
데이터 엔지니어링 줌 캠프 PJT를 진행하면서 관련된 내용을 정리하고자 합니다.
프로젝트의 코드는 github에서 확인할 수 있습니다.
https://github.com/mjs1995/data-engineering-zoomcamp/tree/main/04_analytics_engineering
GitHub - mjs1995/data-engineering-zoomcamp: PJT
PJT. Contribute to mjs1995/data-engineering-zoomcamp development by creating an account on GitHub.
github.com
Analytics Engineering이란?
분석 엔지니어의 요구 스택
- 데이터 스토리지 : 데이터 웨어하우징, Azure Blob Storage, Amazon S3 또는 Google Cloud Storage와 같은 클라우드 스토리지 시스템.
- 데이터 처리 : Apache Hadoop, Apache Spark, Apache Flink.
- 프로그래밍 언어 : Python, SQL, Java.
- 데이터 분석 라이브러리 : Pandas, Numpy, Matplotlib 등
- 데이터 시각화 : Tableau, Power BI, QlikView, Looker.
- 협업 및 프로젝트 관리 : Azure DevOps, Github, JIRA, Confluence, Asana.
- 데이터 수집 : Apache NiFi, Apache Airflow, Prefect, Talend.
dbt

- dbt(Data Build Tool)는 개발자가 BigQuery, Snowflake, Redshift 등과 같은 최신 데이터 웨어하우스에서 변환을 정의, 오케스트레이션 및 실행할 수 있도록 하여 데이터 모델 구축을 간소화하는 Python 오픈 소스 라이브러리입니다.
- ETL/ELT 프로세스의 T에 초점을 맞춘 거버넌스 도구라고 말할 수 있습니다. 이를 통해 SQL에서 모든 데이터 변환을 중앙 집중화하고 구축하여 재사용 가능한 모듈(모델)로 구성할 수 있습니다
- 소프트웨어 엔지니어링 관행에서 영감을 받아 검증 테스트를 만들고 데이터 파이프라인에서 전체 CI/CD 주기를 구현할 수 있습니다.
- dbt의 주요 기능
- 코드 재사용 : 데이터 모델의 정의 및 패키지의 변환 구성을 허용합니다.
- 품질 검사에 대한 강조 – 데이터 품질을 보장하고 변환 오류를 방지하기 위해 자동화된 테스트의 사용을 권장합니다.
- 버전 제어 및 협업 – Git, Bitbucket 등과 같은 버전 제어 시스템과 함께 작동하도록 설계되어 변경 사항을 쉽게 추적하고 개발 파이프라인에서 협업할 수 있습니다.
- 확장성 – BigQuery, Snowflake, Redshift 등과 같은 최신 데이터 웨어하우스와 함께 작동하도록 설계되어 대용량 데이터 처리를 쉽게 확장할 수 있습니다.
- dbt 사용
- dbt Core: 로컬 또는 자체 서버에 설치된 오픈 소스 버전입니다. CLI 콘솔을 통해 이루어집니다.
- dbt Cloud: Core 버전에 추가 기능(실행 예약, BI, 모니터링 및 경고)을 제공하는 클라우드(SaaS)에서 호스팅되는 플랫폼입니다. GUI가 있어 사용하기가 더 쉽습니다. 유료 요금제 외에도 개발자를 위한 제한된 무료 버전을 제공합니다.
dbt cloud
dbt에 신규 프로젝트를 만듭니다.

gcp iam의 service account에서 json키를 업로드 해줍니다.


