실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
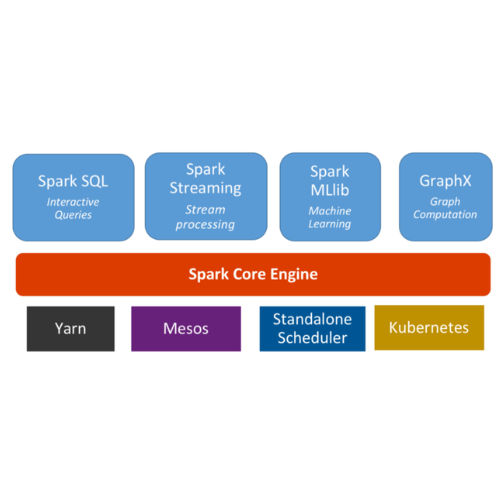
Spark 클러스터

- 스파크는 마스터/슬레이브 구조를 사용하며, 중앙 조정자인 드라이버와 여러 분산 작업 노드인 익스큐터로 구성됩니다. 드라이버는 자바 프로세스에서 동작하며, SparkContext를 생성하고, RDD를 만들며, 사용자 코드의 트랜스포메이션과 액션을 실행합니다.
- 익스큐터는 스파크 작업의 개별 태스크를 실행합니다. 익스큐터는 스파크 애플리케이션이 실행될 때 한번 생성되고, 애플리케이션이 종료될 때까지 계속 동작합니다. 익스큐터는 애플리케이션 작업을 실행하고, 결과를 드라이버에게 반환하는 역할을 하며, 블록 매니저를 통해 사용자 프로그램에서 캐시하는 RDD를 메모리에 저장하는 역할도 합니다. RDD가 익스큐터 내부에 캐시되기 때문에, 작업의 실행이 용이해집니다.
- 스파크에서 분산 처리를 할 때는, RDD 생성 및 변환으로 구성된 스파크 애플리케이션을 클러스터에 배포합니다. 클라이언트는 애플리케이션 배포 시 실행에 필요한 executor의 스펙을 지정합니다. Executor는 워커 노드에서 실행되어 스파크 애플리케이션을 분산 처리하는 프로세스로 이 스펙에는 CPU 코어 수, 메모리 할당량, 그리고 클러스터 내에서 실행될 executor의 수 등이 포함됩니다.
Spark 클러스터 매니저

- 클라우드에서 standalone cluster mode, 하둡에서 YARN, Apache Mesos, Kubernetes에서 스파크를 사용할 수 있습니다.
- 스파크는 클러스터 환경에서 RDD를 처리하는 분산처리 플랫폼입니다. 스파크는 클러스터 리소스 관리를 위해 YARN, Mesos 또는 Spark Standalone 등의 클러스터 관리 시스템을 사용합니다.
- YARN은 하둡의 클러스터 관리 시스템이며, HDFS와 함께 사용될 때 데이터 지역성을 활용해 효율적인 I/O 처리를 가능하게 합니다.
- Mesos는 동적인 CPU 코어 할당 변경 등 세부적인 제어를 허용하는 범용 클러스터 관리 시스템입니다.
- Standalone은 스파크에 포함된 전용 클러스터 관리 시스템으로, 별도의 시스템 없이도 사용이 가능합니다. 클러스터 환경에서 각 머신은 마스터 노드(리소스를 관리) 또는 워커 노드(처리를 실행)로 동작합니다.
Standalone

- 아파치 스파크 워크로드용으로 특별히 제작된 경량화 플랫폼으로 하나의 클러스터에서 다수의 스파크 애플리케이션을 실행할 수 있습니다.
- 실행을 위한 간단한 인터페이스를 제공하며 대형 스파크 워크로드로 확장할 수 있습니다.
- 스파크 애플리케이션만 실행할 수 있다는 큰 단점, 클러스터 환경을 빠르게 구축해 스파크 애플리케이션을 실행해야 하거나 YARN이나 메소스를 사용해 본 경험이 없다면 가장 좋은 선택지입니다.
YARN

