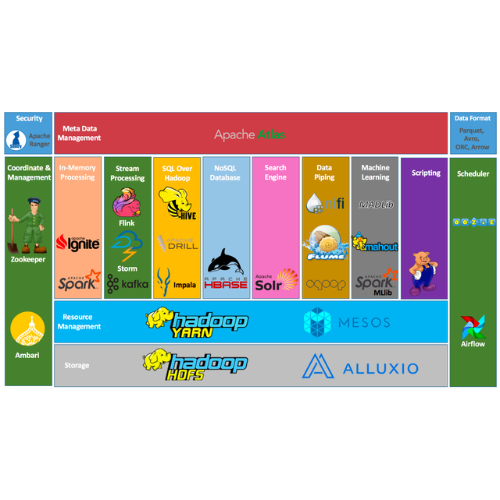
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/hadoop_eco.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어 기술 정리
데이터 엔지니어 기술 정리. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com

Data Ingestion
- 플룸은 많은 양의 로그 데이터를 효율적으로 수집, 취합, 이동하기 위한 분산형 소프트웨어로 클라우데라에서 개발한 서버 로그 수집 도구입니다. 각 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜렉터로 구성됩니다.
- 플룸은 이벤트 기반의 대용량 데이터를 하둡으로 수집하기 위해 개발되었으며 다수의 웹 서버에서 로그파일을 수집하고 해당 파일의 로그 이벤트를 처리하기 위해 HDFS에 위치한 새로운 통합 파일로 옮기는 것은 플룸을 사용하는 전형적인 예입니다.
- Flume은 기본적으로 웹 서버에서 생성된 대량의 로그 파일을 Hadoop으로 빠르고 안정적으로 스트리밍 할 수 있도록 설계됐으며, Kafka 브로커, 페이스북, 트위터와 같은 소스의 데이터를 포함해 이벤트 데이터를 처리하도록 진화했습니다.
Kafka
- 카프카는 링크드인에서 개발한 여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메시징 시스템입니다. 대용량 실시간 로그 처리에 특화되어 있으며 메시지를 받고, 받은 메시지를 다른 시스템이나 장치에 보내기 위해 사용합니다.
- 기본적으로 도착한 메시지를 큐에 저장하고, 순차적으로 메시지를 소비하는 Pub/Sub 패턴을 가지는 메시지 브로커
- 발행(publish) - 구독(subscribe) 모델로 구성되어 메시징, 메트릭 수집, 로그 수집, 스트림 처리 등 다양한 용도로 사용합니다.
Sqoop
- 일반적으로 관계형 데이터베이스와 파일 시스템 간에 HDFS와 아파치 Hive로 대량의 데이터를 이동할 때 사용됩니다. 즉, 구조화된 데이터 저장소(관계형 데이터베이스)와 하둡 간의 효율적인 데이터 전송.
- 관계형 데이터 베이스와 아파치 하둡간의 대용량 데이터들을 효율적으로 변환하여 주는 명령 줄 인터페이스 애플리케이션. 클라이언트-서버모델로 구현됩니다.
- RDBMS와 HDFS 간 대용량 데이터 전송을 위한 솔루션입니다. HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송할 수 있는 방법을 제공합니다. 상용 RDBMS도 지원하고, MySQL, PostgreSQL 오픈소스 RDBMS도 지원합니다.
- 클라이언트는 소스 및 대상 데이터스토어에 설치되고 데이터 이동은 클라이언트와 대응하는 Sqoop 서버에 의해 MapReduce 작업으로 오케스트레이션됩니다.
Nifi
- 소프트웨어 시스템 간 데이터 흐름을 자동화하도록 설계된 소프트웨어 프로젝트로 미국 국가안보국(NSA)에서 개발한 시스템 간 데이터 전달을 효율적으로 처리, 관리, 모니터링하기 위한 최적의 시스템입니다.
