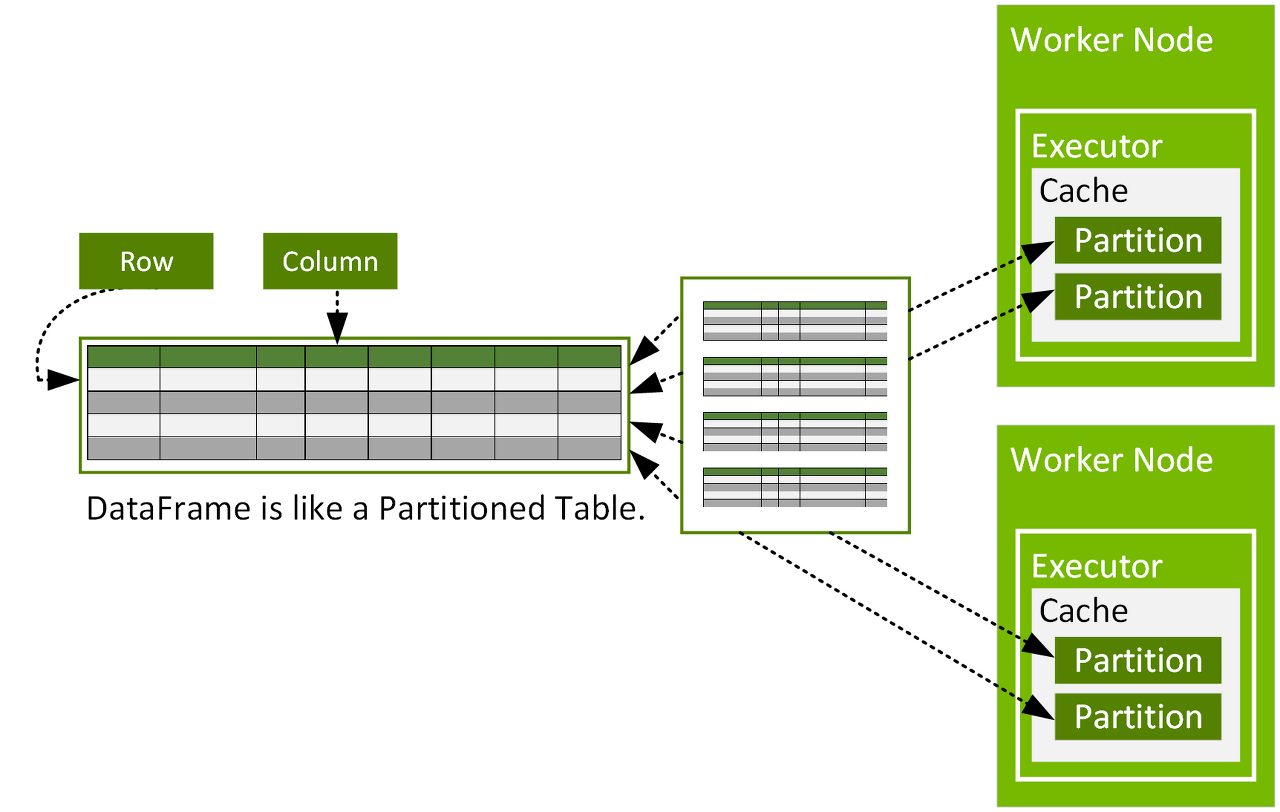
- Row 타입의 레코드(테이블의 로우 같은)와 각 레코드에 수행할 연산 표현식을 나타내는 여러 컬럼(스프레드시트의 컬럼 같은)으로 구성됩니다.
- Row 타입은 스파크가 사용하는 연산에 최적화된 인메모리 포맷의 내부적인 표현 방식으로 가비지 컬렉션(garbage collection)과 객체 초기화 부하가 있는 JVM 데이터 타입을 사용하는 대신 자체 데이터 포맷을 사용하기 때문에 매우 효율적인 연산이 가능합니다.
- RDD와 달리 데이터는 관계형 데이터베이스의 테이블처럼 명명된 열로 구성됩니다 — 데이터 프레임을 구조/배열과 같은 복잡한 데이터 유형을 저장할 수 있는 SQL 테이블 또는 2차원 배열로 생각할 수 있습니다.
