실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
Trino 성능 최적화
- CBO와 Cost-based Join Enumeration : CBO는 전체 쿼리 실행 계획의 최적화를 위한 것이며, Cost-based Join Enumeration은 그중에서도 특히 조인 순서 최적화에 초점을 맞춘 부분입니다
- CBO (Cost-Based Optimizer)
- CBO는 전반적인 쿼리의 최적화를 위해 개발되었습니다.
- 쿼리 플랜에 포함된 여러 연산자(조인, 필터, 집계 등) 사이의 상호 작용을 고려하여 쿼리의 전체 실행 비용을 최소화하도록 설계되었습니다.테이블 통계, 칼럼 통계, 데이터 분포 등의 메타 데이터 정보를 기반으로 작동합니다. 이러한 통계 정보를 사용하여 각 연산자의 비용을 추정하고, 최적의 쿼리 실행 계획을 선택합니다.
- Cost-based Join Enumeration
- 조인 연산은 데이터베이스 쿼리 처리에서 가장 비용이 많이 드는 연산 중 하나입니다. 따라서 조인의 순서와 방식을 어떻게 결정하느냐에 따라 쿼리의 전체 실행 시간에 큰 영향을 미칠 수 있습니다.
- Cost-based Join Enumeration은 여러 테이블 간의 조인 순서를 최적화하는 특정 부분에 초점을 맞춥니다. 여러 테이블을 조인할 때 가능한 모든 조인 순서의 비용을 추정하고, 가장 효율적인 조인 순서를 결정합니다.
- CBO (Cost-Based Optimizer)
- Trino 쿼리 성능에 영향을 미치는 네 가지 주요 요소 및 최적화
- 컴퓨팅 리소스
- 리소스 집약적인 애플리케이션인 Trino는 데이터 처리에 많은 CPU 성능을 사용하고 메모리를 소비하여 소스 데이터, 중간 결과 및 최종 출력을 저장합니다. 워크로드와 사용 가능한 하드웨어 리소스를 염두에 두고 각 노드의 CPU 코어 수와 메모리 양의 균형을 맞추는 것이 중요합니다.
- I/O 속도
- Trino는 스토리지 독립적인 쿼리 엔진이므로 로컬 디스크에 데이터를 저장하지 않습니다. 대신 외부 스토리지 시스템에서 데이터를 가져옵니다. 이것은 Trino의 쿼리 성능이 스토리지 시스템과 네트워크의 속도에 크게 영향을 받는다는 것을 의미합니다.
- I/O 개선(스토리지 및 네트워크)
- I/O 처리량이 낮거나 네트워크 대기 시간이 길면 데이터를 가져오는 동안 쿼리가 대기하거나 차단될 수 있습니다. 따라서 컴퓨팅 리소스를 최적화하는 것 외에 대기 및 차단된 쿼리에 대한 솔루션은 I/O를 개선하는 것입니다.
- I/O를 가속화하는 몇 가지 방법입니다.
- 더 빠른 스토리지 사용: Amazon S3의 핫 스토리지 계층과 같은 더 빠른 스토리지 시스템은 데이터 검색 속도를 향상시킬 수 있습니다.
- 네트워크 대기 시간 감소: 데이터 전송 지연을 최소화하려면 Trino와 스토리지 시스템 간에 대기 시간이 짧은 네트워크 연결을 설정해야 합니다.
- 캐싱: 캐싱은 Trino 작업자에게 데이터 지역성을 제공하여 원격 데이터 읽기를 크게 가속화할 수 있습니다.
- 테이블 스캔
- 테이블 스캔은 커넥터에서 데이터를 가져오고 다른 운영자가 사용할 데이터를 생성합니다. 이는 특히 대규모 데이터 세트로 작업할 때 또 다른 성능 병목 현상이 될 수 있습니다. 테이블이 분할되는 방식과 Parquet 및 ORC와 같은 파일 형식의 선택은 쿼리 속도에 큰 차이를 만들 수 있습니다.
