실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/presto_tuning.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
Presto 조인 및 정렬 알고리즘 선택
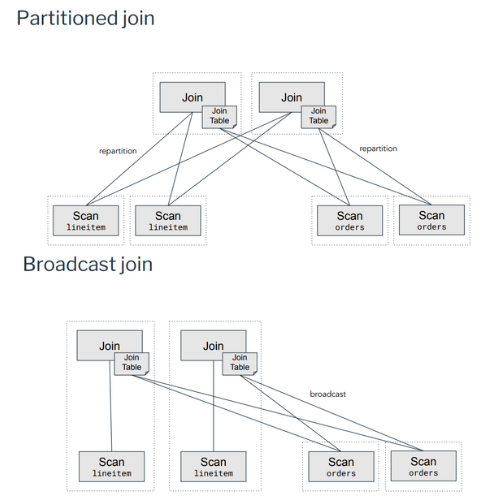
Partitioned

- Partitioned : 쿼리에 참여하는 각 노드는 데이터의 일부에서 해시 테이블을 작성합니다.
- Presto에서 사용되는 기본 조인 알고리즘은 분산된 PARTITION 조인입니다. 이 알고리즘은 조인 키의 해시 값을 사용하여 왼쪽 테이블과 오른쪽 테이블을 모두 분할합니다. 분할된 조인은 쿼리를 처리하기 위해 여러 작업자 노드를 사용합니다.
- 일반적으로 더 빠르고 더 적은 메모리를 사용합니다.
- -- SET SESSION join_distribution_type = 'PARTITIONED'
Broadcast

- Broadcast : 쿼리에 참여하는 각 노드는 모든 데이터에서 해시 테이블을 작성합니다.(데이터는 각 노드에 복제됨).
- 조인 테이블 중 하나가 매우 작은 일부 경우 분산 PARTITION 조인을 사용하여 네트워크를 통해 데이터를 분할하는 오버헤드가 조인 작업에 참여하는 모든 노드에 전체 테이블을 브로드캐스트하는 이점을 초과할 수 있습니다. 이러한 경우 'BROADCAST' 조인이 더 잘 수행될 수 있습니다.
- BROADCAST 조인을 사용하는 경우 조인 절에서 먼저 큰 테이블을 지정한뒤에 매직 코멘트를 지정하여 BROADCAST 조인을 활성화할 수 있습니다.
- -- SET SESSION join_distribution_type = 'BROADCAST'
- 이 옵션은 올바른 조인 테이블이 모든 노드에 복사되므로 더 많은 메모리를 사용합니다.
정렬 알고리즘
- ORDER BY 절이 있는 쿼리의 경우 Presto는 기본적으로 분산 정렬을 사용합니다. 정렬 작업은 여러 노드에서 병렬로 실행되며 단일 노드가 최종 결과를 병합합니다.
- 그러나 단일 노드 정렬 작업이 더 잘 수행되는 경우가 있을 수 있습니다. 이러한 경우 매직 코멘트를 사용하여 분산 정렬을 비활성화할 수 있습니다.
- -- set distributed_sort=false
- 분산 정렬을 비활성화하면 단일 노드의 메모리가 더 많이 사용됩니다. 최대 메모리 제한으로 인해 쿼리가 실패할 수 있습니다.
Presto 튜닝
- CREATE TABLE AS SELECT 문을 사용하여 쿼리 결과 출력 프로세스를 병렬화할 수 있습니다.
- 쿼리를 실행하기 전에 테이블을 DROP하면 성능이 크게 향상합니다. 결과 출력 성능은 SELECT *를 실행하는 것보다 5배 빠릅니다.
- DROP TABLE을 사용하지 않고 Presto는 JSON 텍스트를 사용하여 쿼리 결과를 구체화합니다. 그리고 결과 테이블에 100GB의 데이터가 있으면 코디네이터는 쿼리 결과를 저장하기 위해 100GB 이상의 JSON 텍스트를 전송합니다. 따라서 질의 계산이 거의 끝나도 JSON 결과를 출력하는 데 시간이 오래 걸립니다.