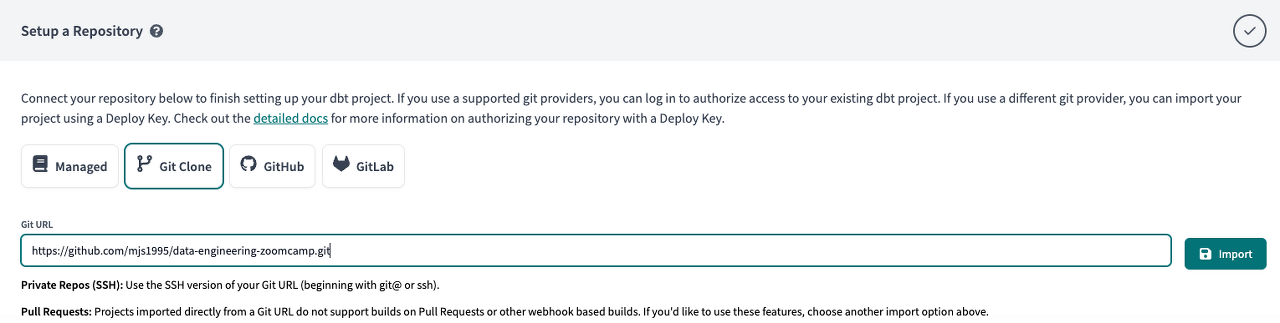
github의 리지스토리를 추가해줍니다.
ssh-keygen -t rsa # 터미널 명령어를 입력해서 키를 생성해줍니다.
cat {키이름}.pub # 위에서 생성된 키 식을 복사합니다.
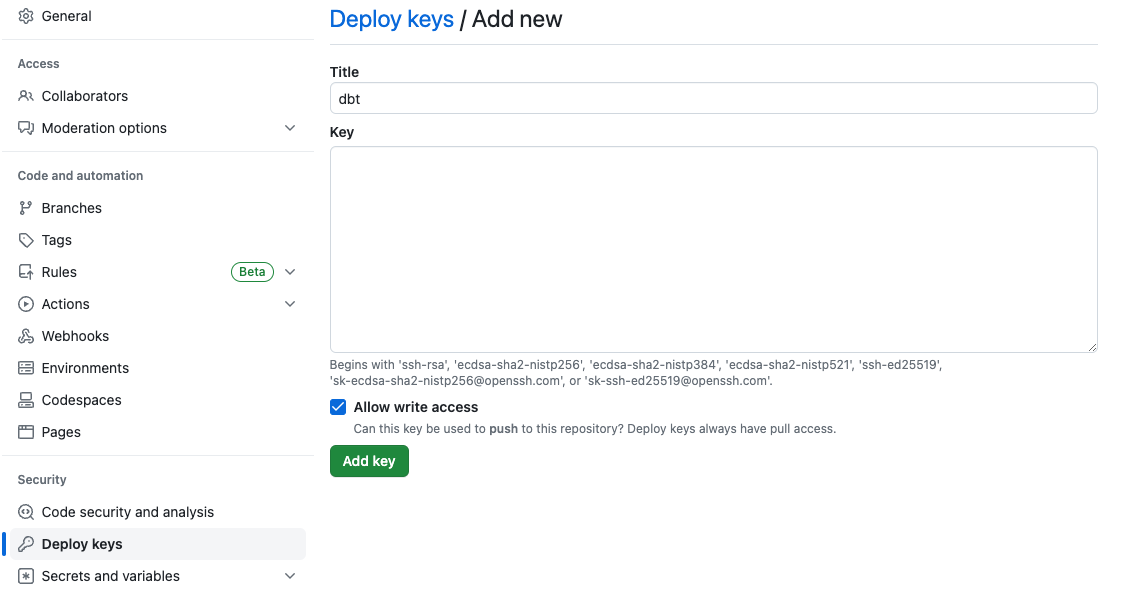
설정에서 Deploy keys를 추가해주고 write access 허용을 해줍니다.

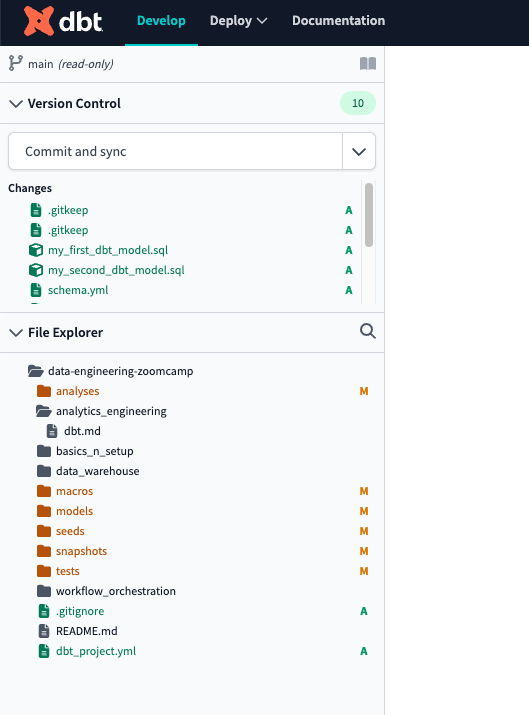
Initialize dbt project 눌러서 프로젝트를 초기화합니다.
schema.yml 파일에는 버전, 소스 이름, 데이터베이스, 스키마 및 테이블이 포함되어 있습니다. yml 파일을 이용해서 단일 위치에서 모든 모델에 대한 연결을 변경할 수 있습니다.

