실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/Batch%20Processing/hive_format.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
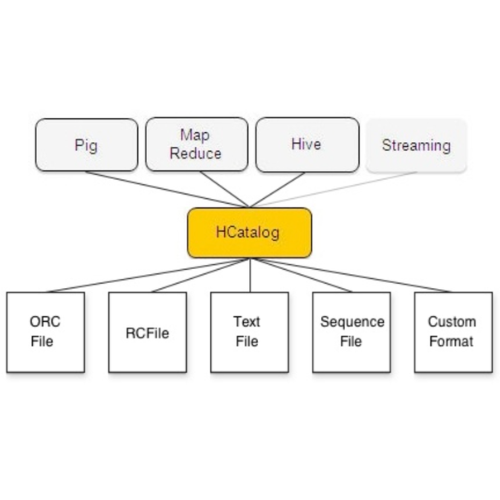
저장 포맷
- 하이브는 두 개의 차원, 즉 로우 포맷과 파일 포맷으로 테이블 저장소를 관리합니다.
- 로우 포맷은 행과 특정 행의 필드가 저장된 방식을 지시합니다. 직렬자-역직렬자(Serializer-Deserializer)를 혼합한 하이브 전문 용어인 SerDe로 정의됩니다.
- 테이블을 질의하는 경우와 같이 역직렬화를 수행할 때 SerDe는 파일에 저장된 바이트의 데이터행을 하이브에서 내부적으로 사용되는 객체로 역직렬화하여 그 데이터에 대한 연산을 수행합니다.
- 사용자 정의 함수(UDF), 사용자 정의 집계 함수(user-defined aggregate function - UDAF), 사용자 정의 테이블 생성 함수(user-defined table-generating function - UDTF) 등 세 종류의 UDF를 지원합니다. 세 종류의 차이점은 입력으로 받는 행과 출력되는 행의 개수가 다르다는 것입니다.
- 정규 UDF는 단일 행을 처리한 후 단일 행을 출력하며 수학 함수나 문자열 함수와 같은 대부분의 함수가 여기에 해당합니다.
- UDAF는 다수의 입력 행을 처리한 후 단일 행을 출력하며 COUNT나 MAX 같은 집계 함수가 여기에 해당합니다.
- UDTF는 단일 로우를 처리한 후 다수의 행(테이블)을 출력함합니다.
Text File
- 텍스트 파일 포맷은 피그나 grep, sed, awk와 같은 유닉스 텍스트 도구 등과 데이터를 공유하기 편리합니다. 파일의 내용을 직접 보고 수정하기 쉬웁니다.
- 텍스트 포맷은 바이너리 포맷과 비교하면 저장 공간을 효과적으로 사용하지는 못합니다. 압축을 사용할 수도 있지만 바이너리 포맷을 사용함으로써 텍스트 포맷보다 더 향상된 디스크 I/O와 효과적인 디스크 공간 사용합니다.
SequenceFile
- 시퀀스파일은 바이너리 키-값으로 구성된 플랫 파일(flat file - 계층적 구조를 갖지 않고 단순히 같은 형식의 레코드의 모임으로 이루어졌습니다). 하이브는 쿼리를 맵리듀스 잡으로 변환할 때 레코드로 사용하기 위한 적당한 키-값 쌍을 정합니다.
- 시퀀스파일은 블록과 레코드 수준에서 압축이 가능하므로 디스크 공간 활용과 I/O를 최적화할 수 있고 병렬 처리를 위한 블록 단위 파일 분할도 가능합니다.


- 하둡이 지원하는 시퀀스파일 포맷은 파일을 블록으로 나눌 수 있고 선택적으로 블록을 압축할 수 있습니다. CREATE TABLE 절에 STORED AS SEQUENCEFILE 절을 추가하면 됩니다.
- No compression은 데이터를 압축하지 않고 그대로 저장하는 방식입니다. 이 방식은 압축 방식을 사용하지 않으므로 디스크 공간을 적게 사용합니다. 그러나, 큰 파일을 처리할 때 입출력 속도가 느려질 수 있습니다.
- Record compression은 데이터의 각 레코드(키-값 쌍)를 압축하는 방식입니다. 이 방식을 사용하면 데이터의 크기가 줄어들어 디스크 공간을 절약할 수 있습니다. Record compression은 deflate, gzip, bzip2 등의 압축 방식을 지원합니다.
- Block compression은 데이터를 블록 단위로 압축하는 방식입니다. 이 방식은 Record compression과 달리 데이터를 블록 단위로 처리하므로 블록 단위로 입출력이 수행되어 처리 속도가 빨라집니다. Block compression은 deflate, gzip, bzip2, LZO, Snappy 등의 압축 방식을 지원합니다.
RCFile