- 데이터 변환을 설계, 제어, 모니터링하기 위한 풍부한 웹 기반 GUI를 제공합니다. NiFi는 기본적으로 소스(추출함수), 프로세서(변환 함수), 싱크(로드 함수)라는 세 가지 유형으로 구분된 250개 이상의 표준화된 함수를 제공하며 프로세서 기능의 예로는 데이터 향상, 검증, 필터링, 결합, 분할, 조정이 있습니다.
- 파이썬, 셸, Spark에는 부가적인 프로세서를 추가할 수 있습니다. 프로세서는 데이터 처리에서 매우 동시적으로 구현되며, 병렬 프로그래밍의 고유한 복잡성을 사용자에게 숨깁니다. 프로세서는 동시에 실행되며 로드에 대처하기 위해 여러 스레드에 걸쳐 있습니다.
- 외부 소스에서 데이터를 가져오면 NiFi 데이터 흐름 내부의 FlowFile로 표시됩니다. FlowFile은 기본적으로 관련 메타 정보가 있는 원본 데이터에 대한 포인터
- 프로세서의 세 가지 출력
- 실패 : FlowFIle을 올바르게 처리할 수 없는 경우, 원본 FlowFIle이 출력으로 라우팅 됨
- 원본 : 들어오는 FlowFile이 처리되면 원본 FlowFile이 출력으로 라우팅 됨
- 성공 : 성공적으로 처리된 FlowFile은 이 관계로 라우팅 됨
Fluentd
- 로그 수집 미들웨어로 저장 장소가 분산되어 있는 데이터와 로그의 수집을 간단하고 스마트하게 해결해 줌으로써 데이터로부터 가치를 창출하기 위한 비용을 최소화할 수 있습니다.
- 크로스 플랫폼 오픈 소스 데이터 수집 소프트웨어 프로젝트로 트레저 데이터에서 개발한 로그 수집시스템입니다. 주로 루비와 C로 작성되었습니다. 여러 형태의 로그를 전달받아서 원하는 저장소에 쌓을 수 있습니다. 비정형, 반정형 데이터를 필터링, 버퍼링 하여 사용자가 지정하는 데이터베이스나 클라우드 저장소에 효율적으로 저장할 수 있습니다.
- 기본적인 구조는 Flume NG와 비슷합니다. Flume의 Source, Channel, Sink가 Input, Buffer, Output으로 대체되었습니다. 장점은 각 파트 별로 플러그인을 만들기 쉽습니다.
Stream Processing
Flink
- 스트림 및 일괄 처리 기능을 갖춘 오픈 소스 스트림 처리 프레임워크입니다.
- 특징
- Dataflow 모델을 기반으로 DataStream API에서 이벤트 시간 및 비순차적 처리 지원
- 매우 높은 처리량과 낮은 이벤트 대기 시간을 동시에 지원하는 런타임
- 인 메모리 및 코어 외부 데이터 처리 알고리즘 간의 효율적이고 강력한 전환을 위한 맞춤형 메모리 관리
Beam
- 일괄 처리 및 스트리밍 데이터 병렬 처리 파이프라인을 정의하기 위한 오픈소스 통합 모델
- 데이터 사용자는 오픈소스 Beam SDK 중 하나를 사용해 파이프라인을 정의하는 프로그램을 구축합니다.
- 파이프라인은 Beam이 지원하는 분산 처리 백엔드 중 하나에 의해 실행되며 아파치 Apex, 아파치 Flink, 아파치 Spark, 구글 Cloud Dataflow가 포함됩니다.
Storm
- YARN에서도 Twitter의 스트림 처리를 위한 프레임워크입니다.
- 셀프서비스 스트리밍 데이터 패턴의 예이며, 일괄 처리를 스트림 처리의 하위 집합으로 취급합니다.
- 빠른 처리가 장점입니다.
Samza
- Apache Samza는 LinkedIn에서 만든 오픈 소스 프로젝트로 Kafka 및 YARN을 기반으로 하는 스트림 처리 프레임워크입니다.
