실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Data%20Ingestion/embulk.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
Embulk
- 일반적인 데이터 처리 워크플로우
- 수집(Ingest/Collect) - 애플리케이션 로그, 유저 속성 정보, 광고의 인상, 서드파치쿠키
- 전처리(Enrich) - 봇의 액세스 로그 제외. IP 주소로 위치 정보 추가, user-agent의 구조화, 마스터 데이터를 사용해서 로그에 유저 속성 추가
- 분류, 집계, 분석(Model) - 데이터베이스에 추가, 분석 처리 시스템으로 전송, 압축해서 스토리지에 저장(아카이브), 통계 데이터로 기록
- 활용(Utilize) - 추천 엔진 API의 참조 데이터, 실시간 거래, BI 애플리케이션을 사용한 시각화
- Fluentd는 준실시간의 로그 활용을 할 때 첫 장애물인 로그 수집의 과제를 해결하기 위해 개발되었습니다. 각종 데이터의 입력과 수집을 Input 플러그인으로 지원하고, 데이터 가공을 Filter 플러그인으로 처리하며, Output 플러그인으로 여러 가지 미들웨어나 스토리지로 저장할 수 있습니다.
- 2가지 과제
- Fluentd의 설정 파일의 거대화와 가끔 일어나는 사업적인 사양 변경에 따라 설정 파일의 라인수가 증가하여 유지보수가 힘들게 되었습니다.
- 스트리밍 처리에 특화된 Fluentd는 정기적으로 벌크로드를 하여 데이터 처리 워크플로우를 만들기에는 적합하지 않습니다.
- 2가지 과제
- 데이터 워크플로우를 지원하는 도구
- 스트리밍 데이터 컬렉터 - fluentd - 액세스 로그 / 앱로그 / 서버로그
- 벌크 데이터 로더 - embulk - csv파일/ S3 / MySQL / PostgreWQL 등
- 워크플로우 관리 - digdag - ETL 처리의 자동화
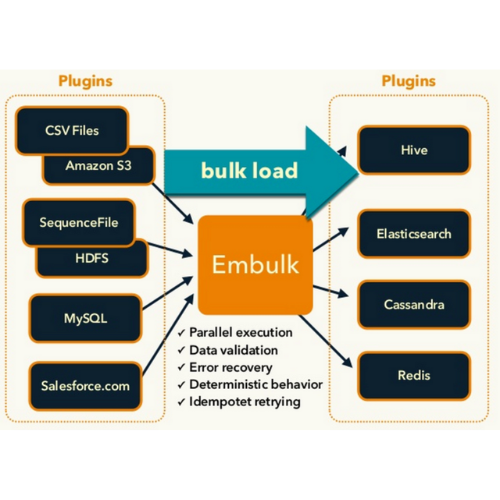
- Embulk
-

- Embulk는 Fluentd와 같이 Input/Filter/Output 플러그인을 조합해서 설정 파일을 정의합니다. 병렬 분산 처리에 대응한 성능과 재시도 제어 등에 안정성이 우수한 데이터 전송 파이프라인을 만들 수 있습니다.
- 다량의 데이터를 효율적으로 읽어서 CPU 코어를 최대한 사용해서 배치 처리하는 데 특화되어 있습니다.
- 데이터베이스와 스토리지에서 데이터를 읽어서, 임의의 처리를 한 뒤에 다른 보관 장소로 보내는 데이터의 대용량처리에 특화된 ETL 처리 도구
- Fluentd와 다른 특징으로 고속성과 트랜잭션 제어, 스키마를 사용한 데이터의 검사 기능이 있습니다.
- 대용량의 데이터를 마이크로 배치처리로 Redshift, BigQuery, Elasticsearch로 저장하는 경우라면 Fluentd 보다는 병렬처리, 처리량, 저장타이밍을 자유롭게 컨트롤할 수 있는 Embulk로 저장하는 편이 확실히 안정적입니다.