schema.yml 에 소스에 대한 정보를 입력하고 생성해 줍니다.
version: 2
sources:
- name: staging
database: dtc-de-382512
schema: trips_data_all
tables:
- name: green_tripdata
- name: yellow_tripdata생성된 소스가 잘 작동하는지 쿼리문을 확인합니다.
{{ config(materialized='table') }}
SELECT *
FROM {{ source('staging','green_tripdata') }}
Macros
아래와 같은 SQL문을 매크로 함수로 만들어 주려고 합니다.
{{ config(materialized='table') }}
SELECT
case payment_type
when 1 then 'Credit card'
when 2 then 'Cash'
when 3 then 'No charge'
when 4 then 'Dispute'
when 5 then 'Unknown'
when 6 then 'Voided trip'
end as payment_type_description
FROM {{ source('staging','green_tripdata') }}
WHERE vendorid is not null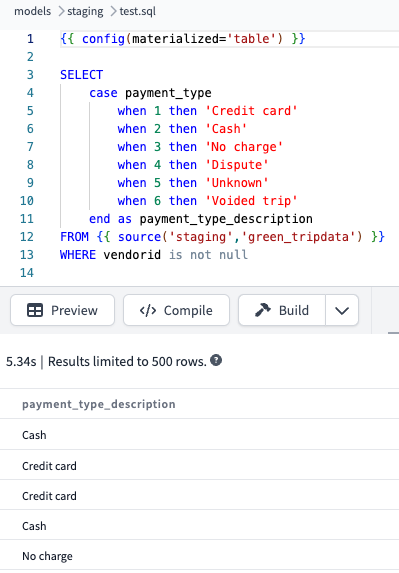
payment_type 의 값을 매개변수로 받고 해당 값을 반환 하는 것을 확인 하는 get_payment_type_description 매크로를 만듭니다.
{#
This macro returns the description of the payment_type
#}
{% macro get_payment_type_description(payment_type) -%}
case {{ payment_type }}
when 1 then 'Credit card'
when 2 then 'Cash'
when 3 then 'No charge'
when 4 then 'Dispute'
when 5 then 'Unknown'
when 6 then 'Voided trip'
end
{%- endmacro %}위에서 생성된 get_payment_type_description 매크로를 실행해 봅니다.
{{ config(materialized='table') }}
SELECT
{{ get_payment_type_description('payment_type') }} as payment_type_description
FROM{{ source('staging','green_tripdata') }}
WHERE vendorid is not null
packages
다른 프로그래밍 언어의 라이브러리나 모듈과 유사하게 서로 다른 프로젝트 간에 매크로를 재사용할 수 있습니다.
프로젝트에서 패키지를 사용하려면 dbt 프로젝트의 root 디렉토리에 packages.yml 구성 파일을 생성해야 합니다.
packages:
- package: dbt-labs/dbt_utils
version: 0.8.0dbt deps 명령어를 실행해서 프로젝트 내 패키지의 모든 종속성 및 파일을 다운로드하는 명령을 실행합니다. 완료되면 프로젝트에 dbt_packages/dbt_utils 디렉토리가 생성됩니다.
dbt deps