- 테이블 형식 데이터를 처리해야 하는 사용 사례에 가장 적합한 선택입니다.
DataSet

- Dataset은 구조적 API의 기본 데이터 타입, 고수준의 구조적 API와 저수준 RDD API가 조합된 형태입니다. — 데이터 세트는 유형이 매우 안전하며 인코더를 직렬화의 일부로 사용합니다. 또한 이진 형식의 직렬 변환기에 텅스텐을 사용합니다.
- 데이터 세트는 형식이 안전하므로 데이터를 사용하기 전에 스키마를 정의해야 합니다. 데이터 세트 사용의 주요 이점은 컴파일 타임 오류 분석 및 데이터 유형 수정이므로 데이터 읽기/변환 시 데이터 유형 문제에 직면하지 않습니다.
- 데이터 프레임에 비해 적은 메모리가 필요합니다. 따라서 스키마를 고수해야 하고 읽을 때 스키마를 생성하지 않으려는 사용 사례에서는 데이터 세트로 이동해야 합니다.
- 사용 시기
- DataFrame 기능만으로는 수행할 연산을 표현할 수 없는 경우
- 성능 저하를 감수하더라도 타입 안정성(type-safe)을 가진 데이터 타입을 사용하고 싶은 경우
- 복잡한 비즈니스 로직을 SQL이나 DataFrame 대신 단일 함수로 인코딩해야 하는 경우
- 타입이 유효하지 않은 작업은 런타임이 아닌 컴파일 타임에 오류가 발생합니다. Dataset API를 사용하면 잘못된 데이터로부터 애플리케이션을 보호할 수는 없지만 보다 우하하게 데이터를 제어하고 구조화합니다.
- 단일 노드의 워크로드와 스파크 워크로드에서 전체 로우에 대한 다양한 트랜스포메이션을 재사용하려면 Dataset을 사용하는 것이 적합합니다.
- Dataset을 사용하는 장점 중 하나는 로컬과 분산 환경의 워크로드에서 재사용, 케이스 클래스로 구현된 데이터 타입을 사용해 모든 데이터와 트랜스포메이션을 정의하면 재사용할 수 있습니다.
- 올바른 클래스와 데이터 타입이 지정된 DataFrame을 로컬 디스크에 저장하면 다음 처리 과정에서 사용할 수 있어 더 쉽게 데이터를 다룰 수 있습니다.
스파크 Lineage
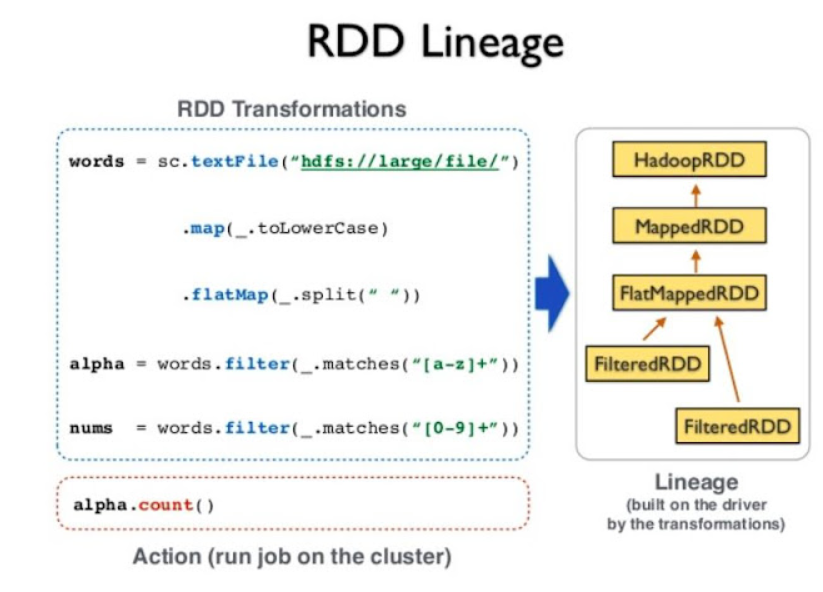
- Lineage는 DAG(Directed Acyclic Graph)의 형태를 가지는데, 이는 순환하지 않는 방향성 그래프입니다. 이곳에는 모든 RDD 생성 과정이 기록되어 있기 때문에 메모리에서 데이터가 유실되면 Lineage 기록에 따라 유실되었던 RDD를 생성할 수 있습니다.
