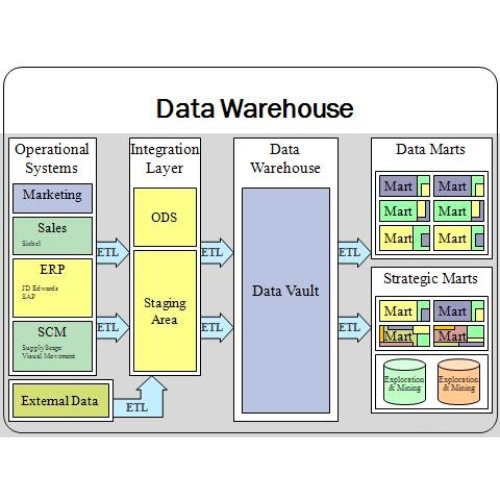
실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/BI/data_modeling_dw_dm.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
데이터 모델링
- 데이터 모델링
- 데이터모델링이란 현실에 존재하는 데이터를 전산화하기 위해 추상화 레벨을 결정하여 단순화, 가시화, 문서화시키는 작업
- 관리대상이 되는 정보를 추출하고 그 정보들 간의 관계를 설정하여 시각화하는 과정을 말합니다.
- 데이터 모델링을 하는 이유는 크게 효율과 성능 향상, 유연성 확보, 유지보수의 용이의 측면에서 생각할 수 있습니다.
- 읽기 스키마와 쓰기 스키마의 비교

https://www.oreilly.com/content/hadoop-what-you-need-to-know/ - 소스 데이터의 스키마 변경을 처리하는 한 가지 방법은 데이터를 쓸 때 스키마를 정의하는 방식(Schema-on-write)에서 데이터를 읽을 때 스키마를 정의하는 방식(schema-on-read)으로 설계를 이동하는 것입니다.
- 데이터 구조가 사전에 정의돼야 하는 (저장 시점 스키마 적용) 관계형 데이터베이스와는 달리 파일 시스템이나 오브젝트 스토어는 데이터를 어떻게 쓰든 상관하지 않습니다. 읽는 시점 스키마 적용하여 마찰 없는 주입이 가능하게 합니다.
- 쓰기 스키마(Schema-on-write)
- 소스에서 데이터를 추출할 때 구조(스키마)가 정의되고 데이터가 데이터 레이크 또는 S3 버킷에 기록됨, 그런 다음 수집의 로드 단계가 실행되면 데이터가 예측 가능한 형식의 정의된 테이블 구조로 로드될 수 있습니다.
- 관계형 데이터베이스의 전통적인 접근 방식으로 스키마는 명시적이고 데이터 베이스는 쓰여진 모든 데이터가 스키마를 따르고 있음을 보장합니다.
- 정적(컴파일 타임) 타입 확인과 비슷합니다.
- 읽기 스키마(Schema-on-read)
- 스키마에 대한 엄격한 정의 없이 데이터가 데이터 레이크, S3 버킷 또는 기타 스토리지 시스템에 기록되는 패턴으로 데이터의 스키마는 읽을 때까지 알 수 없으므로 schema-on-read라고 합니다. 즉, 데이터를 스키마에 맞게 데이터베이스가 기대하는 형태로 전환하기 전까지는 데이터를 저장할 수 없는 관계형 데이터베이스와는 달리 데이터를 아무런 처리 없이 저장할 수 있습니다.
- 데이터 구조는 암묵적이고 데이터를 읽을 때만 해석됩니다.
- 프로그래밍 언어에서 동적(런타임) 타입 확인과 유사합니다.
- 이 패턴은 스토리지에 데이터를 쓰는 데는 매우 효율적이지만 로드 단계에 복잡성을 추가하고 파이프라인에서 몇 가지 주요 의미를 갖습니다. 기술적인 관점에서 S3 버킷에서 이러한 방식으로 저장된 데이터를 읽는 것은 매우 쉬웁니다.
- 로드 단계에서 스키마가 유연한 데이터를 읽는 데 사용하는 모든 도구와 통합되는 데이터 카탈로그를 활용합니다. 데이터 카탈로그는 데이터 레이크 및 웨어하우스의 데이터에 대한 메타데이터를 저장하고 데이터세트의 구조와 정의를 모두 저장할 수 있습니다. AWS Glue 데이터 카탈로그 및 Apache Atlas는 널리 사용되는 데이터 카탈로그입니다.