-
Digdag

- Digdag는 워크플로우의 정의를 설정 파일로 하고 있습니다. Embulk와 임의의 셸스크립트에 임의의 변수를 넣어가며 , 의존 관계순으로 직렬 및 병렬 처리로 Job을 실행할 수 있습니다.
- 워크플로우관리 도구로서 ETL 처리의 자동화에 도움이 됩니다.
- 여러 단계에서의 처리의 의존관계와 순서, 병렬실행 등을 프로그램 가능한 YAML 설정 파일을 통해 제어할 수 있는 아키텍처
- 여러 개의 데이터소스로부터 병렬 또는 직렬로 데이터를 읽고, 날짜별로 테이블을 만들고 저장하며 지속적인 1차 집계를 한 뒤에 그 결과를 저장하는 처리를 직관적으로 설정 파일에 설정할 수 있습니다.
- 기본기능
- 작업을 의존관계순으로 실행
- 과거분의 일괄실행(backfill)
- 정기 실행
- 시간 등의 변수를 포함해서 실행
- 파일이 생성되면 실행
- 에러처리
- 실패하면 통지
- 실패한 위치에서 재시작
- 상태 감시
- 실행 시간이 일정 이상이면 통지
- 작업의 실행시간의 시각화
- 실행 로그의 수집과 저장
- 고속화
- 작업을 병렬로 실행
- 동시 실행 작업 개수의 제어
- 개발지원
- 워크플로우의 버전 관리
- GUI로 워크플로우 개발
- 정기처리를 간단하게 실행할 수 있는 라이브러리
- Docker 이미지를 사용해서 작업 실행
- Digdag에는 스케줄러를 내장하고 있어서 데몬으로 동작하는 서버 모드와 커맨드라인에서 임의로 실행하는 로컬 모드의 2가지가 있습니다. 서버 모드에서는 기밀 정보와 폴리시 파일을 커맨드라인으로 등록합니다.
- Digdag을 실행하는 커맨드
- digdag run stage1_load_assets.dig
- 병렬 실행 수의 상한을 설정하여 Digdag의 워크플로우를 실행합니다.
- digdag run example.dig --max-task-threads 4
- 편리한 오퍼레이터
- 파일이 나타날 때까지 계속하는 s3_wait>:와 gcs_wait>:라는 오퍼레이터
- AWS S3에 파일이 생성될 때까지 기다렸다가 생기면 다음 태스크로 가서 Redshift에서 가져오는 Digdag의 설정. BigQuery에서 가져오는 것도 bq_load>: 오퍼레이터를 사용하여 만들 수 있습니다.
- rb>: 오퍼레이터와 py>: 오퍼레이털르 사용하면 데이터를 읽는 것 외에도 데이터의 가공도 할 수 있습니다.
$ cat tasks/__init__.py
# coding:utf-8
import digdag
import pandas as pd
class Convert(object):
def __init(self):
pass
def transform(self, session_time = None, query_result=' 0'):
input = pd.read_csv(digdag.env.params['input_csv']
user_info = pd.read_csv(digdag.env.params['user_info']))
combined = pd.merge(input, user_info, how='left', on=['id'])
combined.to_csv(digdag.env.params['output_csv'], index=False, encoding='utf-8')
# Python으로 데이터 가공 처리를 하는 예제
$ cat conver_csv.dig
_export :
input_csv: path/to/input.csv
output_csv: path/to/output.csv
user_info: path/to/users.csv
td:
database: www_access
+extract:
td>: queries/sample_query.sql
download_file: ${input_csv}
+transform:
py>: Convert.transform
+load:
# 남은 csv 파일을 전송함(Embulk 설정은 생략)
sh>: embulk run embulk_load_csv_bigquery.yml.liquidReference
'Data Engeneering > Data Ingestion' 카테고리의 다른 글
| embulk 코드 (0) | 2023.04.26 |
|---|---|
| CDC - 변경 데이터 캡처 (0) | 2023.03.09 |
| 이진로그 - binary log(binlog) (0) | 2023.03.07 |
