실무에 사용한 데이터 엔지니어링 스킬에 대한 정리내용입니다.
개인적인 기록을 위해 작성하였습니다.
https://github.com/mjs1995/muse-data-engineer/blob/main/doc/workflow/airflow_architecture.md
GitHub - mjs1995/muse-data-engineer: 데이터 엔지니어로 성장하기
데이터 엔지니어로 성장하기. Contribute to mjs1995/muse-data-engineer development by creating an account on GitHub.
github.com
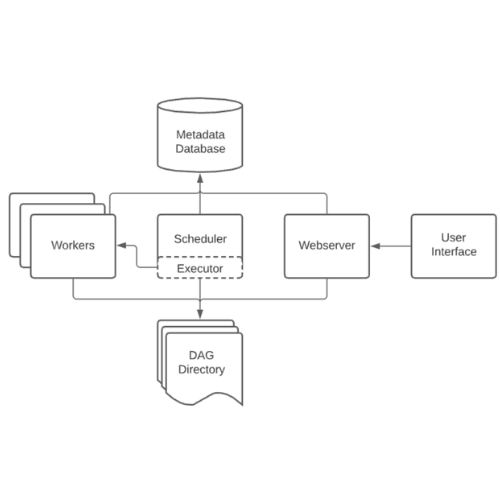
아키텍처

Airflow는 크게 다음과 같은 컴포넌트들로 구성되어 있습니다.
DAG Directory
- 파이썬으로 작성된 DAG 파일을 저장하는 공간입니다.
- DAG 파일을 저장하는 공간입니다. dag_folder 혹은 dags_folder 로도 불립니다. 기본적으로 $AIRFLOW_HOME/dags/ 가 DAG Directory로 설정되어 있습니다.
Scheduler
- DAG를 분석하고 현재 시점에서 DAG의 스케줄이 지난 경우 Airflow 워커에 DAG의 태스크를 예약합니다.
- Airflow의 가장 중요한 부분으로, 다양한 DAG Run과 Task들을 스케쥴링 및 오케스트레이션 합니다.
- 또한 하나의 DAG Run이 전체 시스템을 압도하지 않도록 각 DAG Run의 실행 횟수를 제한하기도 합니다.
- DAG 파일 구문 분석, 즉 DAG 파일 읽기, 비트 및 조각 추출, 메타 스토어에 저장합니다.
- 실행할 태스크를 결정하고 이러한 태스크를 대기열에 배치합니다.
- Scheduler는 DAG 파일을 파싱하고, 모든 Task와 DAG들을 모니터링하며, Task Instance와 Dag Run들의 스케줄링 및 오케스트레이션을 담당합니다
- Dag Directory에서 파일을 처리하고 결과를 얻는 일
- DAG Run과 Task Instance의 상태를 변경하고 Executor가 실행시킬 큐에 Task Instance를 넣는 일
- Executor로 스케줄링 큐에 들어온 Task를 실행시키는 일
- Scheduler는 DAG 파일을 파싱하고, 모든 Task와 DAG들을 모니터링하며, Task Instance와 Dag Run들의 스케줄링 및 오케스트레이션을 담당합니다
- Meta Database에 DAG 정보 및 DAG Run에 대해 저장합니다.
- 스케줄러의 여러 가지 역할
- DAG 파일을 구문 분석하고 추출된 정보를 데이터베이스에 저장
- 실행할 준비가 된 태스크를 결정하고 이를 대기 상태로 전환
- 대기 상태에서 태스크 가져오기 및 실행
- SchedulerJob의 역할
- DAG 파일을 파싱하고 추출된 정보를 데이터베이스에 저장하는 역할을 수행합니다.
- DAG 프로세서 : Airflow 스케줄러는 DAG 디렉터리(AIRFLOW__CORE__DAGS__FOLDER에서 설정한 디렉터리)의 파이썬 파일을 주기적으로 처리합니다.
- 태스크 스케줄러 : 스케줄러는 실행할 태스크 인스턴스를 결정하는 역할을 합니다.
Executor
- Scheduler 내부의 구성 요소입니다.