- 하둡 YARN은 잡 스케줄링과 클러스터 자원 관리용 프레임워크입니다.
- 스파크는 기본적으로 하둡 YARN 클러스터 매니저를 지원하지만 하둡 자체가 필요한 것은 아닙니다.
- 하둡 YARN은 다양한 실행 프레임워크를 지원하는 통합 스케줄러입니다.
- cluster 모드는 YARN 클러스터에서 스파크 드라이버 프로세스를 관리하며 클라이언트는 애플리케이션을 생성한 다음 즉시 종료됩니다. client 모드는 드라이버가 클라이언트 프로세스에서 실행됩니다.
- 하둡 설정
- 스파크를 이용해 HDFS의 파일을 읽고 쓰려면 스파크 클래스패스에 두 개의 하둡 설정 파일을 포함시켜야합니다.
- HDFS 클라이언트의 동작 방식을 결정하는 hdfs-site.xml 파일, 기본 파일 시스템의 이름을 설정하는 core-site.xml
- /etc/hadoop/conf 하위에 설정 파일이 존재합니다.
Mesos
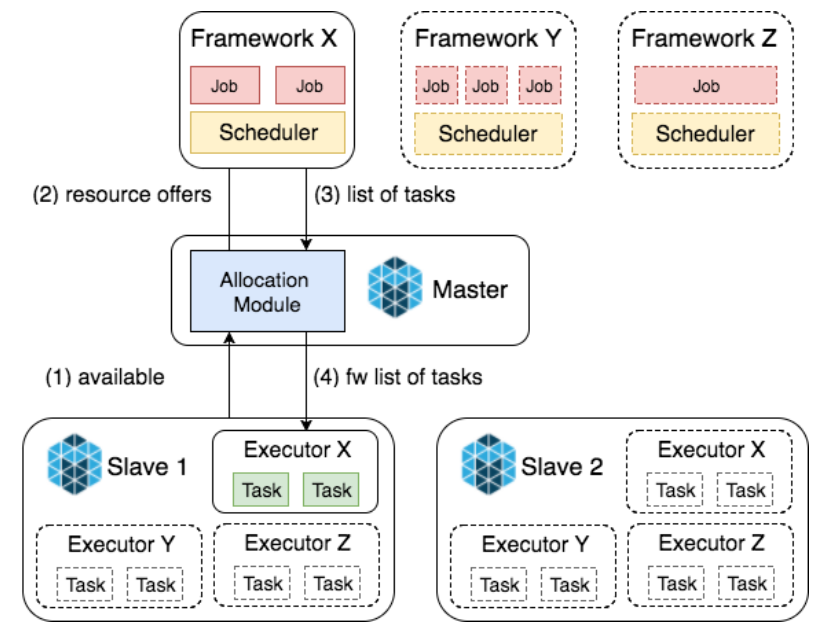
- 아파치 메소스는 CPU, 메모리, 저장소 그리고 다른 연산 자원을 머신에서 추상화합니다.
- 내고장성(fault-tolerant) 및 탄력적 분산 시스템(elastic distributed system)을 쉽게 구성하고 효과적으로 실행합니다.
- 메소스는 스파크처럼 짧게 실행되는 애플리케이션을 관리합니다. 웹 애플리케이션이나 다른 자원 인터페이스 등 오래 실행되는 애플리케이션까지 관리할 수 있는 데이터센터 규모의 클러스터 매니저를 지향합니다.
- 메소스는 스파크에서 지원하는 클러스터 매니저 중 가장 무겁고 대규모의 메소스 배포 환경이 있는 경우에만 사용하는 것이 좋습니다.
Kubernetes
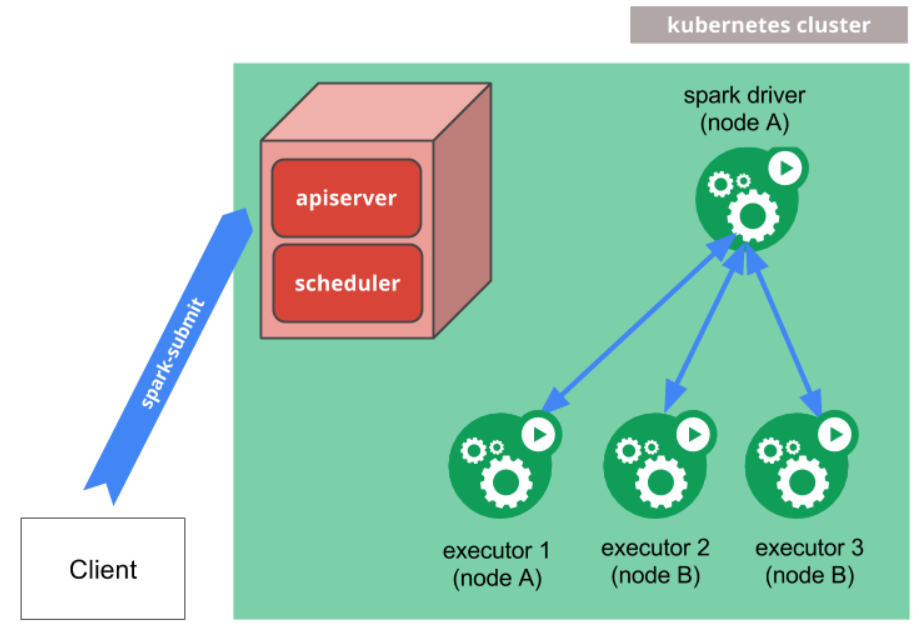
- spark-submitKubernetes 클러스터에 Spark 애플리케이션을 제출하는 데 직접 사용할 수 있습니다.
- 제출 메커니즘 작동
- Spark는 Kubernetes 포드 내에서 실행되는 Spark 드라이버를 생성합니다.
- 드라이버는 Kubernetes 포드 내에서도 실행되는 실행기를 생성하고 연결하여 애플리케이션 코드를 실행합니다.
- 애플리케이션이 완료되면 실행기 포드가 종료되고 정리되지만 드라이버 포드는 로그를 유지하고 결국 가비지 수집되거나 수동으로 정리될 때까지 Kubernetes API에서 "완료" 상태를 유지합니다.
- 완료된 상태에서 드라이버 포드는 계산 또는 메모리 리소스를 사용하지 않습니다.
Reference
'Data Engeneering > spark' 카테고리의 다른 글
| spark 개요 (0) | 2023.02.01 |
|---|---|
| spark join and shuffle (0) | 2023.01.26 |
| spark yarn (0) | 2023.01.25 |
| spark 최적화 (2) | 2023.01.18 |
| Spark 튜닝 (0) | 2023.01.16 |