- Hive의 Record Columnar File은 먼저 데이터를 행 단위로 Row Group으로 나누고 Row Group 내부에 데이터를 열로 저장하는 형식의 파일로 MapReduce 기반 데이터 웨어하우스 시스템용으로 설계된 데이터 배치 구조입니다
- RCFile은 행 저장소와 열 저장소의 장점을 결합하여 빠른 데이터 로드 및 쿼리 처리, 스토리지 공간의 효율적인 사용 및 매우 동적인 워크로드 패턴에 대한 적응성에 대한 요구를 충족합니다.
- 대부분 하둡과 하이브 저장 공간은 로우 기반이며 이는 대부분 효과적입니다. 파일의 블록 단위 압축은 반복되는 데이터를 다루는 데 효율적이고 로우 기반의 데이터를 잘 다룰 수 있는 여러 텍스트 처리 도구나 디버깅 도구(more, head, awk)와 잘 맞습니다.
- 테이블이 수백 개의 칼럼을 가지고 있고 대부분 쿼리에서 그중 몇 개만 사용한다면 데이터를 가지고 오기 위해 전체 로우를 스캔하는 방식은 낭비입니다. 대신에 데이터가 컬럼을 기준으로 저장되어 있다면 필요한 데이터 컬럼만 읽을 수 있기 때문에 성능이 향상될 것입니다.
- 하이브의 강력한 장점 중 하나는 서로 다른 두 데이터 포맷을 간단히 변환하는 능력으로 저장 정보는 테이블의 메타데이터에 저장합니다.
- 행 지향

- 열 지향

Avro Files

- 원격 프로시저 호출 및 데이터 직렬화 프레임워크입니다.
- Apache의 Hadoop 프로젝트 내에서 개발되었으며 JSON을 사용하여 데이터 유형 및 프로토콜을 정의하고 데이터를 간단한 이진 형식으로 직렬화합니다
ORC Files

- 열 형식으로 저장된 행 데이터와 함께 하나의 파일에 행 모음을 저장합니다
- 클러스터 전체에서 행 모음을 병렬로 처리할 수 있습니다. 열 레이아웃이 있는 각 파일은 압축에 최적화되어 있습니다.
- 데이터와 열을 건너뛰면 읽기 및 압축 해제 로드가 모두 줄어듭니다.
Parquet

- Hadoop용 오픈 소스 열 지향 스토리지 형식입니다.
- Parquet는 복잡한 데이터를 대량으로 작업하도록 최적화되어 있으며 효율적인 데이터 압축 및 인코딩 유형을 위한 방법을 포함합니다.
ORC, Parquet 및 Avro의 품질
| ORC | Parquet | Avro | |
| Row or column | Column | Column | Row |
| Compression | Great | Great | Good |
| Speedup (compared to text file) | 10–100x | 10–100x | 10x |
| Schema evolution | Good | Better | Best |
| Platforms | Hive, Spark, Presto | Hive, Spark, Presto | Hive, Spark |
| Splittability | Best | Best | Better |
| File statistics | Yes | Yes | No |
| Indexes | Yes | Yes | No |
| Bloom filters | Yes | No | No |
Custom INPUTFORMAT and OUTPUTFORMAT
- 하이브는 하둡의 입력 포맷(InputFormat) API를 이용해 텍스트 파일, 시퀀스파일, 사용자 정의 파일과 같은 다양한 소스로부터 데이터를 읽습니다. 출력 포맷(OutputFormat) API를 이용하면 다양한 포맷으로 데이터를 쓸 수도 있습니다.
- 입력 포맷(Input Format)은 주로 파일 형태의 입력 스트림을 레코드 단위로 분할되는 방법을 결정합니다. SerDe는 레코드를 컬럼 단위로 분석하고 커스텀 입력 포맷은 INPUTFORMAT 문을 이용해 테이블을 생성할 때 선언할 수 있습니다. 기본 STORED AS TEXTFILE 명세의 입력 포맷은 org.apache.hadoop.mapreduce.lib.input.TextInputFormat으로 자바 객체로 구현되어 있습니다.
- 출력 포맷(Output Format)은 출력 스트림(보통은 파일)에 어떻게 레코드를 기록하는지 결정합니다. SerDe는 개별 레코드를 적절한 바이트 스트림으로 직렬화하고 사용자 정의 출력 포맷은 OUTPUTFORMAT문을 이용해 테이블을 생성할 때 선언할 수 있습니다.
Reference
'Data Engeneering > hive' 카테고리의 다른 글
| hiveQL (0) | 2023.03.01 |
|---|---|
| hive 아키텍처 (0) | 2023.02.28 |
| hive (0) | 2023.02.27 |