- Scheduler가 작업을 조정하는 동안 Executor는 실제로 작업을 실행합니다.
- Sequential, Local, Celery, Kubernetes 등 Executor에는 여러 종류가 있습니다. (기본 값은 Sequential Executor입니다.)
- 워크로드를 여러 머신에 분산하려는 경우 CeleryExecutor 및 KubernetesExecutor의 두 가지 옵션 존재하고 단일 시스템의 리소스 제한에 도달하거나 여러 시스템에서 태스크를 실행하여 병렬 실행을 원하거나 태스크를 여러 시스템에 분산하여 작업 속도를 더 빠르게 실행하고자 할 때 사용할 수 있습니다.
- Executor는 Scheduler에서 생성하는 서브 프로세스로 Queue에 들어온 Task Instance를 실제로 실행하는 역할을 합니다.
- Local Executors : Task Instance를 Scheduler 프로세스 내부에서 실행합니다.
- Sequential Executor
- Airflow 익스큐터 중 가장 단순하게 구성할 수 있는 방법이자, Airflow를 별도의 설정이나 환경 구성 없이 바로 실행시킬 수 있는 방법입니다.
- 태스크를 순차적으로 하도록(한 번에 하나씩) 구성되어 있습니다,
- 주로 테스트 및 데모 목적으로 사용되는 쪽으로 많이 선호합니다.
- 작업 처리 속도가 상대적으로 느리며 단일 호스트 환경에서만 작동합니다.
- Local Executor
- 한 번에 하나의 태스크로 제한되지 않고 여러 태스크로 병렬로 실행할 수 있습니다.
- 익스큐터 내부적으로 워커 프로세스가 FIFO(First in, First out) 적용 방식을 통해 대기열에서 실행할 태스크를 등록합니다.
- 기본적으로 최대 32개의 병렬 프로세스를 실행합니다.
- Sequential Executor
- Remote Executors : Task Instance를 Scheduler 프로세스 외부에서 실행합니다.
- Celery Executor

- Celery Executor
- 내부적으로 Celery를 이용하여 실행할 태스크들에 대해 대기열을 등록합니다.
- 워커가 대기열에 등록된 태스크를 읽어와 개별적으로 처리합니다.
- 사용자 관점에서 볼 때 태스크를 대기열로 보내고 워커가 대기열에서 처리할 태스크를 개별적으로 읽어와 처리하는 과정은 LocalExecutor와 유사합니다.
- LocalExecutor와 가장 큰 차이점은 모든 구성요소가 서로 다른 호스트에서 실행되기 때문에 작업 자체에 대한 부하가 LocalExecutor에 비해 낮습니다.
- Celery는 대기열 메커니즘(Celery에서 처리할 때는 Broker라고 지칭)을 위해 RabbitMQ, Redis 또는 AWS SQS를 지원합니다.
- 멀티스레드 싱클톤(singleton) 스케줄러 서비스를 구현합니다. 작업을 호출하는 메시지는 RabbitMQ 또는 Redis 데이터베이스에서 대기열에 추가되고 작업은 여러 Celery 작업자에게 분배됩니다.
- Celery의 모니터링을 위해 Flower라는 모니터링 도구를 함께 제공합니다.
- Celery는 파이썬 라이브러리 형태로 제공되므로 Airflow 환경에 적용하기 편리합니다.
- Kubernetes Executor
-

https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/executor/kubernetes.html 
https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/executor/kubernetes.html - 쿠버네티스에서 워크로드를 실행합니다.
- Airflow를 실행하려면 쿠버네티스 클러스터의 설정 및 구성이 필요하며 익스큐터는 Airflow 태스크를 배포하기 위해 쿠버네티스 API와 통합됩니다.
- 쿠버네티스는 컨테이너화된 워크로드를 실행하기 위한 사실상의 표준 솔루션 입니다.