Variables
프로젝트 전체에서 사용해야 하는 값을 정의하는 데 유용하며 여러 모델에서 공통으로 사용하는 값을 중앙에서 관리할 수 있습니다.
{{ config(materialized='table') }}
SELECT *
FROM {{ source('staging','green_tripdata') }}
{% if var('is_test_run', default=true) %}
limit 100
{% endif %}
dbt_project.yml 파일이나 command line에서 사용할 수 있습니다.
dbt build --var 'is_test_run: false' # 모델을 빌드할 때 명령줄에서도 사용 가능합니다.
dbt run --var 'is_test_run: false'
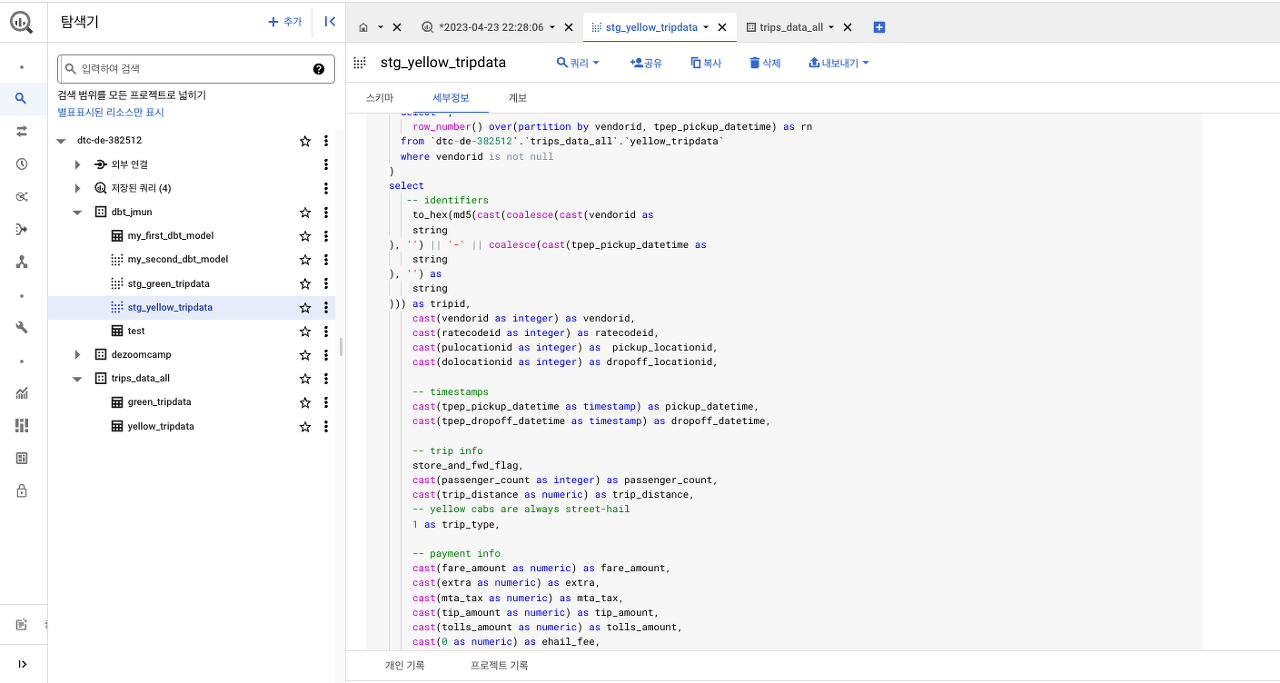
seed
시드를 생성하려면 저장소 의 /seeds 디렉토리에 CSV 파일을 업로드하고 명령을 실행하기만 하면 됩니다.
dbt seed taxi_zone_lookup.csv. 실행하면 dbt seed디렉토리의 모든 CSV가 데이터베이스에 로드됩니다.

dbt_project.yml 파일에 seeds 부분을 추가해 줍니다.
seeds:
taxi_rides_ny:
taxi_zone_lookup:
+column_types:
locationid: numericseeds 안에 있는 csv 데이터를 확인해 봅니다.