- Samza는 여러 Kafka 주제에서 메트릭을 스트리밍 할 수 있으며 Hadoop YARN에 배포할 수 있습니다.
- Disk 활용 대량 처리가 가능합니다.
데이터 처리
MapReduce
- MapReduce는 여러 컴퓨터에 걸쳐 분산된 방식으로 대규모 데이터 세트를 처리하기 위해 맞춤 제작된 프레임워크로 클러스터에서 병렬 분산 알고리즘으로 대규모 데이터 세트를 처리하기 위한 프로그래밍 모델입니다.
- 자세한 내용은 블로그 포스팅을 참고해 주세요.
Spark
- 스파크(Spark)는 인메모리 기반의 범용 데이터 처리 플랫폼입니다. 배치 처리, 머신러닝, SQL 질의 처리, 스트리밍 데이터 처리, 그래프 라이브러리 처리와 같은 다양한 작업을 수용할 수 있도록 설계되어 있습니다.
- 스파크는 클러스터 기반으로 작업을 실행하는 자체 분산 런타임 엔진이 있습니다. 하둡과 밀접하게 통합되어 있어서 YARN 기반으로 실행할 수 있고, 하둡 파일 포맷과 HDFS 같은 기반 저장소를 지원합니다.
- 자세한 내용은 블로그 포스팅을 참고해 주세요.
Impala
- HDFS 또는 HBase 기반의 낮은 지연 시간의 대화형 SQL 질의
- 임팔라(Impala)는 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진입니다. 맵리듀스를 사용하지 않고, C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여줍니다.
- 임팔라는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있습니다.
- 실시간 쿼리, 메모리기반, 칼럼기반
Presto
- 프레스토(Presto)는 페이스북이 개발한 대화형 질의를 처리하기 위한 분산 쿼리 엔진입니다. 빅데이터 애드혹 쿼리를 처리하기 위한 분산형 ANSI SQL 엔진
- 메모리 기반으로 데이터를 처리하며, 다양한 데이터 저장소에 저장된 데이터를 SQL로 처리할 수 있습니다. 특정 질의 경우 하이브 대비 10배 정도 빠른 성능을 보여줍니다.
- 자세한 내용은 블로그 포스팅을 참고해 주세요.
Hive
- 하둡 기반의 데이터 웨어하우징 프레임워크로, 빠른 속도로 성장하는 페이스북의 소셜 네트워크에서 매일같이 생산되는 대량의 데이터를 관리하고 학습하기 위해 개발되었습니다.
- 하이브는 하둡 클러스터에 있는 데이터를 검색하기 위해 하이브 쿼리 언어(HiveQL) 혹은 HQL이라 부르는 SQL 호환 언어를 제공합니다. 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행됩니다.
- 하이브에서 레코드 단위 갱신(record-level update), 삽입, 삭제를 할 수 없긴 하지만 쿼리로 새 테이블을 만들 수 있고 쿼리 결과를 파일로 남길 수도 있습니다.
- 자세한 내용은 블로그 포스팅을 참조해 주세요.
Pig
- 피그(Pig)는 야후에서 개발됐으나 현재는 아파치 프로젝트에 속한 프로젝트로서, 복잡한 맵리듀스 프로그래밍을 대체할 피그 라틴(Pig Latin)이라는 자체 언어를 제공합니다. 피그를 사용하면 다중값이나 중첩된 형태의 데이터 구조를 처리할 수 있고 데이터 변환도 쉽게 할 수 있습니다.
- MapReduce 기반의 단순한 script로 데이터 조회 및 분석이 가능합니다.
- 맵리듀스 API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계됐습니다. SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하기가 어려운 편입니다.
- 피그는 쿼리 언어가 아닌 데이터 흐름 언어(data flow language)로 피그에서는 다른 관계로부터 관계를 정의하기 위해 일련의 선언문을 작성합니다. 각각의 새로운 관계별로 새로운 데이터 변환을 실행합니다.
