
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/BI/olap.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
OLTP vs OLAP
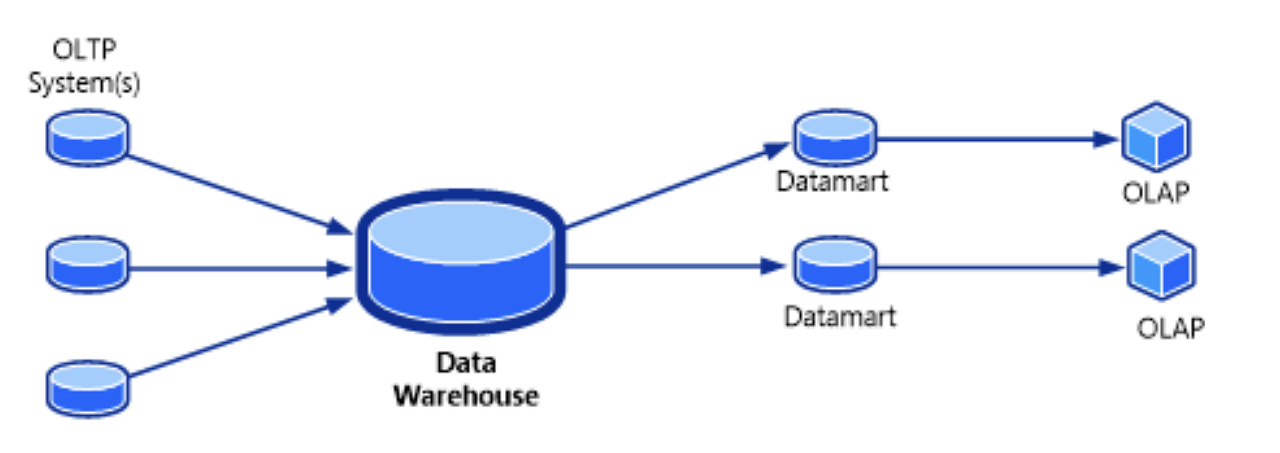
| 특성 | 트랜잭션 처리 시스템(OLTP) | 분석 시스템(OLAP) |
| 주요 읽기 패턴 | 질의당 적은 수의 레코드, 키 기준으로 가져옴 | 많은 레코드에 대한 집계 |
| 주요 쓰기 패턴 | 임의 접근, 사용자 입력을 낮은 지연 시간으로 기록 | 대규모 불러오기(bulk import, ETL) 또는 이벤트 스트림 |
| 주요 사용처 | 웹 애플리케이션을 통한 최종 사용자/소비자 | 의사결정 지원을 위한 내부 분석가 |
| 데이터 표현 | 데이터의 최신 상태(현재 시점) | 시간이 지나며 일어난 이벤트 이력 |
| 데이터셋 크기 | 기가바이트에서 테라바이트 | 테라바이트에서 페타바이트 |
OLTP(Online Transaction Processing)
- 비즈니스가 모든 트랜잭션 및 레코드를 저장하기 위해 사용하는 데이터베이스를 OLTP(온라인 트랜잭션 처리) 데이터베이스라고 합니다
- INSERT, UPDATE 또는 DELETE와 같은 트랜잭션 절차뿐만 아니라 특정 정보를 빠르게 찾는 데 탁월합니다.
- OLTP시스템은 원시 데이터가 실제로 발생하고 기록되는 '무엇(What)'에 초점을 맞추고 있으며, 현재 거래 상태를 정확하게 기록하고 갱신할 수 있도록 하는 것이 목표입니다. 반면 OLAP시스템은 이렇게 수집된 데이터를 의사결정에 활용하는 측면을 담당하여 '왜(Why)'에 초점이 맞추어지며 OLTP시스템이 일상적인 기업의 운영을 지원하는 반면, OLAP시스템은 기업의 방향을 설정하는 역할을 합니다.
- OLTP 시스템
- MySQL
- PostgreSQL
- Amazon Aurora
- Oracle RDBMS
- OLTP 환경
| 데이터 웨어하우스 | OLTP 시스템 | |
| 워크로드 | 임시 쿼리 및 데이터 분석 수용 | 사전 정의된 작업만 지원 |
| 데이터 수정 | 정기적인 자동 업데이트 | 개별 명세서를 발행한 최종 사용자에 의한 업데이트 |
| 스키마 디자인 | 부분적으로 비정규화된 스키마를 사용해 성능 최적화 | 완전히 정규화된 스키마를 사용해 데이터 일관성 보장 |
| 데이터 스캐닝 | 수천에서 수백만 개의 행 포함 | 한 번에 소수의 레코드에만 액세스 |
| 기록 | 데이터 수개월 또는 수년간의 데이터 저장 | 몇 주 또는 몇 달 동안만 데이터 저장 |
OLAP(Online Analytical Processing)
- OLAP(온라인 분석 처리) 시스템은 컴퓨팅에서 다차원 분석 쿼리에 신속하게 응답하는 접근 방식으로 많은 비즈니스 인텔리전스, 분석 및 데이터 과학 응용 프로그램에서 일반적으로 사용합니다.