- 조인
- 많은 테이블의 데이터를 병합하는 조인은 Trino에서 가장 리소스를 많이 사용하는 작업으로 알려져 있습니다. 조인이 효율적으로 수행되지 않으면 과도한 CPU 및 메모리 리소스를 소비하여 전체 Trino 클러스터 속도가 느려질 수 있습니다.
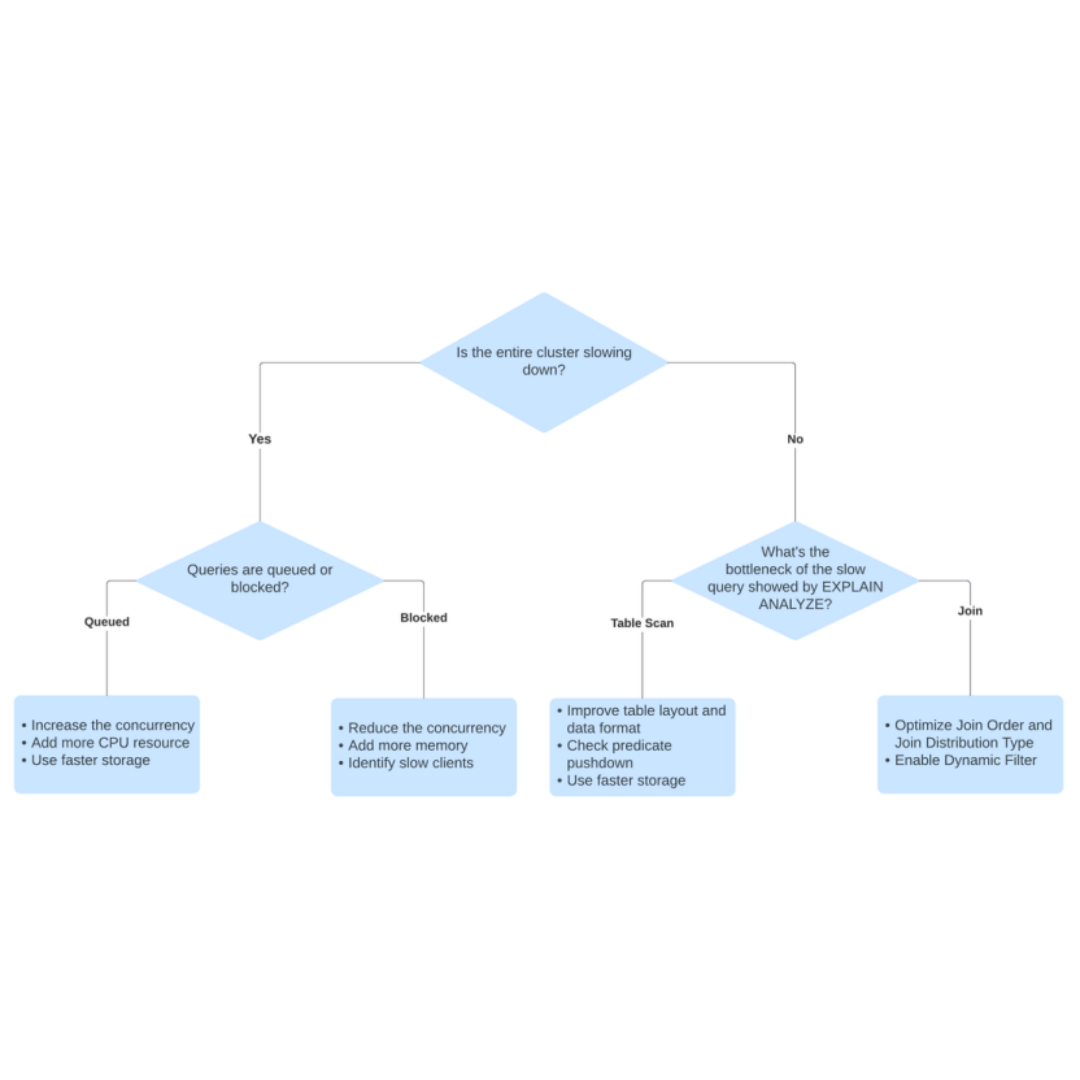
- 컴퓨팅 리소스

- 전체 클러스터가 느려지고 있는지 아니면 몇 개의 쿼리만 특히 느린지를 판단합니다.