- 피그 라틴 프로그램은 입력 데이터를 처리하여 출력 결과를 생성하는 일련의 연산(operation) 및 변환(transformation)으로 구성되어 있습니다. 전체적으로 보면 각각의 연산은 데이터의 연속적인 흐름을 표현하며, 피그의 실행 환경은 이를 실행 가능한 표현으로 변환한 후 실제 수행합니다. 피그는 내부적으로 이러한 과정을 일련의 맵리듀스 잡으로 변환합니다.
Scheduler
AIrflow
- 에어플로우는 에어비앤비에서 개발한 데이터 흐름의 시각화, 스케쥴링, 모니터링이 가능한 워크플로우 플랫폼입니다. 하이브, 프레스토, DBMS 엔진과 결합하여 사용할 수 있습니다.
- Airflow 스케줄러는 모든 작업과 모든 DAG를 모니터링하고 종속성이 충족된 작업 인스턴스를 트리거합니다.
- Airflow를 사용함으로써 전체 등록된 배치 프로그램들을 한눈에 살펴보는 것뿐만 아니라 각각의 프로그램의 단계별 현황까지 확인 후 쉽게 데이터 재생성과 같은 조치를 취할 수 있습니다. Slack과의 연동을 통해 실패할 경우 바로 파악해 볼 수도 있습니다.
Azkaban
- 아즈카반은 오프라인 필터 단계와 온라인 매퍼 단계로 구성된 재사용 가능한 일반 작업 워크플로입니다.
- Azkaban은 LinkedIn에서 Hadoop 작업을 실행하기 위해 만든 배치 워크플로 작업 스케줄러입니다.
- 시각화된 절차, 인증 및 권한 관리, 작업 모니터링 및 알람 등 다양한 기능을 가지는 워크플로우 관리 도구입니다.
Oozie
- 종속관계가 있는 여러 잡을 흐름에 따라 실행해 주는 시스템
- 우지는 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템입니다. 자바 웹 애플리케이션 서버로 UI 제공하고, 맵리듀스, hive, pig 작업 같은 특화된 액션으로 구성된 XML 포맷의 워크플로우로 작업을 제어합니다.
- 워크플로 엔진은 다른 형태의 하둡잡(맵리듀스, 피그, 하이브 등)을 구성하는 작업 흐름을 저장하고 실행하며, 코디네이터 엔진(coordinator engine)은 미리 정의된 일정과 데이터 가용성을 기반으로 워크플로 잡을 실행 합니다.
- 우지는 확장 가능하도록 설계되었고 하둡 클러스터 내에 수천 개의 워크플로(수십 개의 연속적인 잡으로 구성된)를 시의 적절하게 실행하도록 관리합니다.
- 우지는 실패한워크플로를 다시 실행할 때 성공한 부분에 대해서는 다시 실행하지 않기 때문에 효율적이며 따라서 시간 낭비도 없습니다.
- 우지의 워크플로는 액션 노드(action node)와 제어흐름노드(control-flow node)로 이루어진 DAG
- 액션 노드는 HDFS에 저장된 파일을 옮기거나 맵리듀스, 스트리밍, 피그, 하이브 잡을 실행 하거나 스쿱 임포트를 수행하거나 쉘 스크립트나 자바 프로그램을 실행하는 등 워크플로의 태스크를 수행합니다.
- 제어흐름 노드는 조건부 로직(분기문)과 같은 구문을 통해 액션 사이의 워크플로 실행을 관장합니다.
클러스터 관리
- YARN
- 얀(YARN)은 데이터 처리 작업을 실행하기 위한 클러스터 자원(CPU, 메모리, 디스크등)과 스케쥴링을 위한 프레임워크입니다. 클러스터의 자원을 요청하고 사용하기 위해 API를 제공합니다.