- OLAP은 최종 사용자가 다차원 정보에 직접 접근하여 대화식으로 정보를 분석하고 의사결정에 활용하는 과정입니다.
- 기존의 관계형 데이터베이스 시스템과 비교할 때 주요 차이점은 OLAP 시스템의 데이터가 미리 집계된 다차원 형식으로 저장된다는 것입니다.
- 특징
- 다차원성 : 사용자들이 실질적인 차원에서 정보를 분석하도록 합니다.
- 직접접근 : 사용자가 전산부서와 같은 정보 매개자를 거치지 않고 자신이 원하는 정보에 직접 접근합니다.
- 대화식 분석 : 사용자는 시스템과의 상호작용을 통해 정보를 분석하며 원하는 결과를 얻을 때까지 계속해서 분석을 수행합니다.
- 의사결정에 활용 : 사용자가 기업의 전반적인 상황을 이해할 수 있게 하고 의사결정을 지원합니다.
- 데이터의 시계열을 유지합니다. 예를 들어 메트릭 값의 변화를 알 수 있습니다.
- 분석가가 일반적으로 수행하는 쿼리는 임시 쿼리이므로 시스템은 스키마 엔지니어링 없이도 모든 비즈니스 질문에 답할 수 있어야 합니다. 모든 차원에 대해 데이터를 신속하게 수집하고 쿼리해야 합니다.
- 관계형 데이터베이스와 달리 데이터는 많은 중복으로 저장될 수 있습니다. 이것은 결과 수집 속도를 향상시키거나(예: 조인 방지) 시계열에서 데이터를 진화시켜야 하는 필요성 때문에 바람직합니다.