- 전체 클러스터가 느려지는 경우
- 자원이 부족하거나 자원 할당 및 최대 동시성 설정이 합리적이지 않을 수 있습니다. Trino는 많은 자원을 필요로 하는 컴퓨팅 엔진으로 자원이 부족한 경우 클러스터의 전반적인 처리량이 감소하는 것을 관찰할 수 있습니다.
- Trino는 각 쿼리에 대한 최대 메모리 및 최대 동시 쿼리 수를 설정하여 자원 할당을 제어할 수 있습니다. Trino 클러스터에 할당된 총자원을 기반으로 최대 쿼리 메모리와 최대 동시 쿼리 수 사이의 균형을 찾아야 합니다.
- Trino 클러스터의 웹 UI를 살펴보고 블로킹된 쿼리나 대기 중인 쿼리가 더 많은지 확인하여 적절한 조치를 취할 수 있습니다.
- 블로킹된 쿼리가 많은 것을 관찰하면 더 많은 메모리를 추가해 볼 수 있습니다. 전체 메모리 자원이 제한되어 있는 경우, Trino의 자원 그룹 설정을 사용하여 최대 동시 쿼리 수를 줄이는 것을 고려해야 합니다.
- 대기 중인 쿼리가 많이 있는 경우, 네트워크 또는 스토리지 대역폭을 향상시키거나 추가 리소스를 추가하거나 최대 동시성을 증가시켜 균형을 맞출 수 있습니다
- 리소스 관련 속성
- query.max-memory-per-node : 쿼리가 작업자에서 사용할 수 있는 최대 사용자 메모리 양
- query.max-memory : 쿼리가 전체 클러스터에서 사용할 수 있는 최대 사용자 메모리 양
- query.low-memory-killer.policy : 메모리 가용성이 낮은 경우 실행 중인 쿼리 종료를 처리하도록 동작을 구성
- 자원이 부족하거나 자원 할당 및 최대 동시성 설정이 합리적이지 않을 수 있습니다. Trino는 많은 자원을 필요로 하는 컴퓨팅 엔진으로 자원이 부족한 경우 클러스터의 전반적인 처리량이 감소하는 것을 관찰할 수 있습니다.
- 특정 쿼리 몇 개만 느린 경우
- EXPLAIN ANALYZE 결과를 사용하여 해당 쿼리의 주요 병목 현상을 식별한 다음 이러한 병목 현상에 대해 최적화를 수행할 수 있습니다.
- EXPLAIN ANALYZE에서 테이블 스캔 문제를 발견하면 파일 형식, 압축, 파티셔닝, 버킷팅 또는 정렬 방법에 주의를 기울여야 합니다.
EXPLAIN ANALYZE
SELECT custkey, sum(totalprice) AS total
FROM orders
WHERE
orderstatus = 'F' AND
orderdate BETWEEN
DATE '1995-01-01' AND DATE '1995-12-31'
GROUP BY custkey
ORDER BY total DESC
- 각 단계의 실행 통계를 검토함으로써 쿼리 실행 과정에서 병목 현상을 식별할 수 있습니다. 위의 예시에서 Fragment 4의 실제 CPU 비용은 34.09초이며, TableScan(Fragment 4의 하위 연산자)은 33.87초로 Fragment 4의 대부분의 CPU 사용량을 차지합니다.
- 성능 튜닝 시에는 주로 ScanFilterProject 부분에 초점을 맞추는 것이 좋습니다.