- 기존 하둡의 데이터 처리 프레임워크인 맵리듀스의 단점을 극복하기 위해서 시작된 프로젝트이며, 하둡 2.0부터 이용이 가능합니다. 맵리듀스, 하이브, 임팔라, 타조, 스파크 등 다양한 애플리케이션들은 얀에서 리소스를 할당받아서, 작업을 실행하게 됩니다.
- 맵리듀스, 스파크 등과 같은 분산 컴퓨팅 프레임워크는 클러스터 계산 계층(YARN)과 클러스터 저장 계층(HDFS와 HBase) 위에서 YARN 애플리케이션을 실행합니다.
- Mesos
- 메소스(Mesos)는 클라우드 인프라스트럭처 및 컴퓨팅 엔진의 다양한 자원(CPU, 메모리, 디스크)을 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트입니다.
- 메소스는 범용 클러스터 자원 관리자로 조직의 정책에 따라 다수의 애플리케이션이 세밀하게 자원을 공유할 수 있습니다.
- 메소스는 클러스터링 환경에서 동적으로 자원을 할당하고 격리해 주는 메커니즘을 제공하며, 이를 통해 분산 환경에서 작업 실행을 최적화시킬 수 있습니다. 1만 대 이상의 노드에도 대응이 가능하며, 웹 기반의 UI, 자바, C++, 파이썬 API를 제공합니다. 하둡, 스파크(Spark), 스톰(Storm), 엘라스틱 서치(Elastic Search), 카산드라(Cassandra), 젠킨스(Jenkins) 등 다양한 애플리케이션을 메소스에서 실행할 수 있습니다.
- 기본 정책인 미세 단위(fine-grained) 모드에서 각 스파크 태스크는 메소스 태스크로 실행되며, 미세 단위 모드는 클러스터의 자원을 매우 효율적으로 관리하지만 프로세스 구동 시 오버헤드가 있습니다.
- 큰 단위(coarse-grained) 모드에서 익스큐터는 프로세스의 내부에서 해당 태스크를 실행합니다. 스파크 애플리케이션이 실행되는 동안 익스큐터 프로세스가 클러스터의 자원을 계속 유지하고 있습니다.
저장
HDFS
- 하둡 분산 파일 시스템(HDFS, Hadoop distributed file system)은 하둡 프레임워크를 위해 자바 언어로 작성된 분산 확장 파일 시스템입니다.
- HDFS는 범용 컴퓨터를 클러스터로 구성하여 대용량의 파일을 블록단위로 분할하여 여러 서버에 복제하여 저장합니다.
- 하둡 디스크 상의 거대한 연속 데이터 블록을 스캔하는 데 최적화된 분산, 무 정지 파일시스템으로 HDFS는 클러스터에 분산되어 데이터 저장소의 수평확장성을 제공합니다.
S3
- S3는 아마존에서 제공하는 인터넷용 저장소입니다.
- 어느 곳에서든지 용량에 관계없이 데이터를 저장하고 검색할 수 있는 단순한 웹 서비스 인터페이스를 갖춘 객체 스토리지
- 클라우드 기반 애플리케이션용 기본 스토리지, 분석을 위한 벌크 리포지토리 또는 '데이터 레이크', 백업, 복구, 재해 복구의 대상, 서버 없는 컴퓨팅으로 사용됩니다.
HBase
- HBase는 HDFS 기반의 칼럼 기반 NoSQL 데이터베이스로 일관성을 보장하는 분산 데이터베이스(distributed column-oriented database)입니다.
- 대규모 데이터셋에서 실시간으로 읽고 쓰는 랜덤 액세스가 필요할 때 사용할 수 있는 하둡 애플리케이션. 임의의 읽기/쓰기 접근이 가능한 칼럼 기반 실시간 데이터베이스입니다.
- HBase와 RDBMS의 비교
- HBase
- 분산 및 컬럼 기반 데이터 저장 시스템, 하둡이 HDFS의 무작위 읽기와 쓰기를 제공하지 않는다는 점을 발견했으며 모든 방향의 확장성에 중점을 두어 밑바닥부터 설계되었습니다.