- 비즈니스 질문에 답하기 위해 대량의 데이터를 스캔해야 할 수도 있습니다.
- 주요 기능
- Slicing과 Dicing : 다차원 질의의 기본은 사용자가 큐브의 어떤 부분을 볼 것인지 정의하는 것으로 다차원 질의는 마치 사용자가 큐브 일부분을 자신이 원하는 형태로 절단하여 살펴보는 것입니다.
-
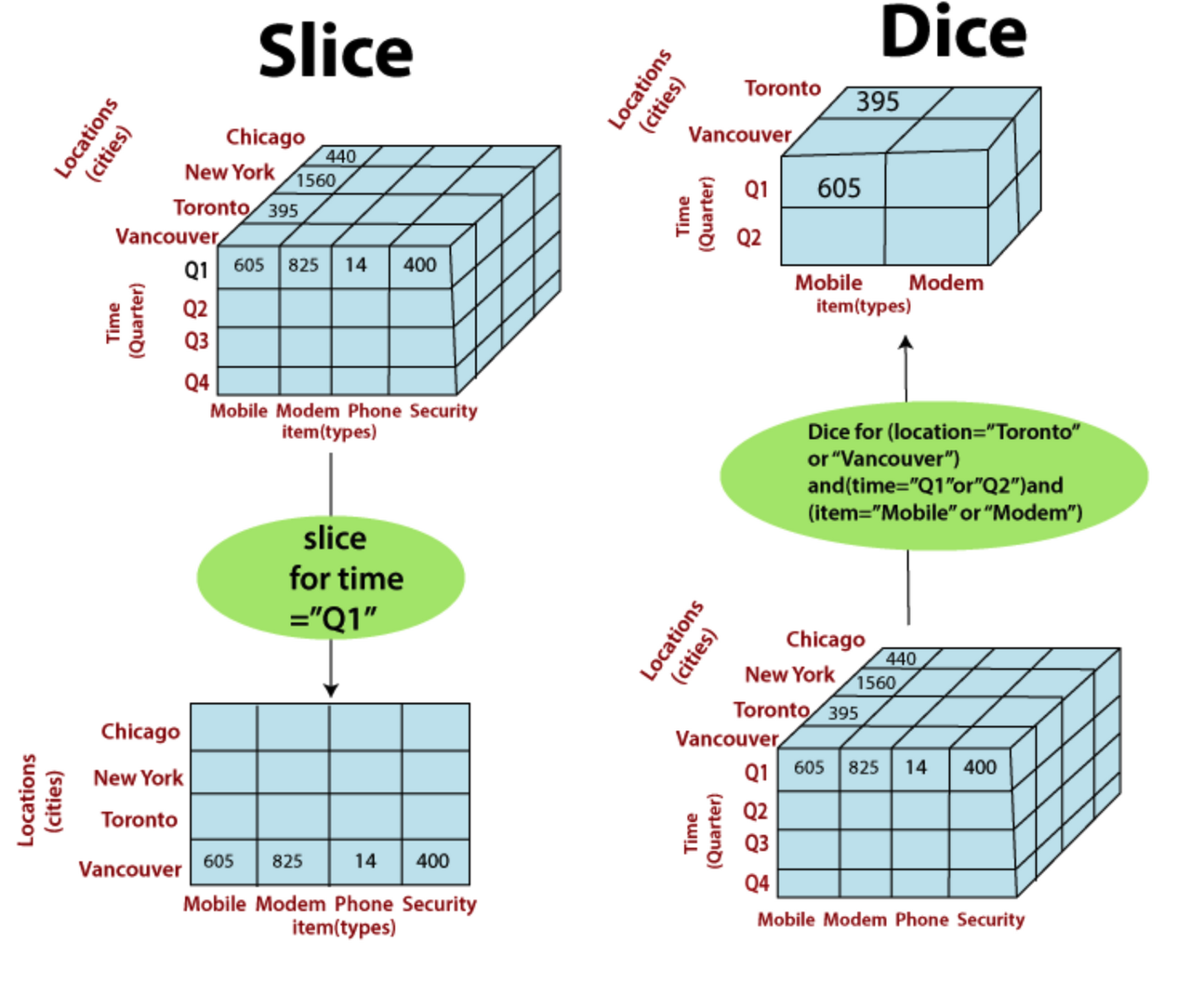
https://www.javatpoint.com/olap-operations
-
- Drill-Down : 드릴다운은 요약된 형태의 데이터 수준에서 보다 구체적인 내용의 상세데이터로 단계적으로 접근하는 분석기법
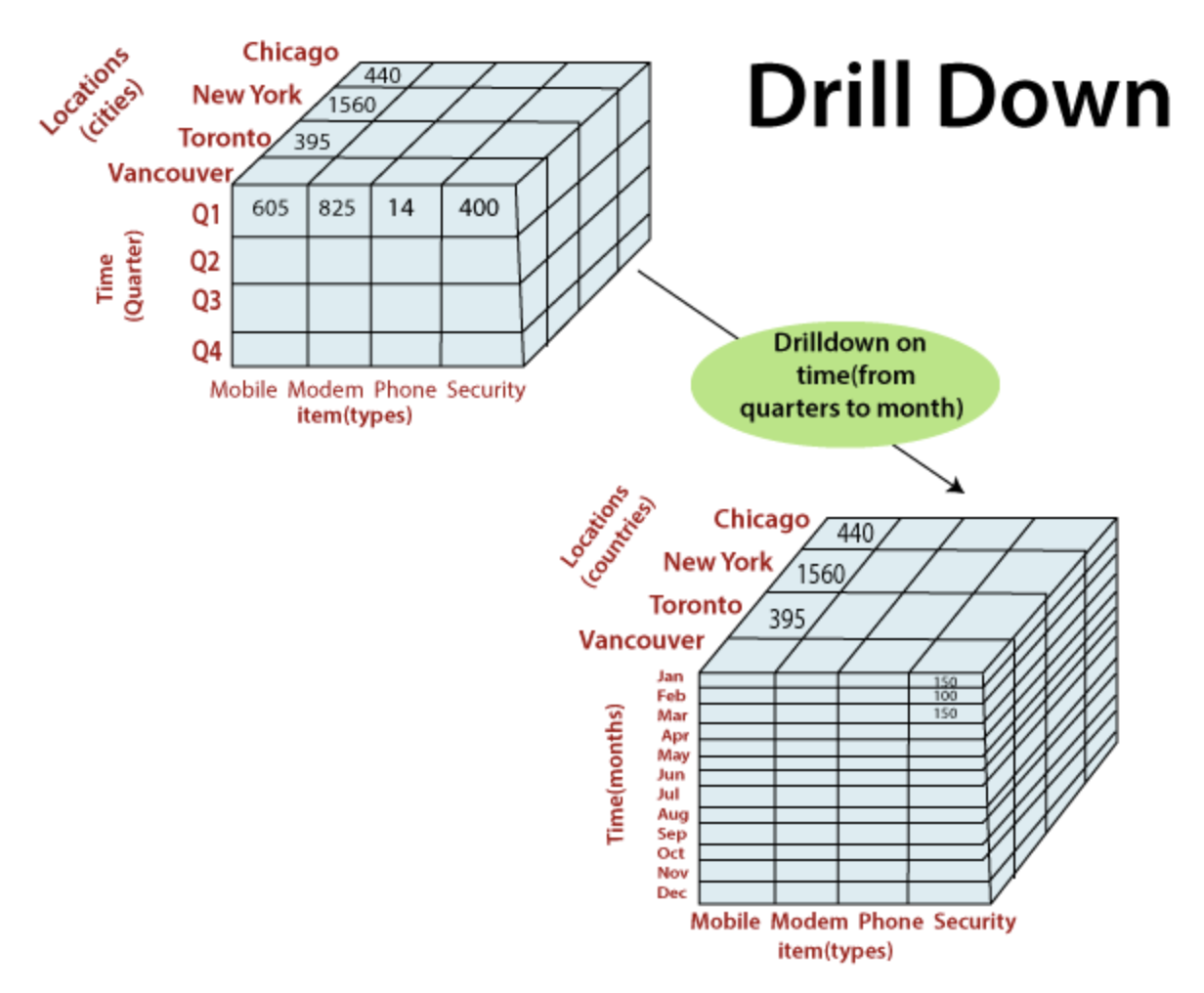
https://www.javatpoint.com/olap-operations
- Drill-up(roll-up) : 드릴다운과 반대 방향으로 사용자가 정보를 분석하는 것으로 작은 단위에서 큰 단위로 집계수행

https://www.javatpoint.com/olap-operations
- Drill-Across : 다른 큐브의 데이터에 접근하는 것