- Table scan : 더 나은 테이블 레이아웃을 구현하거나, Predicate pushdown(조인이나 집계 연산 등의 연산을 수행하기 전에 필요한 데이터를 미리 필터링하여 처리하는 것)를 적용하거나, 더 빠른 스토리지를 사용하는 것을 고려
- Join : 조인 분배 유형(join distribution type)과 조인 순서(join order)를 최적화
File Formats and Table Layouts 최적화
- 데이터의 최적의 파일 형식, 압축, 파티셔닝, 버킷팅 및 정렬을 선택하는 것은 쿼리 성능에 큰 영향을 미칠 수 있습니다. ORC나 Parquet과 같은 컬럼 기반의 형식을 선택하고, Predicate pushdown를 지원하는 형식을 사용하는 것이 좋습니다. 즉 데이터 저장 및 검색을 최적화하기 위해 파티셔닝과 버킷팅을 활용하며, 저장 공간과 쿼리 속도를 균형 있게 유지하기 위해 적절한 압축 알고리즘을 적용해야 합니다.
- ORC는 Trino에서 최적화된 기록이 더 길어서 일반적으로 Parquet보다 성능이 우수합니다.
- 칼럼형 데이터 파일 포맷과 압축
- Trino가 Parquet 또는 ORC와 같은 컬럼 기반 데이터 파일을 읽을 때, 먼저 파일 끝에 저장된 footer 형식의 파일 메타데이터를 읽습니다. 이 메타데이터는 데이터 파일의 구조와 각 데이터 섹션의 위치(예: Parquet 파일의 로우 그룹)를 결정합니다.
- 데이터 페이지를 병렬로 읽어서 Trino는 많은 스레드를 사용하여 칼럼 데이터를 효율적으로 읽고 처리합니다. 칼럼 기반 형식은 불필요한 칼럼을 건너뛰고 메타데이터에 저장된 통계 정보를 기반으로 프리디케이트 푸시다운을 가능하게 하여 쿼리 성능을 최적화합니다.
- 메타데이터에는 데이터의 스키마, 행 수, 사용된 압축 코덱, 파일 내 각 데이터 섹션의 오프셋과 같은 정보가 포함됩니다.
- 메타데이터를 읽은 후, Trino는 병렬로 데이터 페이지를 읽습니다. 다른 부분의 데이터를 동시에 읽기 위해 여러 스레드를 사용합니다.
- Partitioning and Bucketing 전략
- 파티셔닝은 일부 열(파티션 열 또는 파티션 키)의 값에 따라 테이블을 여러 부분으로 나눕니다. 단일 테이블에서 과도한 파티션이 있으면 계획 단계에서의 성능 저하와 폴더 및 데이터 파일의 증가로 인한 저장 공간 압박이 발생할 수 있습니다
- 예를 들어, 고객 ID를 파티션 키로 사용하면 수백만 명의 고객이 있는 경우 수백만 개의 파티션이 생성될 수 있습니다. 이러한 경우 해시 파티셔닝의 간단한 형태인 버킷팅(bucketing)을 고려해야 합니다. 하나 이상의 열을 기반으로 테이블을 버킷팅하고, 고정된 수의 해시 버킷을 활용합니다.
CREATE TABLE my_table (
column1 string,
column2 int,
...
)
WITH (
partitioned_by = ARRAY['partition_column'],
bucketed_by = ARRAY['bucketing_column'],
bucket_count = 100
)Hive 테이블 통계를 수집하고 사용
- Hive 테이블의 통계 정보를 수집하고 업데이트하는 것은 Trino 옵티마이저가 쿼리를 계획할 때 더 나은 결정을 내리는 데 도움이 됩니다.
- Hive 테이블 통계를 수집하고 유지함으로써 옵티마이저가 가장 정확한 정보를 가지도록 할 수 있습니다.
-- 테이블의 현재 통계를 표시
SHOW STATS FOR table_name;
-- 테이블의 통계를 수집
ANALYZE table_name
-- Hive 테이블의 특정 파티션에 대한 통계를 갱신하려면 해당 파티션의 파티션 키 값을 지정
ANALYZE table_name WITH (
partitions = ARRAY[
ARRAY['Dec', '1'], ARRAY['Dec', '2']])
-- 일부 열에 대해서만 통계를 수집할 수 있음. 조인 키, 그룹 키 및 필터링 키에 초점을 맞춤
ANALYZE table_name WITH (
columns = ARRAY['column1', 'column2'])- Trino는 통계에 기반하여 SQL 계획을 최적화할 수 있으며, 이를 통해 쿼리에 대한 더 나은 조인 순서와 조인 유형이 결정됩니다.