- 로우 개수가 길고(수억), 컬럼 개수가 넓으며(수백만), 수평적으로 분할 가능해서 수천 대의 상용 노드에 자동으로 복제할 수 있습니다.
- 테이블 스키마는 물리적 저장소를 반영해서 효율적인 데이터 구조 직렬화, 저장, 검색을 위한 시스템을 생성합니다.
- RDBMS
- 전형적인 RDBMS는 고정된 스키마, ACID 특성의 로우 기반 데이터베이스, 복잡한 SQL 쿼리 엔진, 강한 일관성, 참조 무결성, 물리층의 추상화, SQL 언어로 복잡한 쿼리를 하는 것에 주안점을 두었습니다. 쉽게 2차 인덱스를 생성할 수 있고, 복잡한 내부, 외부 조인을 수행하고, 여러 테이블, 로우 칼럼을 카운트, 합계, 정렬, 그룹, 페이징 할 수 있습니다.
- 데이터셋 크기나 읽기/쓰기 병행성을 고려해서 규모를 늘려야 할 때 RDBMS의 편리함은 막대한 성능 저하로 이어지며 태생적으로 분산은 어렵다는 것을 알게 될 것입니다. RDBMS를 확장하면 대개 코드의 규칙을 어기고, ACID 제약을 느슨하게 하고, 전통적인 DBA의 지혜를 무용지물로 만들어 처음에 너무나 편리했던 관계형 데이터베이스의 이상적인 속성 대부분을 잃습니다.
- HBase
데이터 직렬화
Avro
- 아파치 에이브로는 특정 언어에 종속되지 않는 언어 중립적 데이터 직렬화 시스템, 하둡 Writable (직렬화 방식)의 주요 단점인 언어 이식성(language portability)을 해결하기 위해 만든 프로젝트입니다.
- 에이브로(Avro)는 아파치의 하둡 프로젝트에서 개발된 원격 프로시저 호출(RPC) 및 데이터 직렬화 프레임워크입니다. 자료형과 프로토콜 정의를 위해 JSON을 사용하며 콤팩트 바이너리 포맷으로 데이터를 직렬화합니다.
- 스키마가 파일 헤더와 함께 저장된다는 점을 제외하면 SequenceFile과 유사합니다. 형식은 표현성이 있고 상호 운용이 가능합니다.
- 이진 표현에는 오버헤드가 있으며, 최적화가 최고로 잘된 것은 아니며 전반적으로 범용 워크로드에 적합함
Thrift
- 쓰리프트는 페이스북에서 개발한 서로 다른 언어로 개발된 모듈의 통합을 지원하는 RPC 프레임워크로 하이브와 통합되어 있습니다. 원격 프로세스에서 쓰리프트를 통해 하이브에 명령을 보낼 수 있습니다.
- 데이터 타입과 서비스 인터페이스를 선언하면, RPC 형태의 클라이언트와 서버 코드를 자동으로 생성해 줍니다.
- 자바, C++, C#, Perl, PHP, 파이썬, 델파이, Erlang, Go, Node.js 등과 같이 다양한 언어를 지원합니다
Protocol Buffers
- 프로토콜 버퍼(Protocol Buffers)는 구글에서 개발한 RPC 프레임워크입니다.
- 구조화된 데이터를 직렬화하는 방식을 제공합니다. C++, C#, Go, Java, Python, Object C, Javascript, Ruby 등 다양한 언어를 지원하며 특히 직렬화 속도가 빠르고 직렬화된 파일의 크기도 작아서 Apache Avro 파일 포맷과 함께 많이 사용됩니다.
보안
Apache Ranger
- 레인저는 하둡 클러스터의 각 모듈에 대한 보안 정책을 관리할 수 있습니다. HDFS의 ACL, Hive 데이터베이스의 접근권한 등의 보안 정책과 각 모듈에 대한 접근 기록(Audit)을 보관합니다.