- 출발지에서 목적지까지의 모든 단계를 포함하여 데이터의 여정을 시각적으로 표현하고, 데이터가 이동하는 위치, 데이터 소유자, 각 단계에서 데이터가 처리되고 저장되는 방법에 대한 자세한 정보를 제공합니다.
지연 연산(lazy evaluation)

- Spark의 Lazy Evaluation은 작업이 트리거 될 때까지 실행이 시작되지 않음을 의미합니다. Apache Spark에서 지연 연산은 Spark 변환이 발생할 때 나타납니다.
- 스파크가 연산 그래프를 처리하기 직전까지 기다리는 동작 방식을 의미합니다.
- 스파크는 모든 트랜스포메이션의 연계를 한번에 파악하여 필요한 데이터만 연산하는 지연 연산 방식을 사용합니다. 이 때, 스파크는 실제 데이터 대신 어떻게 데이터를 계산할지에 대한 메타데이터를 기록하고 저장합니다. 이런 접근 방식은 데이터 처리 과정을 이해하기에 더 용이합니다.
- 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고 원시 데이터에 적용할 트랜스포메이션의 실행 계획을 생성합니다.
- RDD 작업 의 실행 시간을 줄임으로써 Apache Spark의 성능을 향상시킵니다.
- 장점
- 관리 용이성 증가 : 작업을 그룹화하여 데이터 전달 횟수를 줄입니다.
- 계산 절약 및 속도 향상 : 필요한 값만 계산되기 때문에 계산 오버헤드를 줄이고 드라이버와 클러스터 간의 이동을 저장하여 프로세스 속도를 높입니다.
- 복잡성 감소 : 모든 작업을 실행하지 않기 때문에 시간이 절약됩니다. 작업은 데이터가 필요할 때만 트리거되므로 오버헤드가 줄어듭니다
- 최적화 : 쿼리 수를 줄여 최적화합니다.
Tungsten Project
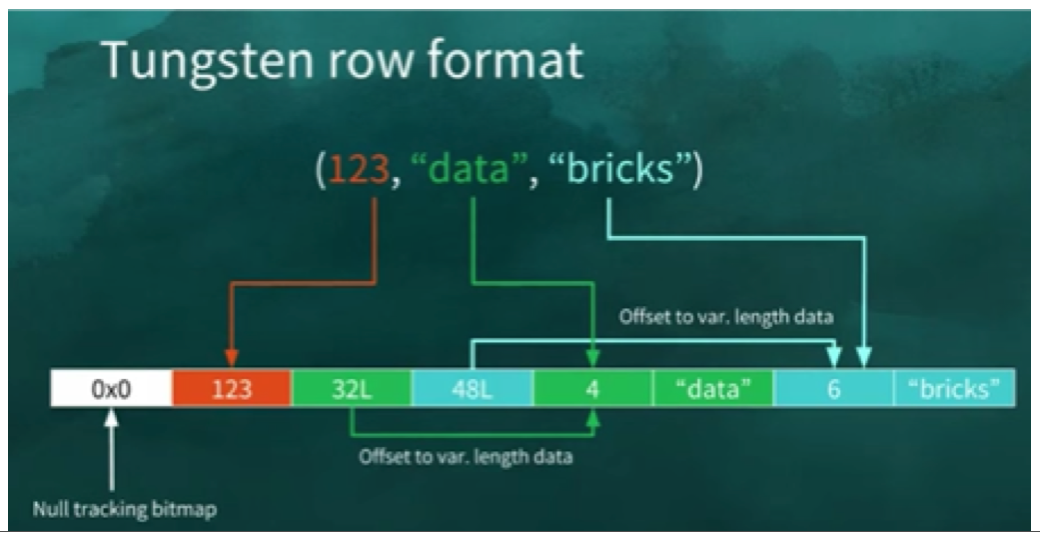
- Tungsten은 Apache Spark의 실행 엔진을 변경하여 Spark 응용 프로그램의 메모리 및 CPU 효율성을 크게 개선하여 성능을 현대 하드웨어의 한계에 더 가깝게 만드는 우산 프로젝트의 코드명입니다.
