스노우 플레이크에 대해 알아보며 Hands-On Essentials data warehouse과정을 진행한 포스팅 내용입니다.
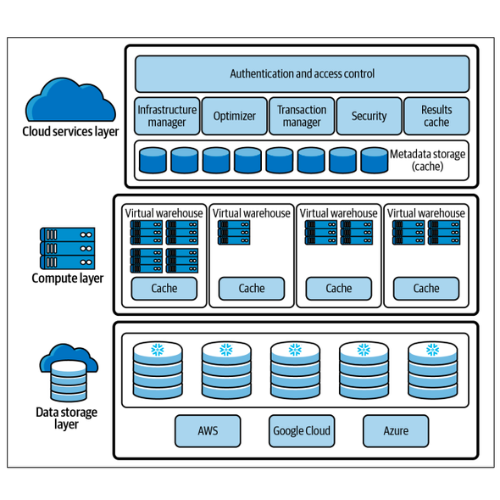
Snowflake 아키텍처

- 스노우플레이크의 고유한 설계는 저장소와 컴퓨팅을 물리적으로 분리하지만 논리적으로 통합하며, 보안 및 관리와 같은 서비스를 제공합니다.
- 스노우플레이크 하이브리드 모델 아키텍처는 세 개의 레이어로 구성되어 있습니다. 클라우드 서비스 레이어, 컴퓨팅 레이어, 데이터 저장소 레이어입니다.
클라우드 서비스 레이어
- Snowflake 클라우드 서비스 레이어는 인증, 액세스 제어 및 암호화와 같은 활동을 조정하는 서비스 모음입니다.
- 인프라 및 메타데이터 처리를 담당하는 관리 기능과 쿼리 구문 분석 및 최적화 기능을 포함합니다.
- 사용자가 로그인 요청을 시작하는 시점부터 사용자 요청을 처리하는 데 사용됩니다. 사용자가 Snowflake 쿼리를 제출할 때, SQL 쿼리는 처리를 위해 컴퓨팅 레이어로 전송되기 전에 클라우드 서비스 레이어 옵티마이저에게 전송됩니다.
- 클라우드 서비스 레이어는 데이터 정의 언어(DDL) 및 데이터 조작 언어(DML) 작업을 위한 SQL 클라이언트 인터페이스를 활성화하는 데 사용됩니다.
컴퓨팅 레이어
- 스노우플레이크 컴퓨팅 클러스터는 대개 가상 데이터 웨어하우스(Virtual Warehouse)라고 불리며, CPU, 메모리, 그리고 임시 저장소로 이루어진 동적 컴퓨팅 자원의 클러스터입니다.
- 대부분의 SQL 쿼리 및 테이블에 데이터를 로드 및 언로드하거나 테이블의 행을 업데이트하는 모든 DML 연산은 가상 데이터 웨어하우스가 실행 중이어야합니다.
- 저장소와 컴퓨팅을 분리하여 가상 창고 간 상호 작용이 없고 다른 가상 웨어하우스의 성능에도 영향을 주지 않는 것을 가능하게 합니다. 각 스노우플레이크 가상 창고는 독립적으로 작동하며 다른 가상 창고와 컴퓨팅 리소스를 공유하지 않습니다.
- 스노우플레이크 가상 창고는 언제든지 시작하고 중지하며, 실행 중에 크기를 조정할 수 있습니다. 스노우플레이크는 가상 웨어하우스를 확장하는 두 가지 방법을 지원합니다.
- 가상 웨어하우스를 조정함으로써 가상 창고를 확장
- 가상 웨어하우스에 클러스터를 추가함으로써 가상 웨어하우스를 확장
- 두 가지 방법을 동시에 사용할 수 있습니다.
- 가상 웨어하우스 크기 및 클러스터당 서버 수