- 세분화된 권한 부여와 접근 제어를 위해 널리 사용되는 오픈소스 솔루션
- Atlas 카탈로그와 모든 Hadoop 에코시스템에 대한 보안 정책 구현을 위한 중앙 집중식 프레임워크를 제공합니다.
- 개별 사용자, 그룹, 접근 유형, 사용자 정의 태그, IP 주소와 같은 동적 태그 등을 기반으로 한 RBAC 및 ABAC 정책을 지원합니다.
- 데이터 엔티티에 대해 정의된 속성에 따라 액세스를 적용하는 중앙 집중식 보안 프레임워크를 제공하며. 데이터 마스크 또는 행 필터링에 대해 열 수준 또는 행 수준의 속성 기반 액세스 제어를 정의할 수 있습니다.
데이터 거버넌스
- 기업의 여기저기 산재한 데이터를 같은 저장소에 관리, 비정형 데이터를 규칙에 맞게 표준화하는 전사 차원의 빅데이터 관리 체계
Atlas
- 아틀라스는 데이터 거버넌스로 조직이 보안/컴플라이언스 요구사항을 준수할 수 있도록 지원합니다. 데이터 자원에 대한 태깅, 다운스트림 데이터셋에 대한 태그 전파, 메타 데이터 접근에 대한 보안등 다양한 기능을 가지고 있습니다. 메타데이터 변경 알림 기능을 제공하고, Hive, HBase, Kafka의 데이터가 변경되는 것을 알리는 기능을 제공합니다.
- 데이터 엔티티에 대해 메타데이터와 태그를 정의할 수 있는 카탈로그
- Atlas는 테이블 수준 계보 외에도 다음과 같은 유형의 종속성을 추적해 열 수준 계보를 지원합니다
- 단일 종속성 : 출력 열의 값이 입력 열과 동일함
- 표현 종속성 : 출력 열은 런타임 시 입력 열의 일부 표현식(Hive SQL 표현식)에 의해 변환됨
- 스크립트 종속성 : 출력 열은 사용자가 제공한 스크립트에 의해 변환됨
Amundsen
- 아문센은 데이터 디스커버리 플랫폼입니다. 기업에 존재하는 데이터를 검색하고, 추천하는 기능을 가지고 있습니다. 검색, 추천, 미리 보기, 칼럼통계, 소유자, 주사용자들이 잘 표현된 테이블 상세 페이지를 지원합니다.
- 다른 데이터에 대한 정보를 설명하고 제공하는 데이터 집합
- 데이터 세트와 아티팩트를 인덱싱하여 입력 구문 분석에서는 정확한 매칭 개선을 위해 자동 완성(type-ahead) 기능을 구현합니다. 입력 문자열은 와일드카드와 키워드, 범주, 비즈니스 어휘 등을 지원합니다.
- 아문센은 얇은 Elasticsearch 프록시 계층을 구현해 카탈로그와 상호 작용함으로써 퍼지 검색을 가능하게 합니다.
- 메타데이터는 Neo4j에서 유지됨. 인덱스 구축을 위해서는 데이터 수집 라이브러리를 사용합니다.
Data Visualization
Zeppelin
- Zeppelin은 한국의 NFLab이라는 회사에서 개발하여 Apache top level 프로젝트로 최근 승인받은 오픈소스 솔루션으로, Notebook이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, Query 등을 실행하고 결과를 웹에 나타내는 솔루션입니다.
- 데이터를 가공하는 작업의 경우 각 단계별 많은 데이터 검증이 필요하고 프로그램을 짜고 디버깅해서 보는 것보다 코드 몇 줄을 짜고 바로 데이터를 확인해 볼 수 있는 인터렉티브 한 방식이 효율적입니다. 제플린은 이를 불편한 커맨드라인이 아닌 웹에서 쉽고 효율적으로 해줄 수 있는 애플리케이션
Hue
- 하둡 휴(Hue, Hadoop User Experience)는 하둡과 하둡 에코시스템의 지원을 위한 웹 인터페이스를 제공하는 오픈 소스입니다. Hive 쿼리를 실행하는 인터페이스를 제공하고, 시각화를 위한 도구를 제공합니다. 잡의 스케줄링을 위한 인터페이스와 잡, HDFS, 등 하둡을 모니터링하기 위한 인터페이스도 제공합니다.