dbt seed 명령어를 통해서 dbt 프로젝트의 시드 데이터를 생성합니다.
dbt seed

dbt seed --full-refresh 명령어는 dbt 프로젝트의 시드 데이터를 다시 생성할 때 사용됩니다.
--full-refresh 옵션은 시드 데이터를 완전히 새로 고침하고 기존 데이터를 모두 삭제한 후, 새로운 시드 데이터를 다시 생성합니다.
dbt seed --full-refresh
dbt test
- dbt 모델의 유효성을 검사하는 데 사용됩니다. dbt test는 dbt 모델이 데이터의 정합성과 일관성을 보장하는지 검증하는 데 사용되는 유용한 도구입니다.
- dbt test는 모델을 실행하기 전에 실행됩니다. 모델의 실행 결과가 올바른지 확인하고, 예상한 결과와 실제 결과가 일치하는지 검증합니다. 예를 들어, 모델이 특정 조건에 대해 올바른 값을 반환하는지 확인하거나, 특정 테이블에서 유일한 값을 가져오는지 확인할 수 있습니다.
columns:
- name: tripid
description: Primary key for this table, generated with a concatenation of vendorid+pickup_datetime
tests:
- unique:
severity: warn
- not_null:
severity: warn
- name: Pickup_locationid
description: locationid where the meter was engaged.
tests:
- relationships:
to: ref('taxi_zone_lookup')
field: locationid
severity: warn
- name: Payment_type
description: >
A numeric code signifying how the passenger paid for the trip.
tests:
- accepted_values:
values: "{{ var('payment_type_values') }}"
severity: warn
quote: falsedbt test는 모델을 실행할 때 테스트 쿼리를 실행합니다. 이 쿼리는 모델의 실행 결과를 검증하는 데 사용됩니다. 테스트 쿼리는 SQL 또는 jinja 템플릿으로 작성할 수 있습니다. dbt test는 이러한 테스트 쿼리를 실행하여 검증 결과를 반환합니다.

dbt test --select stg_green_tripdata
Build the First dbt Models
- dbt는 데이터베이스를 위한 오픈 소스 SQL 모델링 도구입니다. 데이터 파이프라인의 구성 요소를 버전 관리하고 테스트하고 문서화하는 데 사용할 수 있습니다.
- dbt run은 모델을 실행하는 것이며, dbt build는 모델을 실행하고 결과를 데이터베이스에 적재하는 것입니다.
- dbt run
- dbt 프로젝트에서 정의한 SQL 모델들을 실행하는 명령어입니다.
- 모델을 실행하면 해당 모델이 참조하는 모든 종속성이 자동으로 실행됩니다.
- 실행 중에 발생하는 오류 및 경고를 표시합니다.
- 명령어를 실행하면 데이터베이스에 정의된 모든 모델이 최신 상태로 업데이트됩니다.
- dbt build
- dbt 프로젝트에서 정의한 SQL 모델들을 실행하고 결과를 데이터베이스에 적재하는 명령어입니다.
- 실행 중에 발생하는 오류 및 경고를 표시합니다.
- 명령어를 실행하면 데이터베이스에 정의된 모든 모델이 최신 상태로 업데이트되며, 이전 결과가 삭제되고 새로운 결과가 적재됩니다.
- dbt 모델의 fact_trips 의 계보를 확인 하고 소스 레이어에서 스테이징 및 마지막으로 최종 테이블까지의 flow를 확인합니다.

dbt run
dbt build
dbt build 이후에 gcp에서도 잘 생성되었는지 확인해 봅니다.

