실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/BI/data_lake.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
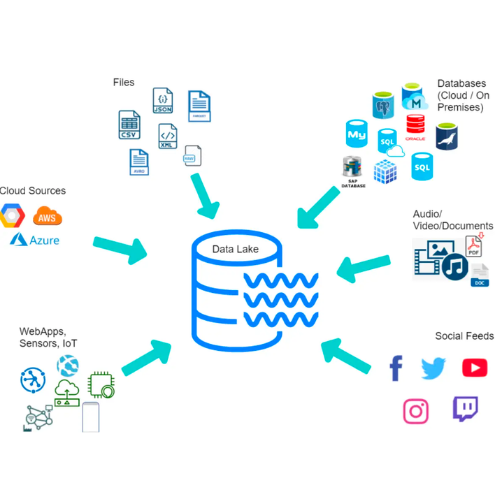
데이터 레이크

https://vitalflux.com/data-lake-design-principles-best-practices/ - 데이터 레이크는 추후에 특정한 용도로 사용될, 필터링되지 않은 이질적인 데이터를 대량으로 저장합니다.
- 데이터 레이크는 다양한 형식의 데이터를 원본 형식 또는 때에 따라 비정형 형식으로 저장합니다. 데이터 레이크는 데이터를 저장하기에는 더 저렴하지만 웨어하우스의 정형화된 데이터와 같은 방식으로 쿼리하는 데 최적화되어 있지 않습니다.
- 데이터 레이크는 페타바이트 규모의 정형, 반정형, 비정형 데이터를 집계하기 위한 중앙 데이터스토어가 됐습니다. 데이터의 버전 관리 및 롤백을 지원해야 합니다.
- 복제본 간의 일관성 보장, 기본 데이터의 스키마 진화, 부분 업데이트 지원, 기존 데이터 업데이트를 위한 ACID 일관성 등과 같은 데이터 수명주기 관리 작업들이 있는데 데이터 레이크가 중앙 데이터 웨어하우스로 인기를 얻기는 했지만, 전통적인 데이터 수명주기 관리 작업에 대한 지원은 부족합니다.
- 지원되는 파일 형식
- 데이터 형식은 포맷의 견고성(즉, 데이터 손상 시나리오에 대해 포맷이 얼마나 잘 테스트됐는지)과 널리 사용되는 SQL 엔진 및 분석 플랫폼과의 상호 운용성에 대한 부분에서 균형을 맞춰야 합니다.
- 표현성 : 포맷이 지도, 레코드, 목록, 중첩된 데이터 구조 등과 같은 복잡한 데이터 구조를 표현할 수 있는가?
- 견고성 : 포맷이 잘 정의돼 있고 쉽게 이해할 수 있는가? 손상 시나리오와 기타 예외 케이스에 대해 테스트가 잘됐는가? 견고성의 다른 중요한 측면은 포맷의 단순성. 형식이 복잡할수록 직렬화 및 역직렬화 드라이버에서 버그가 발생할 가능성이 높아집니다.
- 공간 효율성 : 데이터의 간결한 표현은 언제나 최적화의 기준이 됨. 공간 효율성은 데이터를 이진으로 표현하는 능력과 데이터를 압축하는 능력이라는 두 가지 요소를 기반으로 합니다.
- 액세스 최적화 : 응용프로그램 쿼리에 대한 응답으로 액세스 되는 데이터양(바이트)을 최소화함. 이는 쿼리 유형에 따라 크게 달라지며, 어디에나 적용 가능한 방법은 없습니다(select * 쿼리 vs 제한된 수의 열 값을 기반으로 필터링하는 쿼리). 액세스 최적화의 또 다른 고려 사항은 병렬 실행을 위한 파일을 분할하는 기능
- 주요 포맷
- 텍스트 파일 : 가장 오래된 형식 중 하나. 사람이 읽을 수 있고 상호 운용이 가능하지만, 공간과 접근 최적화 측면에서 상당히 비효율적
- CSV/TSV : 이 형식에는 비효율적인 이진 표현과 액세스에 관련된 제한이 있음. 또한 복잡한 데이터 구조를 이 형식으로 표현하기는 어려움
- JSON : 이 형식은 애플리케이션 개발자에게 가장 표현성이 있고 범용적인 형식 중 하나. 이 목록의 다른 형식과 비교하면 공간 및 액세스 측면 모두에서 최적화되지 않았음
- SequenceFile : Hadoop에서 가장 오래된 파일 형식 중 하나. 데이터는 키-값 쌍으로 표시됨. 자바가 쓰기 가능한 인터페이스를 사용해 Hadoop에 액세스하는 유일한 방법이었을 때 인기가 있었음. 가장 큰 문제는 상호 운용성이었고, 일반적인 정의가 없었음
- Avro : 스키마가 파일 헤더와 함께 저장된다는 점을 제외하면 SequenceFile과 유사함. 형식은 표현성이 있고 상호 운용이 가능함. 이진 표현에는 오버헤드가 있으며, 최적화가 최고로 잘된 것은 아님. 전반적으로 범용 워크로드에 적합함
- ORCFile : 고급 사용 데이터베이스에서 사용되는 열 기반 포맷. Hadoop 에코시스템에서 이 포맷은 RCfile 포맷의 후속 포맷으로 여겨지고 있는데, 이는 데이터를 문자열로 저장하는 데 비효율적이었음. ORCFile은 강력한 Hortonworks 지원과 최근의 흥미로운 발전을 통해 PPD(Push Predicate Down)와 향상된 압축 기능을 제공함
- Parquet : ORCFile과 유사하며 클라우데라의 지원을 받음. Parquet는 구글 Dremel논문의 최적화를 구현함
- 인코딩과 함께 사용할 수 있는 다양한 압축 기술로 zlib, gzip, LZO, Snappy 등이 널리 사용됩니다.
