실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/spark_yarn.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
YARN

- YARN을 사용하면 그래프 처리, 대화형 처리, 스트림 처리, 일괄 처리와 같은 다양한 데이터 처리 방법을 통해 HDFS에 저장된 데이터를 실행하고 처리할 수 있습니다. 따라서 YARN은 Hadoop을 MapReduce 이외의 다른 유형의 분산 애플리케이션에 개방합니다.
- YARN은 리소스를 할당 및 관리하고 작업을 예약하여 모든 처리 활동을 수행합니다.
- 플랫폼 관리
- 하둡 사용자들은 애플리케이션 리소스 관리, 작업 예약에 Apache YARN을 친숙하게 사용합니다. YARN을 사용하면 여러 사용자와 프로세스가 하나의 하둡 클러스터를 공유할 수 있으므로 CPU, RAM과 같은 클러스터 리소스도 공유하게 됩니다.
- 모든 작업에 리소스를 고르게 분배하는 공정한 스케줄링
- 용량 스케줄링으로 가중치가 부여된 비율에 따라 대기열을 정의하고, 사용자와 그룹을 해당 대기열에 할당하여 대기열 내에서 작업을 실행합니다.
- YARN은 작업을 실행한 다음 지속되는 시간 동안 모니터링하므로 혹시 장애가 발생하는 경우, YARN이 그러한 작업을 다시 시작하려 시도하게 됩니다.
- 하둡 사용자들은 애플리케이션 리소스 관리, 작업 예약에 Apache YARN을 친숙하게 사용합니다. YARN을 사용하면 여러 사용자와 프로세스가 하나의 하둡 클러스터를 공유할 수 있으므로 CPU, RAM과 같은 클러스터 리소스도 공유하게 됩니다.
구성요소

- 리소스 관리자 : 마스터 데몬에서 실행되며 클러스터의 리소스 할당을 관리합니다.
- 노드 관리자: 슬레이브 데몬에서 실행되며 모든 단일 데이터 노드에서 작업 실행을 담당합니다.
- 애플리케이션 마스터: 개별 애플리케이션의 사용자 작업 수명 주기 및 리소스 요구 사항을 관리합니다. Node Manager와 함께 작동하며 작업 실행을 모니터링합니다.
- 컨테이너: 단일 노드에 있는 RAM, CPU, 네트워크, HDD 등의 리소스 패키지
Scheduler Options

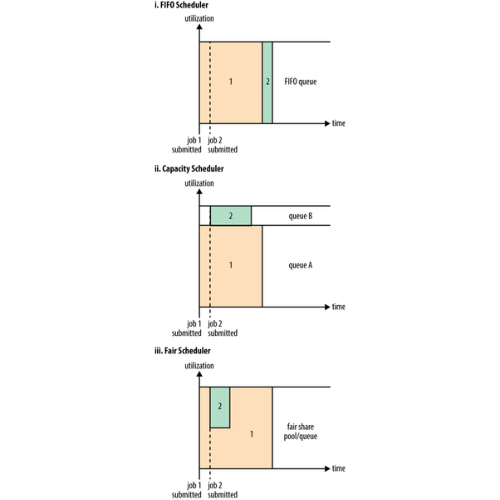
FIFO Scheduler
- 응용 프로그램을 대기열에 배치하여 제출 순서대로 응용 프로그램을 실행합니다. 애플리케이션을 먼저 제출하고 리소스를 먼저 가져오고 완료되면 스케줄러가 큐에 있는 다음 애플리케이션을 처리합니다.
- FIFO는 큰 애플리케이션이 모든 리소스를 점유하고 낮은 서비스 속도로 인해 대기열이 길어지기 때문 공유 클러스터에 적합하지 않습니다.
Capacity Scheduler
- 요청이 시작되는 즉시 작업을 시작하기 위해 작은 작업에 대해 별도의 대기열을 유지합니다.
- 클러스터 용량을 분할하므로 비용이 발생하므로 대규모 작업을 완료하는 데 더 많은 시간이 걸립니다.
Fair Scheduler
- 용량을 예약할 필요가 없습니다.
- 리소스를 수락된 모든 작업으로 동적으로 균형 조정합니다. 작업이 시작되면(실행 중인 유일한 작업인 경우) 클러스터의 모든 리소스를 가져옵니다. 두 번째 작업이 시작되면 일부 컨테이너(컨테이너는 고정된 양의 RAM 및 CPU임)가 해제되는 즉시 리소스를 가져옵니다. 작은 작업이 끝나면 스케줄러는 리소스를 큰 작업에 할당합니다.
- FIFO와 Capacity Scheduler에서 볼 수 있는 두 가지 단점이 모두 제거되어 전반적인 효과는 클러스터 활용도가 높은 작은 작업을 적시에 완료하는 것입니다.
공유 클러스터에서는 Capacity Scheduler 또는 Fair Scheduler를 사용하는 것이 좋습니다. 이 두 가지 모두 장기 실행 작업을 적시에 완료할 수 있도록 하는 동시에 더 작은 임시 쿼리를 동시에 실행하는 사용자가 합리적인 시간 내에 결과를 얻을 수 있도록 합니다.
Reference
'Data Engeneering > spark' 카테고리의 다른 글
| spark 개요 (0) | 2023.02.01 |
|---|---|
| spark join and shuffle (0) | 2023.01.26 |
| spark 클러스터 매니저 (0) | 2023.01.25 |
| spark 최적화 (2) | 2023.01.18 |
| Spark 튜닝 (0) | 2023.01.16 |