Deployment Using dbt Cloud

- dbt를 사용하면 CI/CD를 구성하여 모델을 프로덕트에 배포 할 수 있습니다.
- 개발 환경과 배포 환경을 분리하면 프로덕트에 영향을 주지 않고 모델을 구축하고 테스트할 수 있습니다.
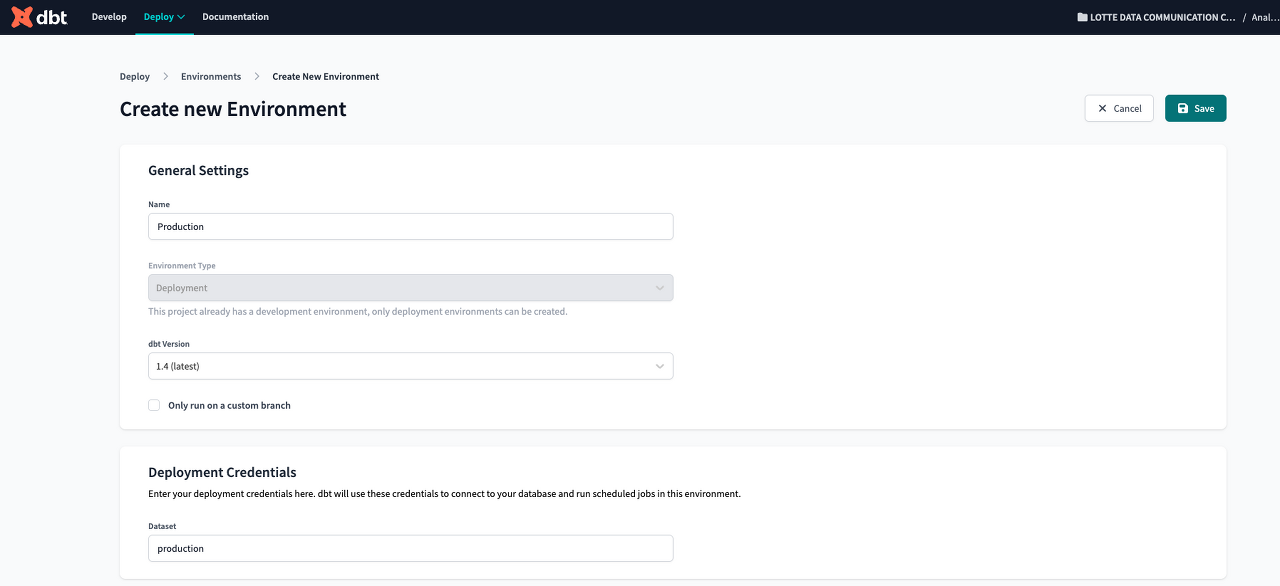
dbt Deploy에서 새로운 환경을 생성해줍니다.
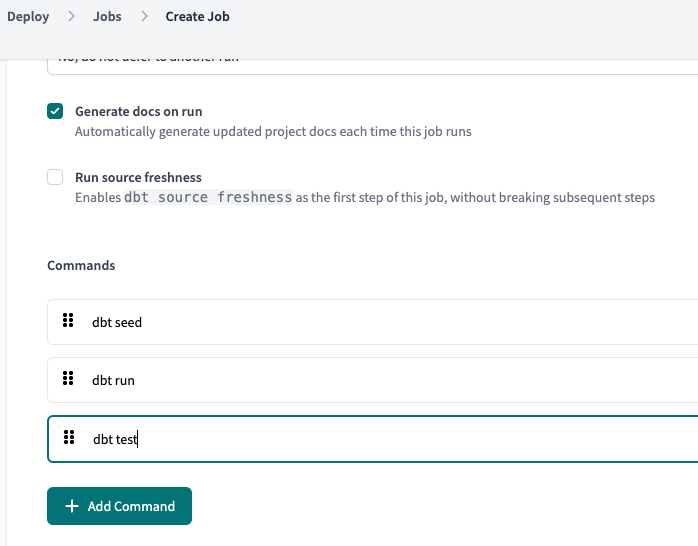
신규 job을 생성해줍니다.

실행할 Commands도 추가해 줍니다.
Triggers 설정에서 스케줄 시간대를 설정해 줍니다.


정해진 시간대에 Job이 도는것을 확인할 수 있습니다.

데이터 리니지에 대한 테이블 관계도 확인할 수 있습니다.

구글 데이터 스튜디오
looker를 이용해서 데이터 시각화를 진행합니다.
구글 데이터 스튜디오는 사용자가 Google Analytics, Google Ads, Google Sheets, 데이터베이스 등과 같은 여러 데이터 소스에 연결하여 보고서를 생성할 수 있는 Looker Studio 기반 데이터 시각화 및 보고 도구입니다
- 데이터 소스 만들기를 선택한 후에 BigQuery를 선택합니다.

데이터 소스로 사용할 테이블을 선택합니다.