-
- Airflow에서는 익스큐터 유형에 따라 다양한 설치 환경을 구성할 수 있습니다.
| 익스큐터 | 분산 | 환경 설치 난이도 | 사용에 따른 적합한 황경 |
| SequentialExcutor(기본값) | 불가능 | 매우 쉬움 | 시연 / 테스트 |
| LocalExcutor | 불가능 | 쉬움 | 단일 호스트 환경 권장 |
| CeleryExecutor | 가능 | 보통 | 멀티 호스트 확장 고려 시 |
| KubernetesExecutor | 불가능 | 어려움 | 쿠버네티스 기반 컨테이너 환경 구성 고려 시 |
- 익스큐터 설치
- SequentalExecutor 설정
- 스케줄러의 태스크 오퍼레이터 부분은 단일 하위 프로세스에서 실행되고 이 단일 하위 프로세스 내에서 작업은 순차적으로 하나씩 실행되므로 익스큐터 종류 중 가장 느린 실행 방법입니다.
- 구성 절차가 필요하지 않기 때문에 테스트 시점에 매우 편리하게 사용할 수 있습니다.
- LocalExecutor 설정
- 아키텍처는 SequentialExecutor와 유사하지만, 여러 하위 프로세스가 있어 병렬로 태스크를 실행할 수 있으므로 SequentialExecutor에 비해 빠르게 수행할 수 있습니다.
- 각 하위 프로세스는 하나의 태스크를 실행할 수 있으며, 하위 프로세스는 병렬로 실행할 수 있습니다.
- 모든 구성 요소를 별도의 컴퓨터에서 실행할 수 있으며, 스케줄러에 의해 생성된 하위 프로세스는 모두 하나의 단일 시스템에서 실행됩니다.
- CeleryExecutor 설정
- Celery는 대기열 시스템을 통해 워커에게 메시지를 배포하기 위한 프레임워크를 제공합니다.
- 태스크가 Celery worker를 실행하는 여러 컴퓨터로 분배하고 워커는 태스크가 대기열에 도착할 때까지 기다립니다.
- Celery에서는 대기열을 브로커라합니다.
- Airflow webserver 실행
- Airflow scheduler 실행
- Airflow Celery worker 실행
- KubernetesExecutor 설정
- 모든 태스크가 쿠버네티스의 파드(pod)에서 실행됩니다.
- 쿠버네티스에서 웹 서버, 스케줄러 및 데이터베이스를 실행할 필요는 없지만, KubernetesExecutor를 사용할 때 쿠버네티스에서 다른 서비스들이 함께 실행되는 것이 관리하기 좀 더 수월합니다.
- 파드가 쿠버네티스에서 가장 작은 작업 단위이며 하나 이상의 컨테이너를 실행할 수 있습니다.
- 다른 익스큐터는 작업 중인 워커의 정확한 위치를 항상 알 수 있으며, 쿠버네티스를 사용하면 모든 프로세스 파드에서 실행되며, 파드는 동일한 시스템에서 실행될 수도 있지만 여러 호스트에 분산되어 실행될 수 있습니다.
- 사용자의 관점에서 볼 때 프로세스는 파드에서 실행되며 사용자는 실행하는 프로세스가 어떤 호스트에서 실행되는지 명확하게 바로 알 수는 없습니다.
- SequentalExecutor 설정
- Airflow 프로세스 간에 DAG파일을 배포하는 방법을 결정
- PersistentVolume을 사용하여 포드 간에 DAG 공유
- Git-sync init container를 사용해 리포지토리의 최신 DAG 코드 가져오기
- Docker 이미지에 DAG 빌드
Worker
- 예약된 태스크를 선택하고 실행합니다.
- Executor에 의해 만들어지며 Task를 실제로 실행하는 프로세스입니다.
- Executor의 종류에 따라 Worker는 쓰레드, 프로세스, 파드가 될 수 있습니다.
Meta Database
- DAG, 해당 실행 및 사용자, 역할 및 연결과 같은 기타 Airflow 구성에 대한 메타데이터를 저장합니다.
- Meta Database는 Airflow의 DAG, DAG Run, Task Instance, Variables, Connections 등 여러 컴포넌트에서 사용해야하는 데이터를 저장합니다. Webserver, Scheduler, Worker 모두 Meta Database와 통신하기 때문에 Meta Database는 Scheduler와 더불어 매우 중요한 컴포넌트입니다.