Join 최적화
Trino의 CBO는 테이블 통계를 기반으로 가장 효과적인 조인 방법을 결정할 수 있습니다

- Trino는 하나의 테이블을 메모리로 읽어들인 후 다른 테이블을 스캔하는 동안 해당 값을 재사용하는 해시 조인 알고리즘을 사용합니다. 작은 테이블은 일반적으로 메모리를 절약하고 동시성을 향상시키기 위해 빌드 테이블로 선택됩니다.
조인 분배 유형
- Trino는 항상 해시 조인 알고리즘을 사용합니다. Trino는 한 테이블을 메모리에 한 번 읽어 들이고 다른 테이블의 데이터를 스캔하는 동안 해당 값을 재사용하는 것이 더 효율적입니다.
- 메모리를 절약하고 Trino 클러스터의 최대 동시성을 향상시키기 위해서는 작은 테이블을 빌드 테이블(메모리에 읽어 들인 테이블, 다른 테이블은 Probe Table이라 함)로 선택하는 것이 좋습니다.
- Trino는 해시 기반 조인 알고리즘을 사용합니다. 이는 각 Trino 워커가 빌드 테이블로부터 해시 테이블을 구축한다는 의미입니다. 그런 다음 Trino는 프로브 테이블을 스트리밍 하며, 각 행에 대해 해시 테이블을 조회하여 일치하는 행을 찾습니다.
- 조인 분포의 두 가지 유형
- 파티셔닝(Partitioned): 각 노드는 빌드 테이블의 일부 데이터만을 사용하여 해시 테이블을 구축합니다.
- 브로드캐스트(Broadcast): 각 노드는 모든 데이터에서 해시 테이블을 구축하며, 즉 빌드 테이블 데이터가 각 노드에 복제됩니다.
SET SESSION join_distribution_type = AUTOMATIC -- BROADCAST, PARTITIONED조인 순서 최적화
- Trino는 기본적으로 비용 기반 조인 순서 선택을 사용합니다. 테이블 통계를 사용하여 다양한 조인 순서의 비용을 추정하고, 계산된 비용이 가장 낮은 조인 순서를 자동으로 선택합니다.
-- ELIMINATE_CROSS_JOINS: 불필요한 크로스 조인을 제거
-- NONE: 순수하게 구문적인 조인 순서를 사용
SET SESSION join_reordering_strategy = AUTOMATIC동적 필터링(Dynamic Filtering)

- Trino가 브로드캐스트 조인을 사용할 때, 각 워커는 빌드 테이블에서 값을 수집하고, 입력이 완료된 후 빌드 측에서 생성된 동적 필터를 프로브 측의 테이블 스캔에 적용합니다. 동적 필터는 프로브 측에서 읽는 행의 수를 크게 줄일 수 있습니다. 동적 필터링은 조인 작업 중 처리되는 데이터 양을 줄여 쿼리 성능을 향상시킬 수 있습니다.
-- 동적 필터링은 기본적으로 활성화, 비활성화시
SET SESSION enable_dynamic_filtering = falseSyntactic join order
비용 기반 최적화를 사용하지 않는 경우 Trino는 기본적으로 구문 조인 순서를 사용합니다. 이 경우 쿼리를 최적화하는 공식적인 방법은 없지만 Trino가 조인을 구현하여 성능을 높이는 방법을 활용할 수 있습니다.
SELECT
*
FROM large_table l
LEFT JOIN medium_table m ON l.user_id = m.user_id
LEFT JOIN small_table s ON s.user_id = l.user_idReference
'Data Engeneering > presto' 카테고리의 다른 글
| Presto Query Processing (0) | 2023.02.04 |
|---|---|
| presto tuning (0) | 2023.02.04 |
| trino (1) | 2023.01.24 |
| Presto (0) | 2023.01.24 |