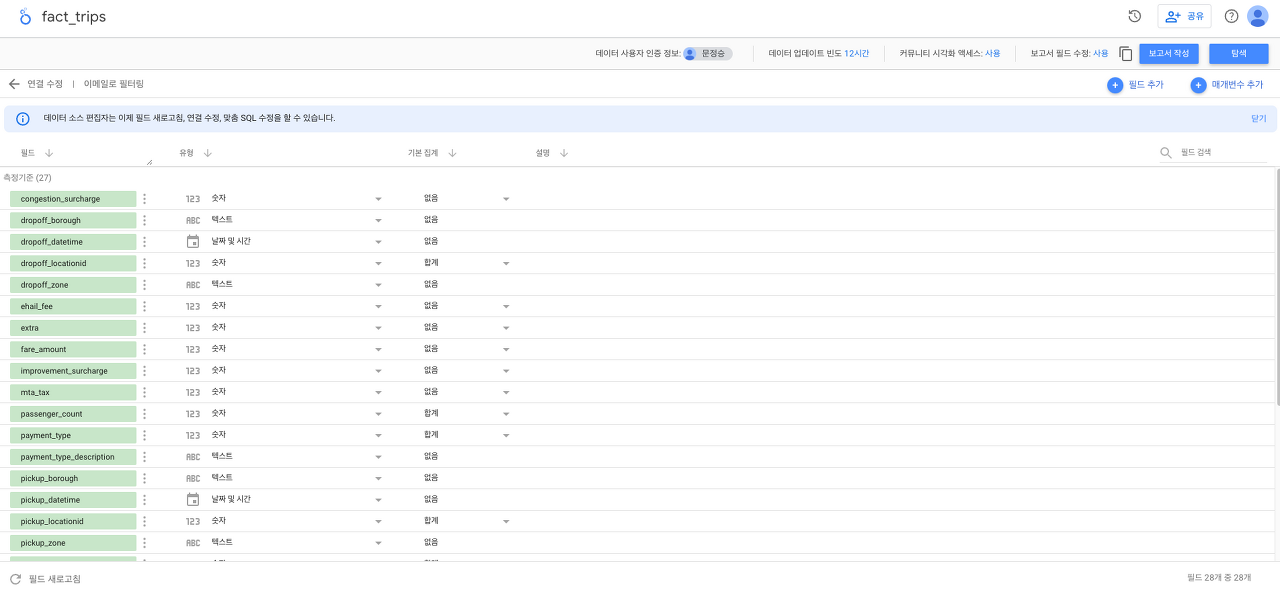
보고서 만들기
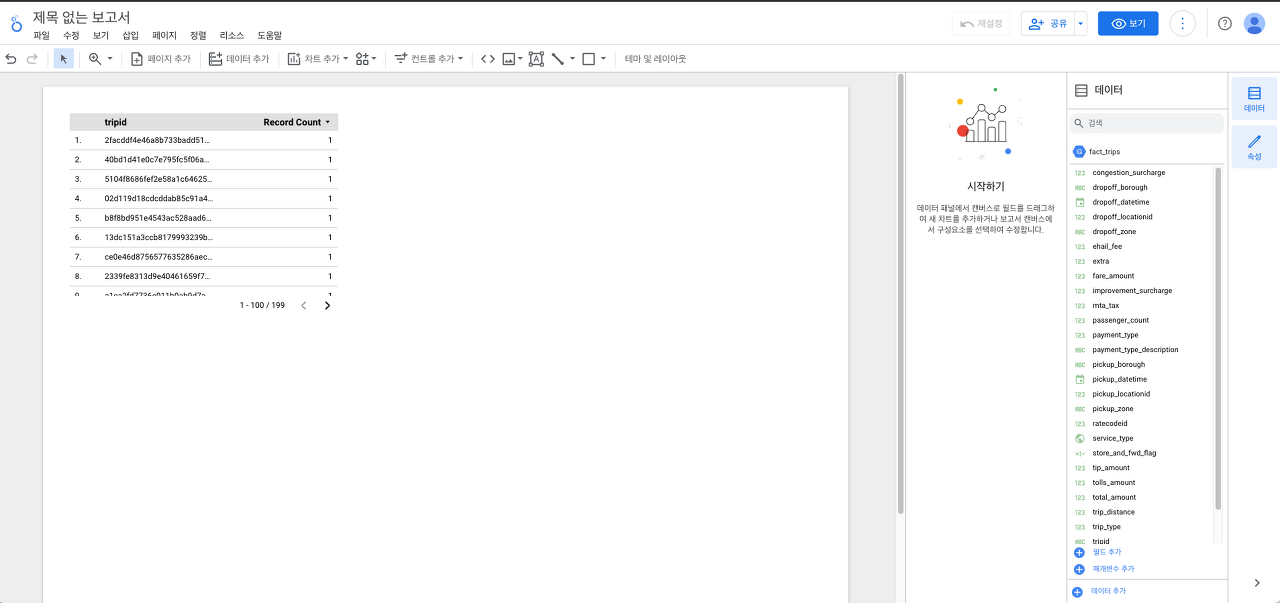
차트를 추가해줍니다.