- Airflow를 위한 메타스토어 설정
- 메타스토어(metastore) : Airflow에서 일어나는 모든 일은 데이터베이스에 등록되며 이를 Airflow에서 칭합니다.
- 워크플로 스크립트 : 스케줄러를 통해 작업 내역을 분석 및 관리하는 역할을 수행하며 메타스토어에 그 해석된 내용을 저장하는 등의 여러 컴포넌트로 구성되어 있습니다.
- Airflow는 Python ORM(Object Relational Mapper) 프레임워크인 SQLAlchemy를 사용하여 모든 데이터베이스 태스크를 수행하며 SQL 쿼리를 수동으로 작성하는 대신, 직접 데이터베이스에 직접 편리하게 작성할 수 있습니다.
- Webserver
- 웹 서버는 파이프라인이 현재 상태에 대한 정보를 시각적으로 표시하고 사용자가 DAG 트리거와 같은 특정 태스크를 수행할 수 있도록 관리하는 역할을 수행합니다.
- 스케줄러에서 분석한 DAG를 시각화하고 DAG 실행과 결과를 확인할 수 있는 주요 인터페이스를 제공함
- Airflow의 Web UI 입니다.
- Meta Database로 부터 DAG 정보를 읽어와 DAG 정보 및 DAG Run의 상태를 확인하고 실행할 수 있습니다.
- Webserver는 Meta Database와 통신하며 DAG, DAG Runs, Task Instance, Variables, Connections 등의 데이터를 가져와 웹에서 보여주고 유저와 상호작용 할 수 있게 합니다.
- 모든 Airflow 프로세스의 로그 확인
- 웹 서버 로그 : 웹 활동에 대한 정보, 즉 웹 서버로 전송되는 요청에 대한 정보를 보관합니다.
- 스케줄러 로그 : DAG 구문분석, 예약 작업 등을 포함한 모든 스케줄러 활동에 대한 정보를 보관합니다.
- 태스크 로그 : 각 로그 파일에는 단일 태스크 인스턴스의 로그가 보관됩니다.
Dag의 구조
- DAG 명세서
- Dummy DAGS (Start, End 계열) 일부 제외
- DummyOperator는 아무 실행도 하지 않는 Operator입니다. 간혹 Task 간 의존성 흐름 내 필요한 경우에 사용됨
- ExternalTaskSensor 계열은 무조건 후속작업이 있으며, 자신이 감지하고 있는 Task가 끝날 때까지 계속 작동
- SSHOperator : 일반적인 작업 수행 DAG로 해당 Job이 끝나면 Success를 찍고 끝남
- TriggerDagOperator : 다른 DAG를 시작시키는 Trigger 역할
- BranchPythonOperator : 조건에 따라 다른 DAG를 실행해야 할 경우 어느 DAG로 분기해야 할지 DAG 명을 리턴해주는 역할
- BranchPythonOperator는 특정 조건에 따라 의존성 흐름에 분기를 줄 수 있는 Operator
- ShortCircuitOperator : BranchPythonOperator와 비슷하나 조건이 False 가 나오면 흐름을 무조건 끊고 다음 작업들을 전부 Skip 시킴
- PythonOperator : Deploy 서버 내부에서 실행되는 파이썬 코드
- BashOperator는 bash 커맨드를 실행하는 Operator
- EmailOperator는 Email을 보내는 Operator
- Custom Operator : Airflow Operator는 직접 Custom 하게 작성할 수 있음
- 파이썬 코드 실행 옵션
- PythonOperator를 사용하는 대신 BashOperator를 사용하여 파이썬 스크립트를 실행함, PythonOperator로 파이썬 코드를 실행하려면 코드를 DAG 정의 파일에 작성하거나 DAG 정의 파일로 가져와야 함, 오케스트레이션과 이 오케스트레이션이 실행하는 프로세스의 로직을 더 많이 분리하고 싶었음, 에어플로우와 내가 실행하려는 코드 간에 호환되지 않는 파이썬 라이브러리 버전의 잠재적인 문제를 피할 수 있음, 프로젝트(및 Git 저장소)를 분리하여 데이터 인프라 전반에 걸쳐 로직을 유지 관리하는 것이 더 쉬움
- Dummy DAGS (Start, End 계열) 일부 제외
- 태스크와 오퍼레이터 차이점
- 오퍼레이터(operator) : 단일 태스크를 나타냅니다.