- 로드 단계의 논리는 더욱 복잡해집니다. 스키마 변경을 동적으로 처리하는 방법을 고려해야 합니다.
- 데이터 카탈로그 작성뿐만 아니라 조직에서 데이터가 사용되는 방식에 대한 표준 및 프로세스를 정의하는 데이터 거버넌스에 대해 진지하게 고민해야 합니다.
다차원 모델링
- 다차원 모델링
- 분석업무의 복잡한 질의의 신속한 처리를 목표로 분석영역별 특성을 고려하여 DBMS의 성능과 사용의 편리성을 보장한 구조로 설계하는 것입니다.
- 사용자는 다양한 관점에서의 비즈니스 분석을 요구하고, 이를 지원하기 위해 데이터모델은 다차원의 형식으로 표현하고 정보 분석을 위해 다소 복잡한 통합 DW의 데이터를 직접 액세스 하기보다는 별도의 다차원 데이터 모델을 통해 신속하고 사용자가 쉽게 이해할 수 있는 기반을 제공합니다.
- 장점
- 전사적인 비즈니스 View를 제공
- 포괄적인 데이터 검색 및 분석을 가능
- 단점
- 비즈니스 사용자가 모델을 이해/분석하기가 곤란
- Tool에서 제공하는 Query가 효과적이지 못함
- 물리적인 질의 성능 저하
- Denormalization 필요
- 다차원모델링 방법
- 정규화된 데이터 모델은 중복과 필드 수가 작은 테이블을 만들다 보니 업데이트가 매우 빠르게 이뤄집니다.
- 데이터 웨어하우스에서는 일반적으로 정규화하지 않는 데이터 모델을 선호하며 정규화하지 않은 모델에서는 각 테이블에 가능한 한 많은 관련 특성을 저장합니다. 그러면 필요한 모든 정보를 취합할 때도 데이터를 한 번만 처리해도 됩니다.
- Star Schema(차원 모델링(dimensional modeling))

https://www.oreilly.com/library/view/hands-on-business-intelligence/9781838824303/01337b15-338a-4527-8870-32782a65f522.xhtml - 1996년에 발간된 랄프 킴벌, 마기 로스 공저의 The Data Warehouse Toolkit(wiley,2004) 1판에서 처음 소개되었으며 몇 개의 차원과 팩트 테이블 집합으로 구성됩니다. 테이블 관계가 시각화될 때 사실 테이블이 가운데에 있고 차원 테이블로 둘러싸고 있다는 사실에 비롯됐습니다.
- 스타 스키마는 데이터를 비정규화합니다. 일부 차원 테이블에 중복 열을 추가하여 데이터를 더 빠르고 쉽게 쿼리하고 작업할 수 있습니다. 계산 비용이 많이 드는 조인 작업을 피함으로써 쿼리 속도를 높이기 위해 데이터 모델의 일부 중복성(데이터 중복)을 교환하는 것입니다.
- 팩트 테이블은 정규화되지만 차원 테이블은 정규화되지 않습니다. 팩트 테이블의 데이터는 팩트 테이블에만 존재하지만 차원 테이블은 중복 데이터를 보유할 수 있습니다.
- 팩트 테이블에는 각 차원과 관련된 모든 활동이 기록됩니다.
- 팩트 테이블은 스타스키마상에서 유일하게 정규화된 테이블로써 외래키(Foreign Key)와 상세 데이터(Numeric Data) 값을 가지는 열(Column)로 구성됩니다.
- 차원 테이블은 분석 대상 요소로 구성됩니다.
- 차원이란 사용자가 데이터를 분석하고자 하는 주어진 사실(Fact)에 대한 추가적인 또는 주요한 관점(View)을 제공하는 특성을 가집니다. 차원 테이블은 서술적(Descriptive) 정보를 저장하며 비정규화된(Denormalized) 데이터구조를 가집니다.