- 1.쿼리 맨 위에 DROP TABLE 문을 추가합니다.
- 2.CREATE TABLE(테이블) AS SELECT 사용합니다.
DROP TABLE IF EXISTS my_result;
CREATE TABLE my_result AS
SELECT * FROM my_table;Presto는 각 쿼리의 메모리 사용량을 추적하는데 메모리를 많이 사용하는 작업 목록입니다.
- distinct
- approx_distinct() 같은 근사 집계 함수 사용합니다.
- COUNT(DISTINCT x)를 사용하는 대신 approx_distinct(x)를 사용하여 느린 메모리 소모 연산자를 사용하지 말아야 합니다
- UNION
- UNION 대신에 UNION ALL을 사용합니다.
- ORDER BY
- ORDER BY와 함께 LIMIT 사용합니다.
- GROUP BY (of many columns)
- GROUP BY 절 내의 카디널리티 고려
- GROUP BY 내의 필드 목록을 높은 카디널리티 순서로 신중하게 정렬하여 GROUP BY 기능의 성능을 향상
- 좋은 쿼리 : SELECT GROUP BY uid, gender
- 나쁜 쿼리 : SELECT GROUP BY gender, uid
- GROUP BY 열에 문자열 대신 숫자를 사용합니다. 숫자는 문자열보다 적은 메모리를 필요로 하고 비교가 더 빠르기 때문입니다.
- GROUP BY 내의 필드 목록을 높은 카디널리티 순서로 신중하게 정렬하여 GROUP BY 기능의 성능을 향상
- GROUP BY 절 내의 카디널리티 고려
- joins
- 큰 테이블부터 작은 테이블 순으로 테이블을 조인해야 합니다.
- 동등하지 않은 조인 조건을 사용하면 쿼리 처리 속도가 느려집니다.
- Presto는 기본적으로 브로드캐스트 조인을 수행하여 왼쪽 테이블을 여러 작업자 노드로 분할한 다음 오른쪽 테이블의 전체 복사본을 파티션이 있는 작업자 노드로 보냅니다. 오른쪽 사이드 테이블이 크고 작업자 노드의 메모리에 맞지 않으면 오류가 발생합니다.
- 분산 조인 사용
- 쿼리가 여전히 작동하지 않으면 세션 속성을 설정하는 매직 주석을 추가하여 분산 조인을 사용합니다.
- 분산 조인 알고리즘 은 조인 키의 해시 값을 분할 키로 사용하여 왼쪽 및 오른쪽 테이블을 모두 분할합니다. 오른쪽 사이드 테이블이 크더라도 작동합니다. 그러나 네트워크 데이터 전송 횟수를 늘릴 수 있으며 일반적으로 브로드캐스트 조인보다 느립니다.
DROP TABLE IF EXISTS my_result;
-- set session join_distribution_type = 'PARTITIONED'
CREATE TABLE my_result AS
SELECT ... FROM large_table l, small_table s WHERE l.id = s.id- 열 저장 특성
- 너무 많은 열을 선택하면 쿼리 처리 속도가 느려집니다.
- 쿼리 결과 크기
- 너무 많은 행을 생성하려면 시간이 걸립니다. 대신 CREATE TABLE AS... 또는 INSERT INTO 또는 result_output_redirect 매직 코멘트를 사용합니다.
- 필요한 열 지정
- 시간 기반 파티셔닝 활용
- 일련의 LIKE 절을 하나의 단일 regexp_like 절로 집계
Reference
'Data Engeneering > presto' 카테고리의 다른 글
| Trino 최적화 (2) | 2023.07.01 |
|---|---|
| Presto Query Processing (0) | 2023.02.04 |
| trino (1) | 2023.01.24 |
| Presto (0) | 2023.01.24 |