- 텅스텐은 Apache Spark에 내장된 고급 최적화 엔진으로, 메모리를 보다 효율적으로 활용하여 애플리케이션의 성능을 개선하는 데 도움이 됩니다. 가비지 수집 오버헤드를 줄이기 위해 특별히 설계된 메모리 인식 데이터 구조 및 알고리즘을 사용하여 이를 수행합니다. 메모리 사용을 최적화함으로써 텅스텐은 가비지 수집이 발생하는 동안 대기하는 데 소요되는 시간을 줄이는 데 도움이 될 수 있습니다.
- 메모리 관리 및 이진 처리 : 애플리케이션 시맨틱을 활용하여 명시적으로 메모리를 관리하고 JVM 개체 모델 및 가비지 수집의 오버헤드를 제거합니다.
- 캐시 인식 계산 : 메모리 계층 구조를 활용하는 알고리즘 및 데이터 구조
- 코드 생성 : 코드 생성을 사용하여 최신 컴파일러 및 CPU 활용
- 가상 함수 디스패치 없음 : 이는 수십억 번 디스패치할 때 성능에 큰 영향을 미칠 수 있는 여러 CPU 호출을 줄입니다.
- 메모리 대 CPU 레지스터의 중간 데이터 : Tungsten Phase 2는 중간 데이터를 CPU 레지스터에 배치합니다. 이것은 메모리 대신 CPU 레지스터에서 데이터를 얻기 위한 주기 수의 크기 감소입니다.
- 루프 언롤링 및 SIMD : Apache Spark의 실행 엔진을 최적화하여 최신 컴파일러와 CPU의 기능을 활용하여 간단한 for 루프(복잡한 함수 호출 그래프와 반대)를 효율적으로 컴파일 및 실행합니다.
- 텅스텐 엔진 : 객체(정수형, 문자열, 튜플 등)를 이진수로 인코딩하고 메모리에서 직접 참조하는 방식으로 메모리 관리 성능을 개선합니다.
- 온-힙 할당 모드 : 이진수로 인코딩한 객체를 JVM이 관리한느 대규모 long 배열에 저장
- 오프-힙 할당 모드 : sun.misc.Unsafe 클래스를 사용해 마치 C 언어처럼 메모리를 주소로 직접 할당하고 해제
스파크 리소스 할당 및 동적 할당
리소스 할당

- 코어 수 = 실행자가 실행할 수 있는 동시 작업
- Spark와 YARN이 관리하는 두 가지 주요 리소스는 CPU와 메모리입니다. 디스크 및 네트워크 I/O도 Spark 성능에 영향을 주지만 Spark와 YARN 모두 이를 능동적으로 관리하지 않습니다.
- 각각 16개의 코어와 64GB의 메모리가 장착된 NodeManager를 실행하는 6개의 호스트가 있는 클러스터일 때(각 노드에 15개의 코어, 63GB RAM이 있습니다. --num-executors 6 --executor-cores 15 --executor-memory 63G)
- 호스트는 OS 및 Hadoop 데몬을 실행하기 위해 일부 리소스가 필요하므로 리소스의 100%를 YARN 컨테이너에 할당하지 않고 시스템 프로세스를 위해 1GB와 1 코어를 남겨둡니다.
- 6 * 15 = 90core - 호스트는 OS 및 Hadoop 데몬을 위해 리소스 할당 후 최대 코어입니다.
- 90core / 5core = 18 executors로 각각의 노드는 3 executors입니다. 여기서 1 excutor는 호스트는 OS 및 Hadoop 데몬을 위해 리소스 할당합니다.
- 오버헤드 계산
- 63 GB / 3 = 21 GB
- 21 * (1-0.07) ~ 19 GB
- 오버헤드에 대한 공식은 max(384, 0.07 * spark.executor.memory)로 오버헤드 계산: 0.07 * 21(63/3) = 1.47로 21-1.47 ~ 19GB
- 동시 작업이 5개 이상인 응용 프로그램은 나쁜 결과를 초래할 수 있어 최적의 값은 5입니다.