- 단일 작업 수행 역할
- PythonOperator : 파이썬 함수를 실행하는 데 사용됨
- EmailOperator : 이메일 발송에 사용됨
- Simple HttpOperator : HTTP 엔드포인트 호출
- DAG는 오퍼레이터 집합에 대한 실행을 오케스트레이션(orchestration - 조정, 조율)하는 역할을 함, 오퍼레이터의 시작과 정지, 오퍼레이터가 완료되면 연속된 다음 태스크의 시작, 그리고 오퍼레이터 간의 의존성 보장이 포함됨
- Airflow에서 태스크는 작업의 올바른 실행을 보장하기 위한 오퍼레이터의 래퍼(wrapper) 또는 매니저(manager)로 생각해 볼 수 있음
- 사용자는 오퍼레이터를 활용해 수행할 작업에 집중할 수 있으며, Airflow는 태스크를 통해 작업을 올바르게 실행할 수 있음
- DAG와 오퍼레이터는 Airflow 사용자가 이용함, 태스크는 오퍼레이터의 상태를 관리하고 사용자에게 상태 변경(예:시작/완료)을 표시하는 Airflow의 내장 컴포넌트
- 오퍼레이터(operator) : 단일 태스크를 나타냅니다.
- 다양한 오퍼레이터를 사용할 때는 다양한 종속성을 위한 많은 모듈이 설치되어야 하기 때문에 잠재적인 충돌이 발생하고 환경 설정 및 유지 관리가 상당히 복잡해짐(많은 패키지를 설치하면 잠재적인 보안 위험은 말할 것도 없이 높아짐), 파이썬은 동일한 환경에 동일한 패키지의 여러 버전을 설치할 수 없기 때문에 문제가 됨
스케줄링
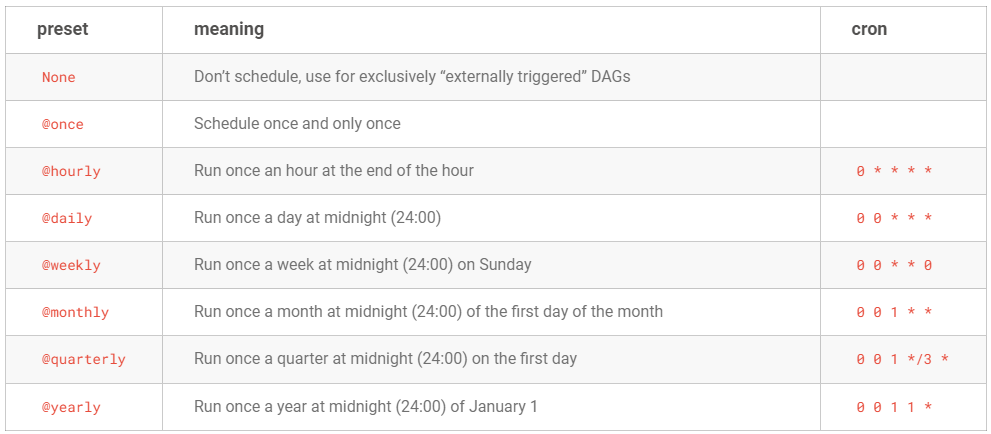
- Cron 기반의 스케줄 간격 설정하기
- 더 복잡한 스케줄 간격 설정을 지원하기 위해서 cron(macOS 및 리눅스와 같은 유닉스 기반 OS에서 사용하는 시간 기반 작업 스케줄러)과 동일한 구문을 사용해 스케줄러 간격을 정의함
- 빈도 기반의 스케줄 간격 설정하기 : timedelta(표준 라이브러리인 datatime 모듈에 포함된)인스터스를 사용하면 됨
- execution_date : DAG가 실행되는 날짜와 시간을 나타냄
- DAG를 시작하는 시간의 특정 날짜가 아니라 스케줄 간격으로 실행되는 시작 시간을 나타내는 타임스탬프
- 스케줄 간격의 종료 시간은 next_execution_date라는 매개변수를 사용
- 과거의 스케줄 간격의 시작을 정의하는 previous_execution_date 매개변수를 제공
- Airflow는 날짜 시간에 Pendulum 라이브러리를 사용하며 execution_date는 이러한 Pendulum의 datetime 객체
태스크 간 의존성 정의하기
- XCom : DAG 실행에서 서로 다른 작업 간에 데이터를 전달할 수 있음
- 다양한 태스크 의존성 패턴
- 태스크의 선형 체인(linear chain) 유형 : 연속적으로 실행되는 작업
- 팬아웃/팬인(fan-out/fan-in) 유형 : 하나의 태스크가 여러 다운스트림 태스크에 연결되거나 그 반대의 동작을 수행하는 유형