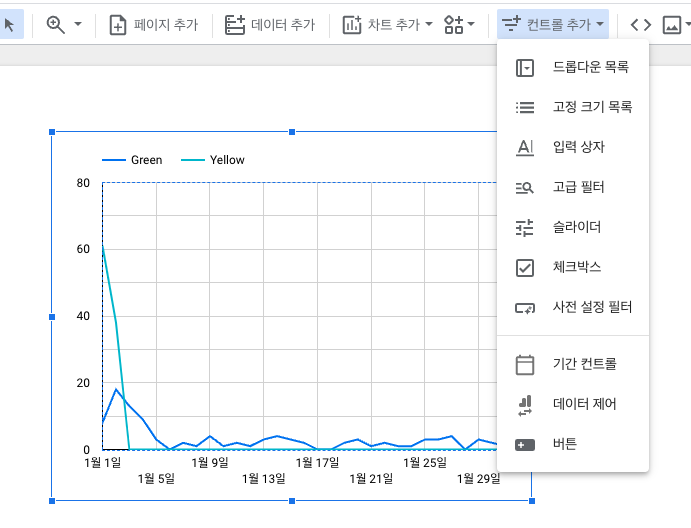
컨트롤 추가에서 기간 컨트롤을 추가해줍니다.
계산된 필드를 만들어줍니다.

최종적으로 만들어진 보고서는 다음과 같습니다.
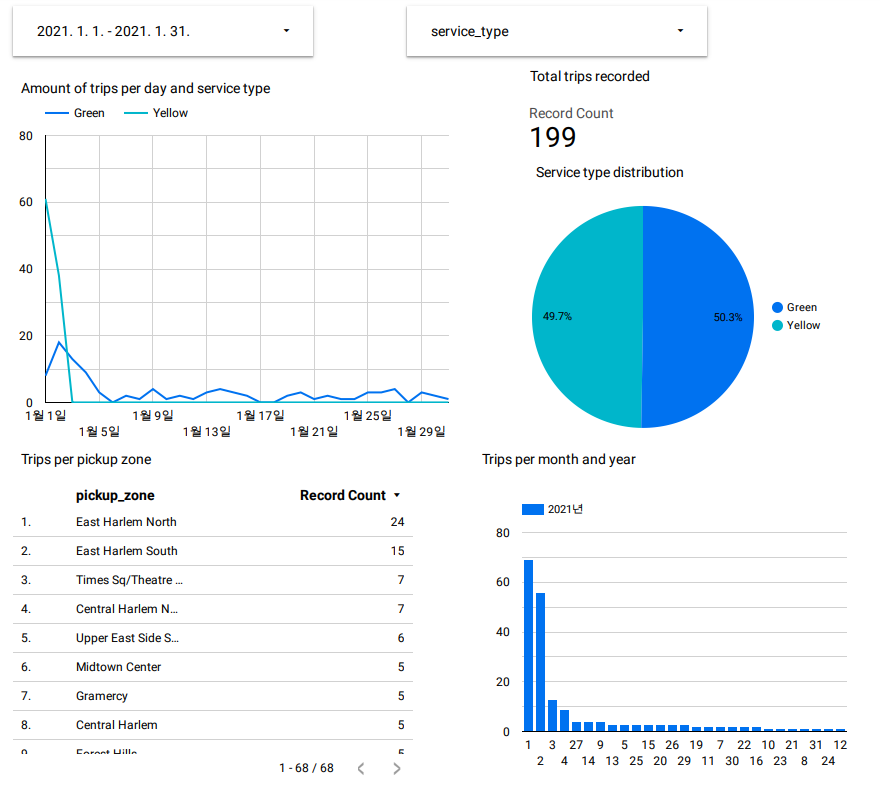
Reference
데이터 엔지니어링 줌 캠프 깃허브 주소
youtube
DataTalks.Club
data engineering zoomcamp slack
'PJT' 카테고리의 다른 글
| [de zoomcamp] 06_스트리밍 (0) | 2023.05.21 |
|---|---|
| [de zoomcamp] 05_배치 처리 (0) | 2023.05.07 |
| [de zoomcamp] 03_데이터 웨어하우스 (0) | 2023.05.07 |
| [de zoomcamp] 02_워크플로 오케스트레이션 (0) | 2023.05.01 |
| [de zoomcamp] 01_소개 및 사전 준비 사항 (0) | 2023.04.30 |