- 데이터 형식은 포맷의 견고성(즉, 데이터 손상 시나리오에 대해 포맷이 얼마나 잘 테스트됐는지)과 널리 사용되는 SQL 엔진 및 분석 플랫폼과의 상호 운용성에 대한 부분에서 균형을 맞춰야 합니다.
- 고충
- 원시 데이터 수명주기 작업에 자동화된 API가 없고 재현성 및 롤백, 데이터 제공 계층 프로비저닝 등에 대한 엔지니어링 전문 지식이 필요합니다.
- 동시 읽기-쓰기 작업에 대한 레이크의 일관성 부족을 수용하기 위해 애플리케이션을 이용한 대체 해결 방법이 필요합니다.
- 규정 준수를 위해 고객의 기록을 삭제하는 것과 같은 증분 업데이트의 최적화 수준이 매우 낮습니다.
- 스트림 일괄 처리를 결합한 통합 데이터 관리가 불가능합니다.
- 대체 방안들은 일괄 처리 및 스트림(람다 아키텍처라고 함)에 대해 별도의 처리 코드 경로를 필요로 하거나 모든 데이터를 이벤트(카파 아키텍처라고 함)로 변환해야 하는데, 이는 대규모 관리가 쉽지 않습니다.
클라우드 DW
- 클라우드 데이터 웨어하우스
- 원래 데이터 웨어하우스는 온프레미스 서버 내에 구축, 많은 경우 향상된 거버넌스, 보안성, 데이터 주권, 개선된 대기시간을 제공함, 온프레미스 데이터 웨어하우스는 탄력적이지 않기 때문에, 미래 수요에 대비해 데이터 웨어하우스를 확장하려면 복잡한 예측 과정을 거쳐야 합니다. 온프레미스 데이터 웨어하우스는 관리도 매우 복잡할 수 있습니다.
- 클라우드 데이터 웨어하우스를 사용하면 기업이 데이터 웨어하우스를 지원하기 위해 하드웨어 및 소프트웨어 인프라를 구축하거나 관리할 필요 없이 데이터에서 가치를 추출하는 데에만 집중합니다.
- 이점
- 대규모 또는 가변 컴퓨트 또는 스토리지 요구사항에 대한 탄력적인 확장 지원
- 사용 편의성
- 관리 용이성
- 비용 절감
- 온프레미스 데이터 웨어하우스와 동일한 특성과 이점을 제공하면서, 동시에 유연성, 확장성, 민첩성, 보안 및 비용 절감과 같은 클라우드 컴퓨팅의 추가 이점까지 제공합니다.
- 시스템
- Amazon Redshift
- Redshift는 비즈니스 인텔리전스(BI) 도구와 원활하게 통합될 수 있는 Managed형 클라우드 데이터웨어 하우스 서비스
- 웨어하우스에 ETL(Extract, Transform, Load)만 있으면 현명한 비즈니스 의사결정을 내리기가 수월해집니다.
- Google BigQuery
- Google의 자체 데이터웨어 하우징 솔루션
- Dremel은 BigQuery에서 쿼리를 실행하는 데 사용되는 Google에서 개발한 강력한 쿼리 엔진입니다. Google에 의하면 Dremel은 매우 큰 데이터 세트에서 SQL과 같은 유사한 쿼리를 실행하고 단 몇 초만에 정확한 결과를 얻을 수 있는 쿼리서비스
- BugQuery 및 Dremel은 리소스를 할당하고 Dremel 작업에 데이터를 제공하는데 도움이 되는 Borg 및 Colossus와 같은 다른 Google 클라우드 기술을 활용할 수 있습니다.
- SnowFlake
- Redshift와 Snowflake는 관계형 데이터베이스 관리 시스템
- SaaS(Software-as-a-Service) 모델로 제공되는 구조화된 데이터와 반 구조화된 데이터 모두를 지원하는 데이터웨어 하우스
- Snowflake는 빠르고 사용자 친화적이며 기존 데이터웨어 하우스보다 더 많은 유연성을 제공합니다.
- Snowflake는 Snowflake Elastic Data Warehouse의 형태로 클라우드 기반 데이터 스토리지 및 분석을 제공, 사용자는 클라우드 기반 하드웨어 및 소프트웨어를 사용하여 데이터를 분석하고 저장할 수 있습니다.
- Amazon Redshift
Reference
'BI > DW' 카테고리의 다른 글
| data mesh와 data fabric (0) | 2023.07.09 |
|---|---|
| 데이터 모델링과 DW/DM (1) | 2023.03.20 |
| OLLTP vs OLAP (0) | 2023.03.19 |