데이터 저장소 레이어
- Snowflake의 중앙 집중화된 데이터 저장소 레이어는 구조화된 데이터 및 반정형 데이터를 포함하여 모든 데이터를 보유합니다.
- 백그라운드 파일 시스템은 Amazon, Microsoft 또는 Google Cloud에서 구현되며 데이터가 Snowflake에 로드되면 최적의 방식으로 재구성되어 압축된 열 형식으로 저장되며 Snowflake 데이터베이스에 유지됩니다
- 데이터 저장소 레이어 remote disk layer라고도 불리며 Snowflake는 저장할 수 있는 데이터 양이나 생성할 수 있는 데이터베이스 또는 데이터베이스 개체 수에 제한을 두지 않습니다.
- Snowflake 테이블은 쉽게 페타바이트의 데이터를 저장할 수 있습니다. Snowflake 계정의 저장소가 증가하거나 감소해도 가상 웨어하우스 크기에는 영향이 없습니다.
- Zero-Copy Cloning
- 사용자가 Snowflake 데이터베이스, 스키마 또는 테이블을 스냅샷 찍는 방법을 제공합니다.
- Zero-Copy Cloning은 메타데이터만 작업하므로 추가 저장소 비용이 발생하지 않습니다. 예를 들어 데이터베이스를 복제한 후 복제된 테이블에 새 테이블을 추가하거나 행을 삭제하면 그 때부터 저장소 비용이 책정됩니다.
- 백업을 생성하는 것 외에도 개발 및 테스트 환경을 지원하기 위해 Zero-Copy Cloning을 자주 사용합니다.
- Time Travel
- Time Travel을 사용하면 데이터베이스, 테이블 또는 스키마의 이전 버전을 복원할 수 있습니다. 이전에 잘못된 편집을 수정하거나 실수로 삭제한 항목을 복원할 수 있습니다.
- Time Travel을 사용하면 복제 기능과 결합하여 과거의 여러 지점에서 데이터를 백업하거나 더 이상 존재하지 않는 데이터베이스 개체를 간단한 쿼리를 통해 검색할 수 있습니다.
- 비용 책정
- Snowflake 데이터 저장소 비용은 압축된 데이터의 일일 평균 크기를 기준으로 계산됩니다.
- 저장소 비용은 영구적인 테이블 및 대량 데이터 로딩 및 언로딩을 위해 스테이징된 파일에 저장된 영구적인 데이터 비용을 포함합니다.
Snowflake 캐싱
- 쿼리를 제출하면 Snowflake은 해당 쿼리가 이전에 실행되었는지 그리고 결과가 여전히 캐시되어 있는지 확인합니다. 이전 결과가 여전히 사용 가능하면 제출한 쿼리를 실행하는 대신 캐시된 결과 집합을 사용합니다.
- 캐시된 쿼리 결과를 검색하는 것 외에도, Snowflake은 다른 캐싱 기술을 지원합니다.
Query Result Cache

- Snowflake 쿼리의 결과는 24시간 동안 캐시되어 유지되며, 그 후 삭제됩니다.
- 결과 캐시는 24시간 동안만 유지되지만, 쿼리가 다시 실행될 때마다 클럭이 리셋되어 최초 실행 시간으로부터 최대 31일까지 유지됩니다. 31일이 지나거나 기본 데이터가 변경되면, 다시 실행할 때 새 결과가 생성되어 캐시됩니다.
- 매개변수를 사용하여 캐시를 비활성화할 수 있습니다.
ALTER SESSION SET USE_CACHED_RESULT=FALSE;Metadata Cache

- 사용자는 메타데이터에 대한 일부 제어권을 가지지만 캐시에 대한 제어권은 없습니다.
- Snowflake는 테이블, 마이크로파티션 및 클러스터링에 대한 메타데이터를 수집하고 관리합니다. 테이블에 대해서는 행 수, 바이트 단위의 테이블 크기, 파일 참조 및 테이블 버전을 저장합니다.
- 테이블에서 SELECT COUNT(*)를 실행할 때 카운트 통계는 메타데이터 캐시에 유지됩니다.
- 메타데이터 캐시에 저장된 정보는 쿼리 실행 계획을 작성하는 데 사용됩니다.
virtual warehouse cache
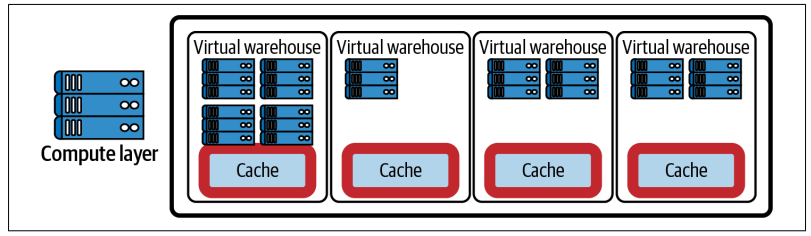
- 실행 중인 가상 웨어하우스는 쿼리를 처리할 때 중앙 데이터베이스 스토리지 레이어에서 가져온 마이크로파티션을 SSD 스토리지에 저장합니다. 이는 쿼리를 완료하는 데 필요합니다.
- 가상 웨어하우스의 SSD 캐시 크기는 가상 웨어하우스의 컴퓨팅 리소스 크기에 따라 결정됩니다
- 가상 웨어하우스 데이터 캐시는 크기가 제한되어 있으며 LRU(Least Recently Used) 알고리즘을 사용합니다.
- 가상 웨어하우스가 실행 중인 상태에서 쿼리를 수신하면 해당 웨어하우스는 Snowflake 원격 디스크 스토리지에 액세스하기 전에 먼저 SSD 캐시를 스캔합니다.
Reference
Snowflake: The Definitive Guide
스노우 플레이크 공홈 문서
'BI > Snowflake' 카테고리의 다른 글
| [Snowflake] Hands-On Essentials - data warehouse (0) | 2023.05.14 |
|---|---|
| [snowflake] snowflake 개요 (0) | 2023.05.13 |
| [streamlit] streamlit와 heroku를 이용한 Dashboard 제작 (0) | 2021.07.20 |