- --num-executors 17 --executor-cores 5 --executor-memory 19G
동적 할당
- 스파크 워크로드에 따라 애플리케이션이 차지할 자원을 동적으로 조절하는 메커니즘을 제공합니다.
- 동적 할당이 활성화된 경우 실행기 수의 상한은 무한대입니다. 따라서 스파크 애플리케이션은 필요한 경우 모든 리소스를 소모할 수 있습니다.
- 요구 사항(데이터 크기, 필요한 계산량)에 따라 값이 선택되고 사용 후 해제됩니다. 이렇게 하면 리소스를 다른 애플리케이션에 재사용하는 데 도움이 됩니다.
- 사용자 애플리케이션은 더 이상 사용하지 않는 자원을 클러스터에 반환하고 필요할 때 다시 요청할 수 있습니다.
- spark.dynamicAllocation.enabled 속성값을 true로 설정합니다.
직렬화
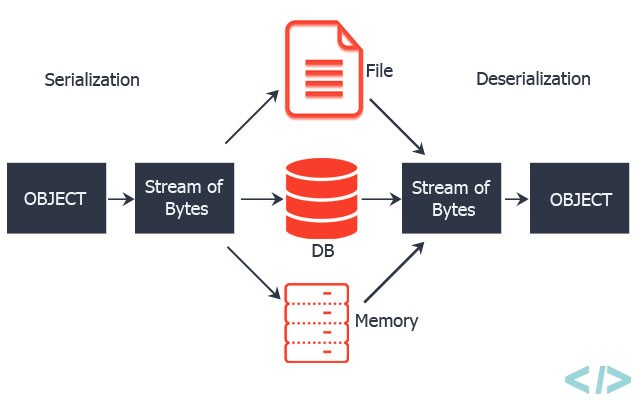
- Spark는 네트워크로 데이터를 전송하거나 디스크에 쓸 때 객체들을 직렬화해 바이너리 포맷으로 변환합니다. 기본적으로 Java에 내장된 직렬화를 이용하지만, Spark는 Java 직렬화보다 훨씬 향상된 서드파티 라이브러리인 Kryo를 쓰는 것도 지원합니다.
- Java 직렬화
- 개체는 ObjectOutputStream 프레임워크를 사용하여 Spark에서 직렬화되며 java.io.Serializable을 구현하는 모든 클래스와 함께 실행할 수 있습니다.
- 직렬화 성능은 java.io.Externalizable을 확장하여 제어할 수 있습니다.
- 유연하지만 느리고 많은 클래스에 대해 큰 직렬화 형식으로 이어집니다.
- Kryo 직렬화
- Spark는 Kryo 라이브러리(버전 4)를 사용하여 개체를 더 빠르게 직렬화할 수도 있습니다.
- Kryo는 Java 직렬화(종종 최대 10배) 보다 훨씬 빠르고 컴팩트하지만 모든 Serializable유형을 지원하지 않으며 최상의 성능을 위해 프로그램에서 사용할 클래스를 미리 등록해야 합니다.
- SparkConf로 작업을 초기화하고 conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")를 호출하여 Karyo로 전환할 수 있습니다.
Reference
- https://www.amazon.com/Spark-Definitive-Guide-Processing-Simple/dp/1491912219
- https://www.databricks.com/glossary/tungsten
- https://itnext.io/apache-spark-internals-tips-and-optimizations-8c3cad527ea2
- https://vasanth370.medium.com/apache-spark-optimization-techniques-and-tuning-e861d94d4209
- https://docs.cloudera.com/cdp-private-cloud-base/7.1.6/tuning-spark/topics/spark-admin-tuning-resource-allocation.html
- https://www.databricks.com/glossary/spark-tuning
- https://spark.apache.org/docs/latest/tuning.html
'Data Engeneering > spark' 카테고리의 다른 글
| spark join and shuffle (0) | 2023.01.26 |
|---|---|
| spark 클러스터 매니저 (0) | 2023.01.25 |
| spark yarn (0) | 2023.01.25 |
| spark 최적화 (2) | 2023.01.18 |
| Spark 튜닝 (0) | 2023.01.16 |