- Drill-Through : OLAP시스템으로부터 데이터 웨어하우스, 혹은 OLAP시스템에 존재하는 상세데이터에 접근하는 것
- 피보팅(Pivoting) : 사용자는 보고서의 행, 열, 페이지 차원을 무작위로 바꾸어 볼 수 있으며 이러한 작업들
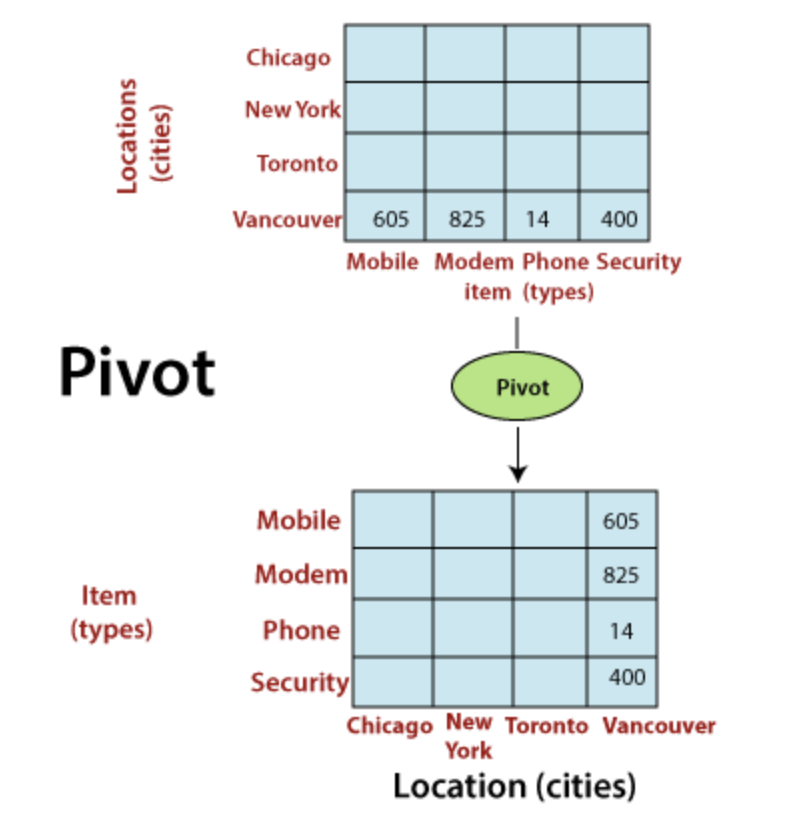
https://www.javatpoint.com/olap-operations
- 필터링 : 보고서 상에 나타나는 데이터를 특정기준(계층구조, 애트리뷰트, 항목이름, 데이터에 기초)에 부합하는 항목으로 한정하는 것
- Slicing과 Dicing : 다차원 질의의 기본은 사용자가 큐브의 어떤 부분을 볼 것인지 정의하는 것으로 다차원 질의는 마치 사용자가 큐브 일부분을 자신이 원하는 형태로 절단하여 살펴보는 것입니다.
- OLAP 시스템
- Amazon Redshift
- HP Vertica
- Teradata
Reference
'BI > DW' 카테고리의 다른 글
| data mesh와 data fabric (0) | 2023.07.09 |
|---|---|
| 데이터 레이크와 클라우드 DW (0) | 2023.03.24 |
| 데이터 모델링과 DW/DM (1) | 2023.03.20 |