- Snowflake Schema
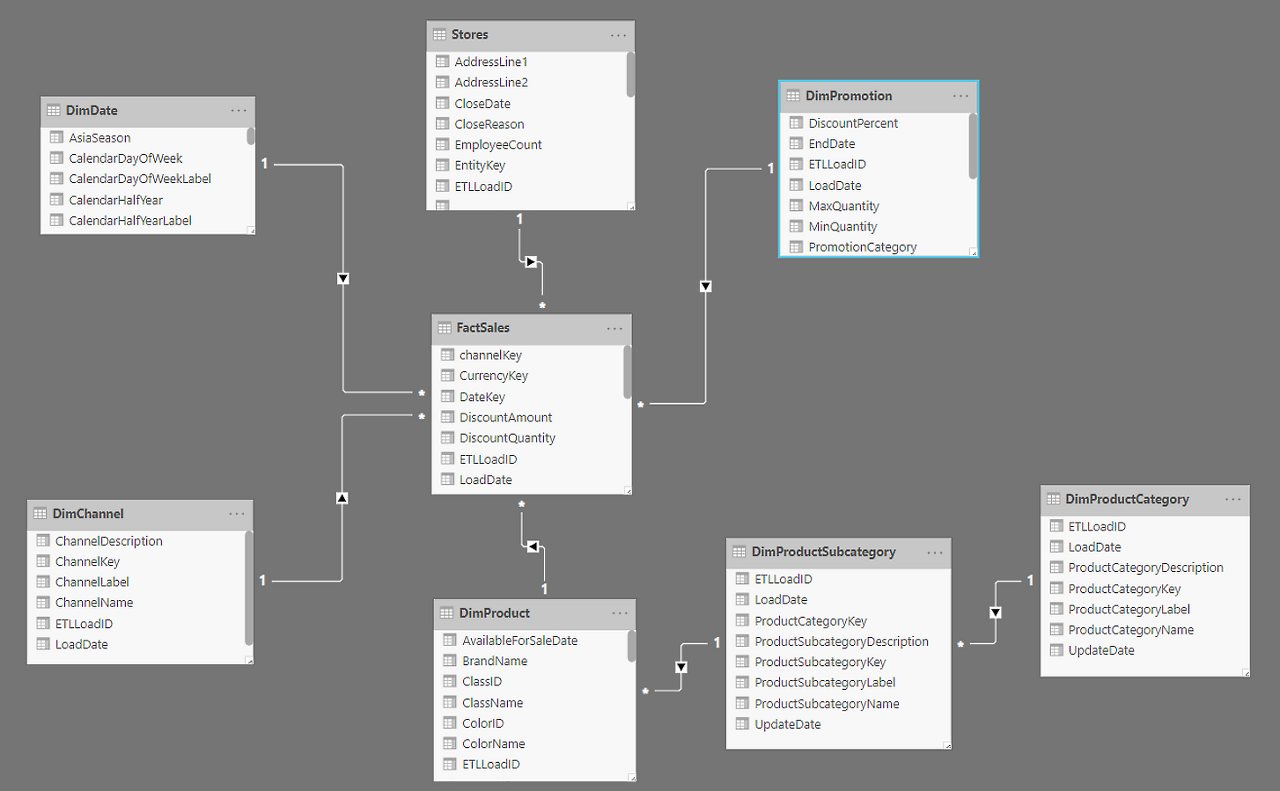
https://www.oreilly.com/library/view/hands-on-business-intelligence/9781838824303/01337b15-338a-4527-8870-32782a65f522.xhtml - 차원이 하위차원으로 더 세분화됩니다.
- 스타스키마의 팩트(Fact) 테이블 구조와 동일하게 유지하면서 차원테이블이 정규화 (일반적 제3 정규형)된 구조로 저장공간을 최소화합니다.
- 제3 정규형(3NF - Third Normal Form)은 정규화를 통해 데이터 중복성을 줄이는 방법입니다. 완전히 정규화된 것으로 간주되는 데이터베이스의 공통 표준입니다.