- 팬아웃 : 여러 개의 입력 태스크 연결수 제한
- 팬아웃 종속성 : 한 태스크를 여러 다운스트림 태스크에 연결하는 것
- 팬인 구조 : 하나의 태스크가 여러 업스트림 태스크에 영향을 받는 구조는 단일 다운스트림 태스크가 여러 업스트림 태스크에 의존성을 가짐
- [a , b ] >> c
워크플로 트리거
- 센서를 사용한 폴링 조건
- Airflow 오퍼레이터의 특수 타입(서브 클래스)인 센서(sensor)의 도움을 받을 수 있음
- DAG 간의 공유 종속성에 대한 필요성을 감안할 때 에어플로우 작업은 Sensor라고 하는 특별한 유형의 연산자를 구현할 수 있다, 에어플로우 Sensor는 일부 외부 작업 또는 프로세스의 상태를 확인한 다음 확인 기준이 충족되면 DAG에서 다운스트림 종속성을 계속 실행하도록 설계됨
- 두 개의 서로 다른 에어플로우 DAG를 조정해야 하는 경우 ExternalTaskSensor를 사용하여 다른 DAG의 작업 상태 또는 다른 DAG의 전체 상태를 확인할 수 있음
- 센서는 특정 조건이 true인지 지속적으로 확인하고 true라면 성공, 만약 false인 경우 센서는 상태가 true가 될 때까지 또는 타임아웃이 될 때까지 계속 확인함
- FileSensor : 파일위치에 파일이 존재하는지 확인하고 파일이 있으면 true를 반환하고, 그렇지 않으면 false를 반환한 후 해당 센서는 지정된 시간(기본값은 60초) 동안 대기했다가 다시 시도함
- Poking : 센서를 실행하고 센서 상태를 확인하기 위해 Airflow에서 사용하는 이름
- 사용자 지정 조건 폴링
- PythonSensor
- PythonOperator와 유사하게 파이썬 콜러블(callable 함수, 메서드 등)을 지원
- PythonSensor 콜러블은 성공적으로 조건이 충족됐을 경우 true를, 실패했을 경우 false로 부울(Boolean) 값을 반환하는 것으로 제한됨
- PythonSensor
- 센서 데드록 : 실해중인 태스크 조건이 true가 될 때까지 다른 태스크가 대기하게 되므로 모든 슬롯이 데드록 상태가 됨
- TriggerDagRunOperator : 워크플로가 분리된 경우 이 오퍼레이터를 통해 다른 DAG를 트리거할 수 있음
- DAG에서 태스크를 삭제하면 이전에 트리거 된 해당 DAG 실행을 지우는 대신에 새 DAG 실행이 트리거 됨
- 다른 DAG의 상태를 폴링 하기
- ExternalTaskSensor : 다른 DAG의 태스크를 지정하여 해당 태스크의 상태를 확인하는 것
Reference
'Data Engeneering > workflow' 카테고리의 다른 글
| Prefect 개요 (0) | 2023.04.26 |
|---|---|
| dbt(Data Build Tool) 개요 (0) | 2023.04.26 |
| Aiflow 개요 (0) | 2023.01.18 |