- 카디널리티 통계와 함께 테이블과 열을 자동으로 나열하고 필터링하는 메타데이터 검색을 제공합니다. 모든 SQL 언어에 대한 쿼리 편집 자동 완성 기능을 제공하고, 유효한 구문만 표시하거나 키워드, 추가 시각화, 쿼리 형식화, 매개변수화에 대한 구문 강조 표시를 제공합니다.
분산 서버 관리
- 클러스터에서 여러가지 기술이 이용될 때 하나의 서버에서 모든 작업이 진행되면 이 서버가 단일실패지점(SPOF)가 됩니다. 이로 인한 리스크를 줄이기 위해 분산 서버 관리 기술을 이용합니다.
Zookeeper
- 분산 애플리케이션을 위한 코디네이션 시스템입니다. 분산된 애플리케이션의 정보를 중앙에 집중하고 구성 관리, 그룹, 네이밍, 동기화 등의 서비스를 수행합니다.
- 분산 시스템에 있어서 부분 실패는 절대 피할 수 없기 때문에 주키퍼를 사용한다고 해도 부분 실패가 완전히 사라지는 것은 아니며 완벽히 감출 수도 없습니다. 주키퍼는 부분 실패를 안전하게 처리할 수 있는 분산 애플리케이션을 구축하기 위한 도구를 제공합니다.
- 특징
- 단순하다 : 주키퍼는 몇 개의 기본 기능을 핵심으로 제공하고 명령 및 통지와 같은 추상화 기능을 추가로 제공하는 간소화된 파일 시스템
- 제공하는 기능이 풍부함 : 주키퍼 프리미티브(primitive)는 대규모 데이터 구조와 프로토콜 코디네이션에 사용되는 풍부한 구성요소를 제공하고 있음
- 고가용성을 제공함 : 주키퍼는 다수의 머신에서 실행되며 고가용성을 보장하도록 설계되었기 때문에 애플리케이션은 주키퍼의 이러한 특성을 전적으로 신뢰하고 사용할 수 있음, 주키퍼는 시스템에서 발생할 수 있는 단일 장애점(single points of failure - SPOF)문제를 해결하는 데 도움을 주므로 신뢰성 높은 애플리케이션을 개발할 수 있음
- 느슨하게 연결된 상호작용에 도움을 줌 : 주키퍼가 동작할 때 참여자들은 서로에 대해 몰라도 상관없음
- 라이브러리다 : 주키퍼는 일반적인 코디네이션 패턴에 대한 구현체와 구현 방법을 공유 저장소에 오픈 소스로 제공함
- 분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템으로, 크게 다음과 같은 네 가지 역할을 수행합니다.
- 첫째, 하나의 서버에만 서비스가 집중되지 않게 서비스를 알맞게 분산해 동시에 처리하게 해줍니다. 둘째, 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해서 데이터의 안정성을 보장합니다. 셋째, 운영(active) 서버에 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영 서버로 바꿔서 서비스가 중지 없이 제공되게 합니다. 넷째, 분산 환경을 구성하는 서버의 환경설정을 통합적으로 관리합니다.
Ambari
- 전체 수명 주기에 걸쳐 하둡 클러스터의 설치 및 관리 기능을 제공하는 전용 도구
- 간단한 웹 사용자 인터페이스를 제공하며, 하둡 클러스터를 구축하려는 사용자와 운영자에게 권장되는 방식
Reference
'Data Engeneering > Hadoop' 카테고리의 다른 글
| Mapreduce & YARN (0) | 2023.04.02 |
|---|---|
| Hadoop & HDFS (0) | 2023.04.01 |