- Star Schema vs Snowflake Schema

https://www.javatpoint.com/data-warehouse-star-schema-vs-snowflake-schema - Snowflake 스키마는 높은 정규화 표준을 보다 엄격하게 준수하기 때문에 스토리지 효율성이 더 높지만 쿼리 성능은 비정규화된 데이터 모델만큼 좋지 않습니다. 스타 스키마와 같은 비정규화된 데이터 모델은 데이터 중복이 더 많아 중복 데이터 비용으로 쿼리 성능이 더 빨라집니다.
| 구분 | Star Schema | Snoflake Schema |
| 장점 | 간단한 모델링 기법, 사용자에게 친숙, Join 최소화로 성능 향상 | 적은 Storage 차지, 데이터 중복성 제거, 유연성, 관리의 용이성 제공 |
| 단점 | 데이터 중복 및 불일치 가능성, 많은 Storage 차지, Fact Table간 Join 어려움 | 복잡한 모델링 기법, 많은 조인작업으로 검색속도 저하, 높은 유지 보수 비용 |
DW/DM

https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0_%EB%A7%88%ED%8A%B8
| 영역 구분 | 목적 및 용도 |
| ODS 영역 | 원천 시스템에서 추출한 데이터를 적재한 후 변형, 정제 작업을 수행하는 영역, 원천 테이블의 구조를 거의 유지하고, 필요에 따라 임시 테이블을 생성/삭제 |
| DW 영역 | ODS의 데이터를 정제하여 주제별로 통합한 후 전사적인 관점에서 데이터 구축, 최종적으로 상세 수준까지 사용자 분석이 가능하도록 상세 데이터를 보유, 분석 도구 및 마트를 위한 원천 데이터 제공 |
| DM 영역 | 전사적 데이터 분석을 위하여 통합적으로 과거, 현재 데이터를 집약하여 유지, 보고서의 데이터 공급원으로 활용, 다차원 모델 적용, 사용빈도가 높은 데이터 유형에 대한 수행 속도 보장 |
- ODS
- ODS는 DW 데이터의 준비공간, 운영계 데이터를 가져와 정제, 통합, 변환, 보관하고 DW로 공급해 주는, DW로 가는 중간단계 의 데이터 저장장소
- ODS는 일반적으로 요약데이터가 아닌 원시 데이터를 포함하고 있기 때문에 향후 요구 조건 변화에 대응하기 쉽고 DW의 데이터에 문제가 생겼을 때 신속한 복구가 가능합니다.
- 데이터 웨어하우스(DW)
- 여러 다른 OLTP 시스템의 데이터를 합쳐 데이터 분석 목적으로 쓰기 위해 준비된 데이터베이스
- 데이터 웨어하우스는 비즈니스 인텔리전스(BI) 활동, 특히 분석을 활성화 및 지원하기 위해 설계된 데이터 관리 시스템의 한 유형으로 데이터를 저장 및 관리하기 위한 관계형 데이터베이스
- 데이터 웨어하우스 특성
- 절차 지향적(Subject-oriented) : 데이터 웨어하우스는 특정 절차 또는 기능 영역(예: 영업)에 대한 데이터를 분석할 수 있음
- 통합 : 데이터 웨어하우스는 이질적인 소스로부터 얻은 다양한 데이터 유형 간에 일관성을 생성
- 비 휘발성 : 일단 데이터 웨어하우스에 저장되면, 데이터는 안정적인 상태가 되며 변경되지 않음
- 시간 변이적 : 데이터 웨어하우스 분석은 시간 경과에 따른 변화를 확인함
- 엔터프라이즈 데이터 웨어하우스(EDW)
- 중앙 집중식 웨어하우스입니다. 전사적으로 의사 결정 지원 서비스를 제공합니다.
- 데이터를 구성하고 표현하기 위한 통합된 접근 방식을 제공합니다.
- 주제에 따라 데이터를 분류하고 해당 구분에 따라 액세스 권한을 부여하는 기능을 제공합니다.
- 데이터 마트(DM)
- 데이터 웨어하우스가 기업 전반의 중앙 데이터 스토리지 역할을 한다면, 데이터 마트는 일부 선택된 사용자 그룹에게 관련 데이터를 제공합니다. 데이터 액세스를 간소화하고, 분석 속도를 높이며, 자체 데이터에 대한 통제력을 부여하게 됩니다.
- 데이터 마트는 특정 요구에 맞는 처리된 데이터를 저장합니다.
Reference
'BI > DW' 카테고리의 다른 글
| data mesh와 data fabric (0) | 2023.07.09 |
|---|---|
| 데이터 레이크와 클라우드 DW (0) | 2023.03.24 |
| OLLTP vs OLAP (0) | 2023.03.19 |
